MVSNeRF:多视图立体视觉的快速推广辐射场重建(2021年)
Anpei Chen and Zexiang Xu and Fuqiang Zhao et al. MVSNeRF: Fast Generalizable Radiance Field Reconstruction from Multi-View Stereo[J]. arXiv:2103.15595v2, 2021. https://doi.org/10.48550/arXiv.2103.15595
source code
摘要
在2021年,作者提出了MVSNeRF,一种新的神经渲染方法,在视图合成中可以有效地重建神经辐射场。与之前对神经辐射场的研究不同,我们考虑了对密集捕获的图像进行每场景优化,我们提出了一种通用的深度神经网络,它可以通过快速网络推理,仅从附近的三个输入视图中重建辐射场。我们的方法利用平面扫描代价体(广泛应用于多视图立体视觉)进行几何感知场景推理,并将其与基于物理的体积渲染相结合,用于神经辐射场重建。我们在DTU数据集中的真实物体上训练我们的网络,并在三个不同的数据集上进行测试,以评估其有效性和通用性。我们的方法可以泛化跨场景(甚至是室内场景,完全不同于我们物体的训练场景),并仅使用三个输入图像生成真实的视图合成结果,显著优于同时发布的可推广的辐射场重建论文。此外,如果捕获密集的图像,我们估计的辐射场表示可以很容易地进行微调;这导致每个场景可以快速的重建,具有更高的渲染质量和更少的优化时间。
1 引言
新视角合成是计算机视觉和图形学中一个长期存在的问题。近年来,神经渲染方法显著地推进了这一领域的进展。神经辐射场( Neural Radiance Fields,NeRF)及其后续的工作已经可以产生逼真的新视图合成结果。然而,这些先前工作的一个显著缺点是它们需要一个很长的每一个场景的优化过程来获得高质量的辐射场,这相当昂贵并高度限制了实用性。
我们的目标是让神经场景重建和渲染更加实用。我们提出了MVSNeRF,一种新的方法,可以很好地推广到仅从几个(只有三个)非结构化的多视图输入图像中跨场景重建一个辐射场的任务。由于具有很强的通用性,我们避免了繁琐的每个场景优化,并可以通过快速的网络推理直接在新的视角上回归真实的图像。如果在短时间内(5-15 min)进一步优化更多图像,我们重建的辐射场甚至可以在数小时的优化下优于NeRFs(见图1)。

我们利用了最近在基于学习的多视点立体视觉(MVS)上的成功。对于三维重建任务,这项工作可以通过对代价体使用用三维卷积来训练可推广的神经网络。我们通过将附近的输入视图(由2DCNN推断)的二维图像特征变换到参考视图的结果中的扫描平面上,在输入参考视图上构建一个代价体。与其它MVS方法只对代价体进行深度推断不同,我们的网络对场景几何和外观进行推理,并输出一个神经辐射场(见图2),从而实现视图合成。
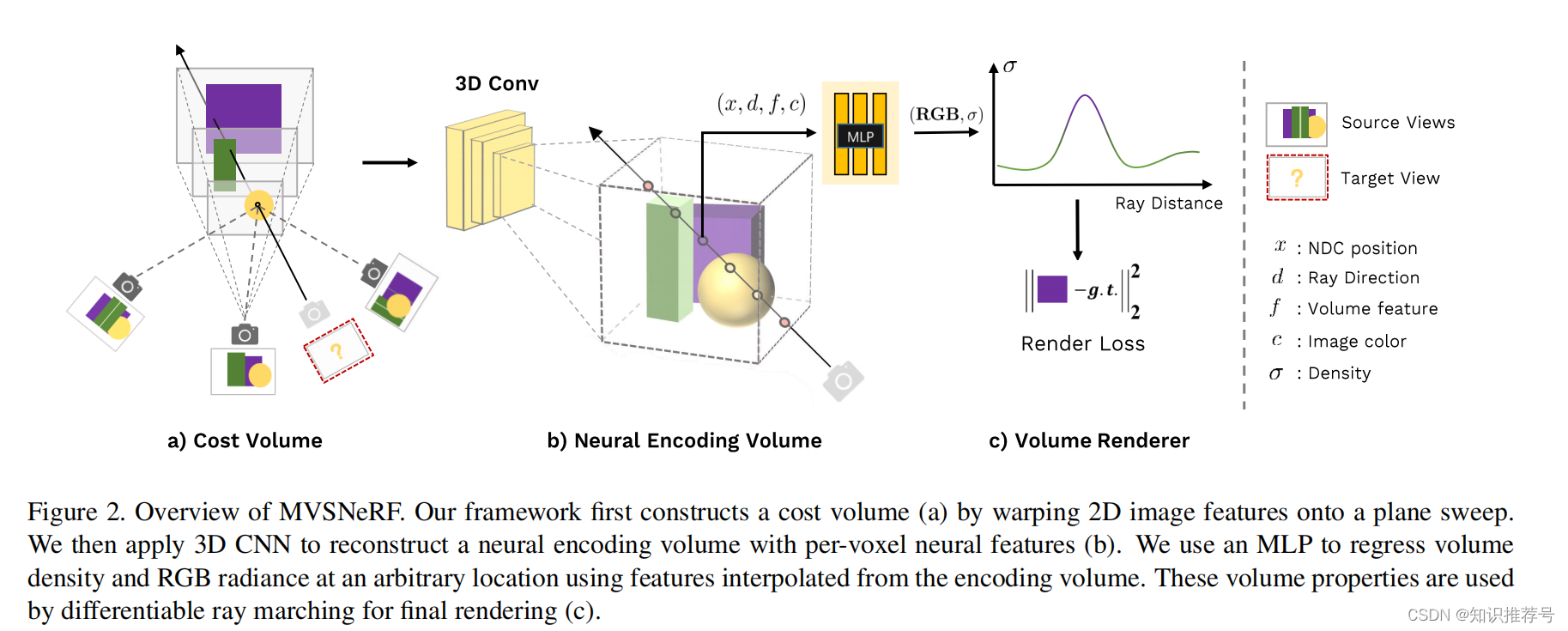
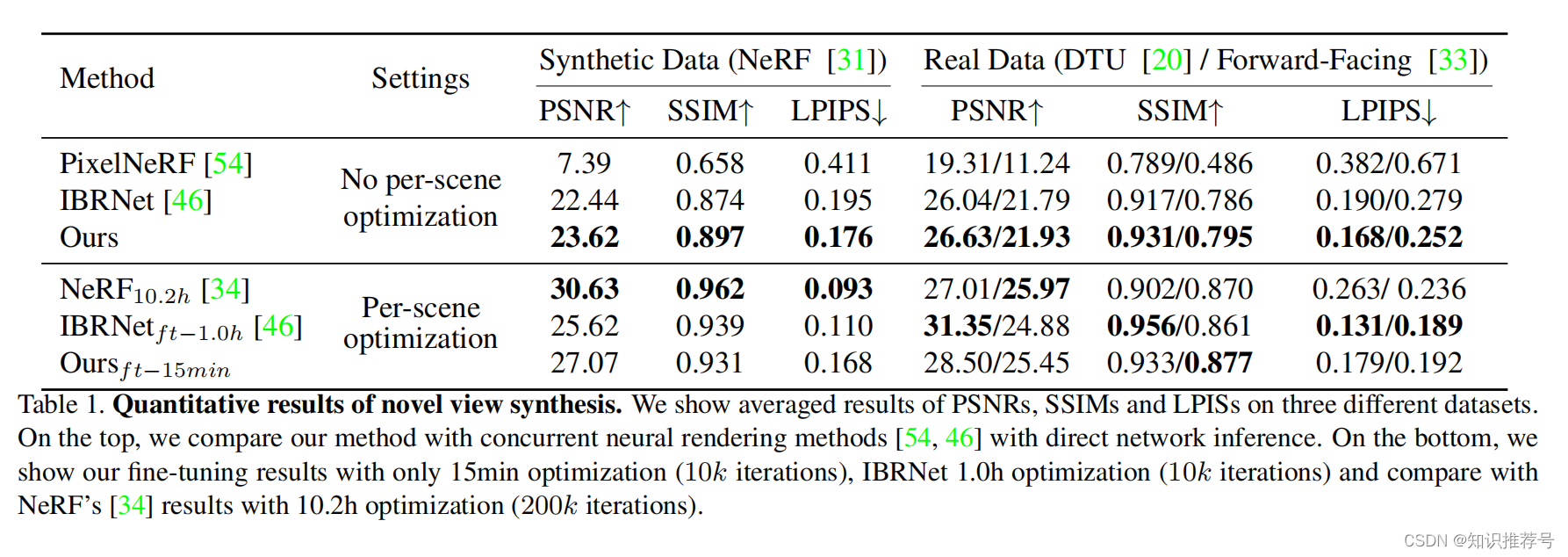
具体来说,利用3D CNN,我们重建(从代价体)一个神经场景编码体,该体积由每个体素的神经特征组成,编码关于局部场景几何和外观的信息。然后,我们利用多层感知器(MLP),利用编码体内的三次插值神经特征,解码任意连续位置的体积密度和辐射。本质上,编码体是辐射场的局部神经表示;一旦估计,这个体积可以直接使用(去掉3D CNN),通过可微分射线行进行最终渲染。我们的方法结合了基于学习的MVS和神经渲染。与现有的MVS方法相比,我们实现了可微神经渲染,允许在不需要三维监督的情况下进行训练和推理时间优化,以进一步提高质量。与现有的神经渲染工作相比,我们的MVS架构可以很自然地推理相应的交叉视图,促进泛化到不可见的测试场景,也可以导致更好的神经场景重建和渲染。因此,我们的方法可以显著优于最近的发布的可推广的NeRF工作,它主要考虑二维图像特征,而没有显式的几何感知的三维结构(见表1和图4)。
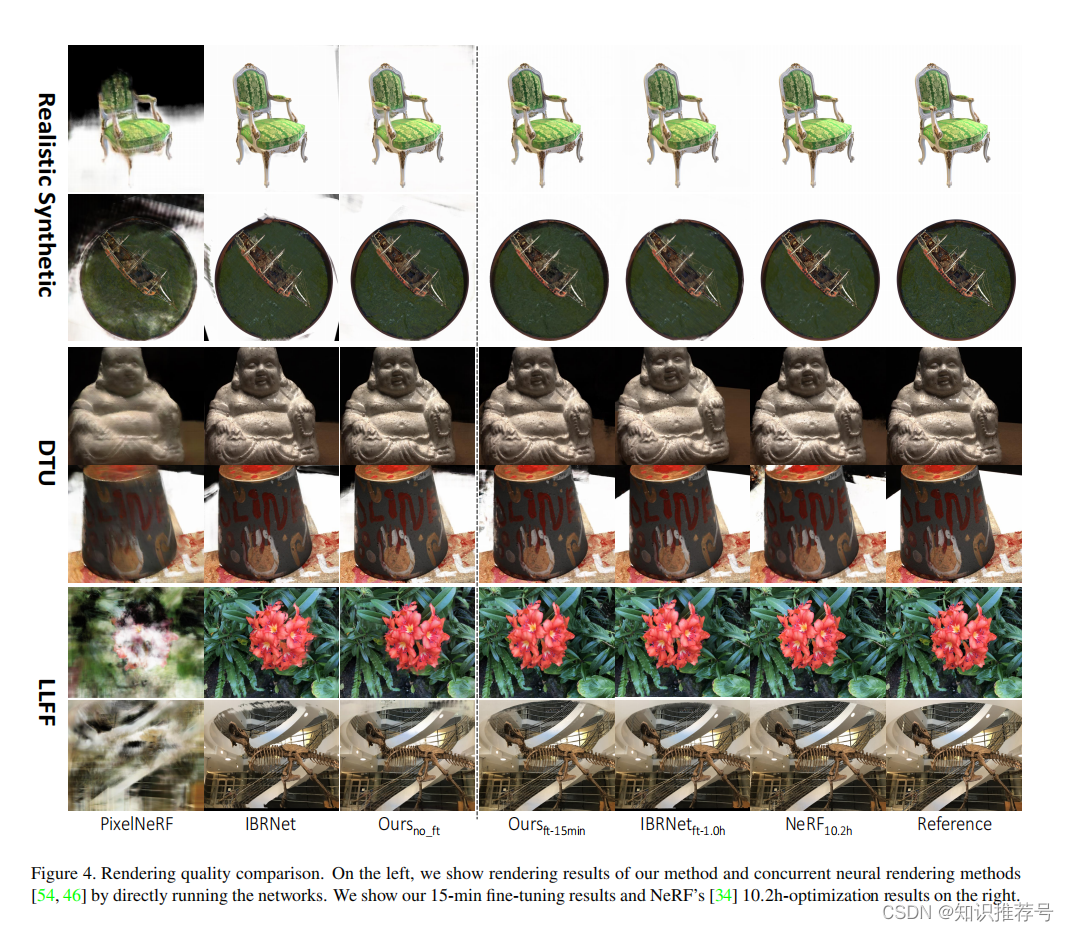
我们证明,仅使用3张输入图像,我们从DTU数据集训练出来的网络在测试DTU场景时合成逼真的图像,甚至可以在其它分布不同的场景数据集上产生合理的结果。此外,我们估计的三图像辐射场(神经编码体)可以更容易地在新的测试场景上进一步优化,以改进更多被拍摄图像的神经重建,获得了逼真的结果,甚至与每个场景的过拟合NeRF相当,我们的优化时间比NeRF少(见图1)。这些实验表明,当只有少数图像捕获时,我们的技术可以作为一个强有力的重建器,可以重建一个辐射场用于真实的视图合成。或者作为一个强初始化器,当获得密集图像时,可以显著促进每个场景的辐射场优化。我们的方法向现实的神经渲染实际化迈出了重要的一步。
2 相关工作
多视图立体视觉
多视图立体视觉(MVS)是一个经典的计算机视觉问题,旨在利用从多个视点捕获的图像来实现密集的几何重建,并已被各种传统方法广泛探索。最近,深度学习技术被引入来解决MVS问题。MVSNet在参考视图的平面扫描代价体上应用三维CNN进行深度估计,实现了优于经典传统方法的高质量的三维重建。随后的工作将该技术扩展为循环平面扫扫、基于点的致密化、基于置信度的聚合和多代价体,提高了重建质量。我们提出将基于代价体的深度MVS技术与可微分体渲染相结合,使其能够有效地重建神经渲染的辐射场。与使用直接深度监督的MVS方法不同,我们只训练具有图像损失的网络,用于新的视图合成。这确保了网络满足多视图的一致性,同时允许高质量的几何重建。此外,我们的MVSNeRF可以实现与MVSNet相比的精确的深度重建(尽管没有直接的深度监督),这可能会激发未来开发无监督几何重建方法的工作。
视角合成
视图合成已经用各种方法研究了几十年,包括光场,基于图像的渲染,以及其他最近基于深度学习的方法。平面扫描体积也被用于视图合成。通过深度学习,基于MPI的方法在参考视图上构建平面扫描体,而其它方法在新的视角上构建平面扫描;这些先前的工作通常预测离散扫描平面上的颜色,并使用alpha混合或基于学习的权重预测和聚合每个平面的颜色。我们的方法不是直接的预测每个平面颜色,而是将平面扫描中的每个体素神经特征作为场景编码体进行推断,并可以从任意的三维位置回归体渲染属性。这是一个连续的神经辐射场的模型,允许基于物理的体素渲染来实现现实的视图合成。
神经渲染
近年来,各种神经场景表示法被提出来实现视图合成和几何重建任务。特别是,NeRF 结合了MLP与可微分的体积渲染,并实现了逼真的视图合成。有些工作试图提高其在视图合成上的性能;其它相关工作扩展到支持其他神经渲染任务,如动态视图合成,挑战场景,姿态估计,实时渲染,重光照,和剪辑。然而,大多数之前的工作仍然遵循原始的NeRF,并需要对每个场景进行昂贵的优化过程。相反,我们利用深度MVS技术来实现跨场景神经辐射场估计,仅使用少量图像作为输入。我们的方法利用平面扫描三维代价体来实现几何感知场景理解,比同时发布的工作要显著提高辐射场重建的性能。
3 MVSNeRF实现方法
与NeRF通过每个场景的“网络记忆”来重建辐射场不同,我们的MVSNeRF学习了一个用于辐射场重建的通用网络。输入 M M M张真实场景拍摄的图片 I i ( i = 1 , . . , M ) I_i (i = 1, .., M) Ii(i=1,..,M)并且知道相机参数 Φ i Φi Φi,我们提出了一种新的网络,它可以重建一个辐射场作为一个神经编码体,并使用它来回归体渲染属性(密度和具有视图依赖的辐射)用于视图合成。一般来说,我们的整个网络可以看作是一个辐射场的函数,表示为:
σ , r = MVSNeRF ( x , d ; I i , Φ i ) ( 1 ) \sigma , r = \text {MVSNeRF}(x,d;I_i,\Phi _i)~~~~(1) σ,r=MVSNeRF(x,d;Ii,Φi) (1)
其中 x x x表示一个3D位置, d d d是视角方向, σ σ σ是 x x x处的体积密度, r r r是 x x x处的输出辐射(RGB颜色),这取决于视角方向 d d d。我们网络的输出体积特性可以直接通过可微分射线在新的目标视角 Φ t Φ_t Φt上合成新的图像 I t I_t It。
在本文中,我们考虑一个稀疏的附近输入视图集来有效地辐射场重建。在实践中,我们使用 M = 3 M = 3 M=3视图来进行实验,而我们的方法可以处理非结构化视图,并且可以很容易地支持其它数量的输入。我们的MVSNeRF的概述如图2所示。
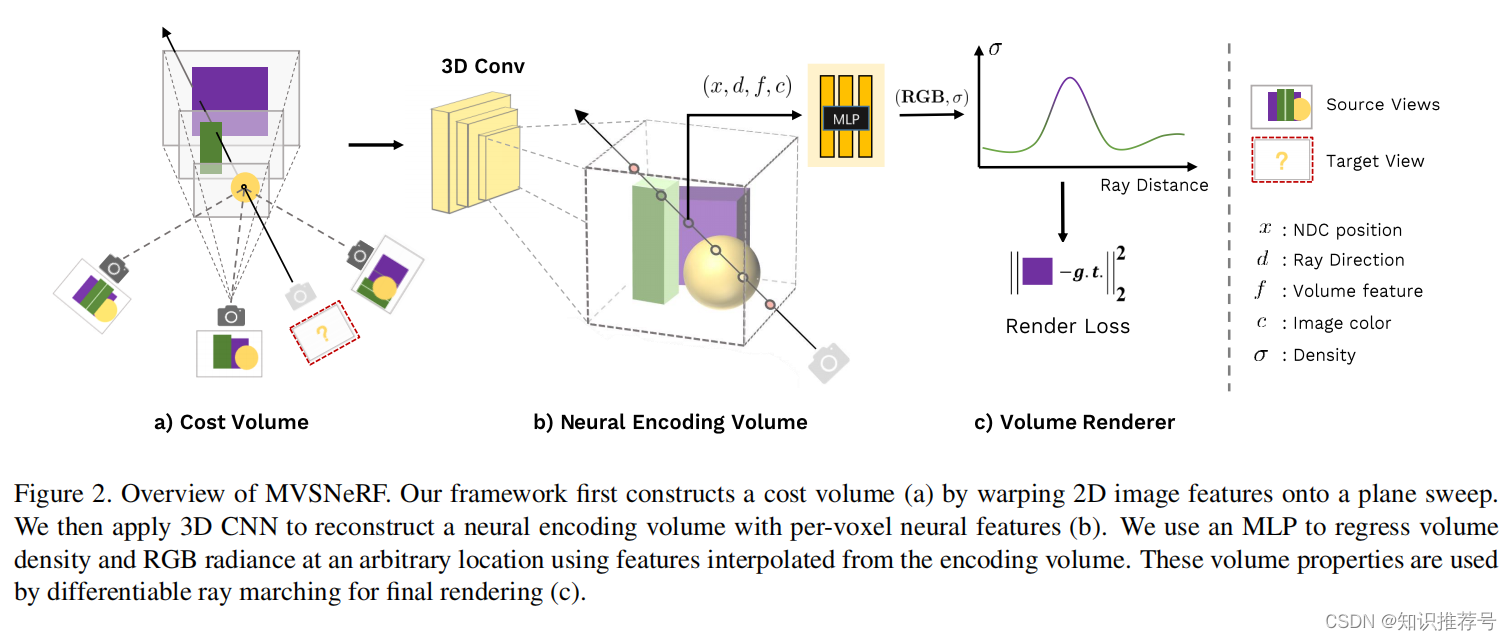
我们首先在参考视图(我们将视图i = 1称为参考视图)上,将二维神经特征变换到多个扫描平面上。然后,我们利用一个3D CNN来重建神经编码体,并使用一个MLP来回归体渲染属性,表示一个辐射场。我们利用可微的射线行进,使用我们的网络建模的辐射场,在新的视点上回归图像;这使得我们的整个框架使用渲染损失实现了端到端训练。我们的框架实现了从少量图像的辐射场重建。另一方面,当捕获密集图像时,重建的编码体和MLP解码器也可以进行快速独立微调,以进一步提高渲染质量。
3.1 构建代价体
受最近的深度MVS方法的启发,我们在参考视图(i = 1)处构建了一个代价体P,允许对几何感知的场景进行理解。这成功利用二维图像特征从m个输入图像变换到参考视图的结果上的平面扫描体来实现。
提取图像特征
我们使用深度二维CNN T在单个输入视图上提取二维图像特征,从而有效地提取代表局部图像外观的二维神经特征。该子网络由下采样卷积层组成,并将输入图像 I i ∈ R H i × W i × 3 I_i∈\mathbb{R}^{H_i×W_i×3} Ii∈RHi×Wi×3转换为2D特征地图 F i ∈ R H i / 4 × W i / 4 × C F_i∈\mathbb{R} ^{H_i/4×W_i/4×C} Fi∈RHi/4×Wi/4×C,
F i = T ( I i ) ( 2 ) F_i = T(I_i)~~~~(2) Fi=T(Ii) (2)
其中,H和W为图像的高度和宽度,C为所得到的特征通道数。
变换特征图
给定相机的内在和外在参数 Φ = [ K , R , t ] Φ = [K,R,t] Φ=[K,R,t],我们考虑了单应性变换:
H i ( z ) = K i ⋅ ( R i ⋅ R 1 T + ( t 1 − t i ) ⋅ n 1 T z ) ⋅ K 1 − 1 ( 3 ) H_i(z)=K_i·(R_i·R_1^T+ \frac{(t_1-t_i)·n_1^T}{z} )·K_1^{-1}~~~~(3) Hi(z)=Ki⋅(Ri⋅R1T+z(t1−ti)⋅n1T)⋅K1−1 (3)
其中 H i ( z ) H_i (z) Hi(z)是在深度z从视图i到参考视图的矩阵变换,K是内参矩阵,R和t是相机的旋转和平移。每个特征图 F i F_i Fi可以通过以下方式变换到参考视图:
F i , z ( u , v ) = F i ( H i ( z ) [ u , v , 1 ] T ) ( 4 ) F_{i,z}(u,v)=F_i(H_i(z)[u,v,1]^T)~~~(4) Fi,z(u,v)=Fi(Hi(z)[u,v,1]T) (4)
其中, F i , z F_{i,z} Fi,z为深度z处的扭曲特征图, ( u , v ) (u,v) (u,v)表示参考视图中的一个像素位置。在这项工作中,我们使用参考视图上的归一化的坐标(NDC)来参数化 ( u 、 v 、 z ) (u、v、z) (u、v、z)。
代价体
代价体P是由D扫描平面上的变换特征图构造出来的。我们利用基于方差的度量来计算代价,这已广泛应用在MVS中。特别是,对于P中以(u、v、z)为中心的每个体素,其代价特征向量的计算方法为:
P ( u , v , z ) = Var ( F i , z ( u , v ) ) ( 5 ) P_{(u,v,z)} =\text {Var}(F_{i,z}(u,v))~~~~(5) P(u,v,z)=Var(Fi,z(u,v)) (5)
其中,Var计算M个视图之间的方差。
此基于方差的代价体编码不同输入视图之间的图像外观变化;这解释了由场景几何图形和与视图相关的阴影效果引起的外观变化。虽然MVS的工作只使用这样的体积来进行几何重建,但我们证明了它也可以用来推断完整的场景外观,并实现真实的神经渲染。