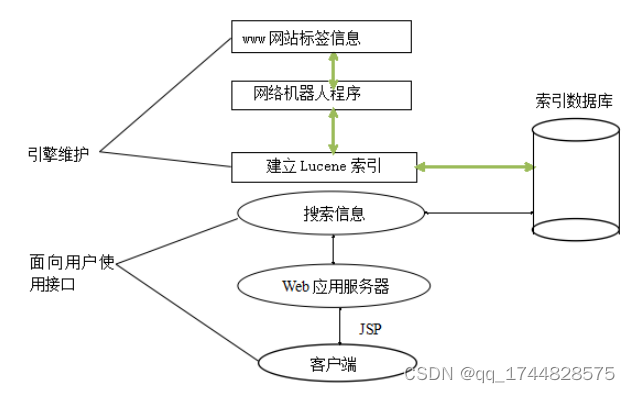
一、查看训练日志
训练日志是机器学习中广泛使用的训练诊断工具,每个 epoch 或 iterator 结束后,在训练集和验证集上评估模型,并以折线图的形式显示模型性能和收敛状况。训练期间查看模型的训练日志可用于判断模型训练时的问题,例如欠拟合或过拟合,以及训练和验证数据集是否合适等问题,为后续模型调优的参数设置提供了基础。 SuperMap 使用 tensorboard 记录训练时的日志,如需查看训练日志,可在系统命令行窗口输入:
tensorboard --logdir={日志路径}
如:
tensorboard --logdir=/home/city_grid/log/2020-12-04/image_classification
执行后,浏览器中访问 http://localhost:6006/,效果如图所示:

【注】使用 tensorboard 之前要保证命令行环境中 SuperMap iObjects Python Env(conda)可用,需配置 conda 到环境变量中,如windows:
E:\ProgramData\conda
E:\ProgramData\conda\Scripts
E:\ProgramData\conda\Library\bin
【注】需更改为本机路径
二、根据训练日志和指标得到较优模型
训练日志中的 y 轴经常为不同的评估指标,用以表示模型的性能,常用的有 loss、 Accuracy、IoU和mAP等。IoU是二元分类、地物分类等问题常用的评价指标,而mAP常用于评估目标检测模型的效果。在实际应用中,我们通常结合多种评估指标来综合评价模型的性能。
模型性能评估可以在训练数据集上进行,以了解模型的“学习”情况;也可以在验证集上进行,以了解模型的“泛化”能力。因此我们需要同时关注模型在训练集和验证集上的表现。
2.1 欠拟合
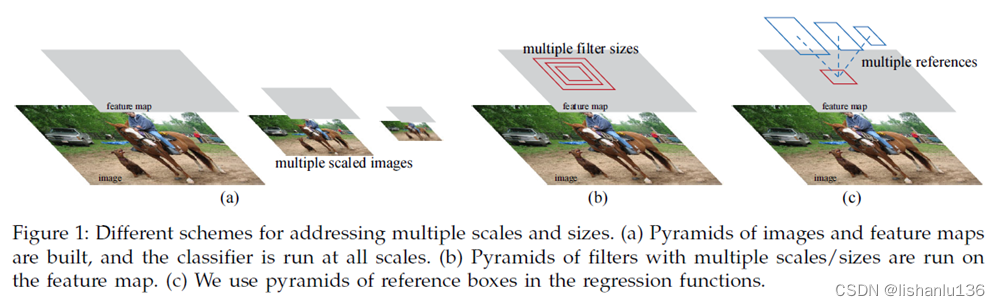
欠拟合表明模型没有充分学习训练数据集的特征,表明训练过程过早停止且该模型如进一步训练其性能可得到提升。在训练日志上(以 loss 为例),欠拟合一般有两种典型表现。它可能会显示一条趋于水平或维持相对较高 loss 值的水平曲线(如下图所示),表明模型无法学习训练集中足够的信息。这个时候可以考虑增加模型的复杂程度,通过增加隐藏层的数量来提升模型的学习能力

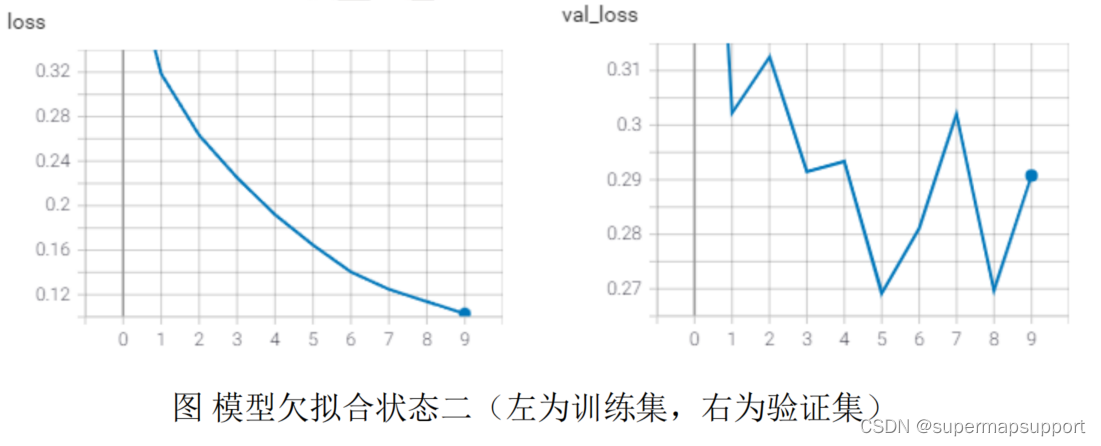
欠拟合状况也可通过训练结束时 loss 仍持续减少来识别。从下图可以看出,在训练结束时(epoch=9)模型在测试集上的 loss 持续下降并仍有下降的余地;而模型在验证集上的 loss 仍有较大波动,说明模型没有收敛。这时可增大 epoch 数量直到模型性能不再提升(可添加早停策略);如果需要很长时间才能达到验证集曲线上的最小值,可适当提高学习率加快梯度下降速度。
 2.2 过拟合
2.2 过拟合
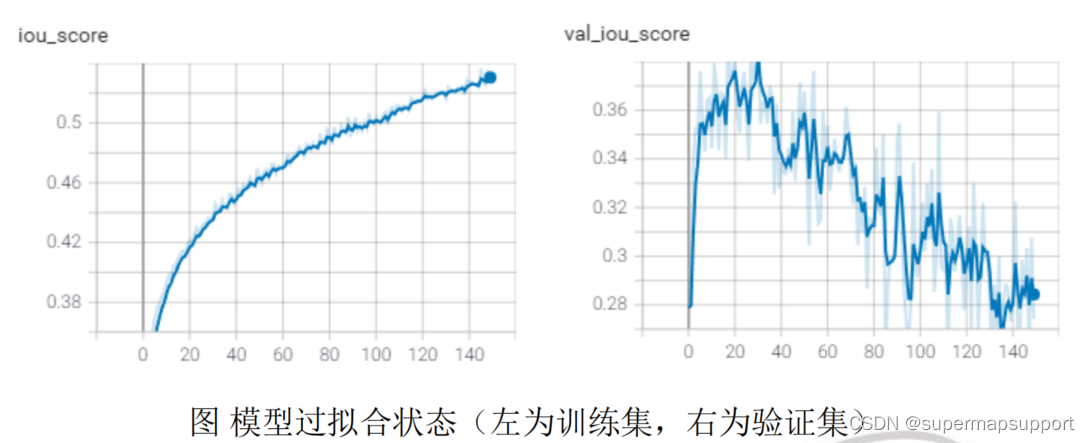
过拟合是指模型对训练数据集学习得“过”好,甚至学习到了训练集中的噪声或随机的错误信息。过拟合的问题在于模型对训练集上有较好的效果,但对新数据的泛化能力较差。这种泛化误差的增加可以通过模型在验证集上的性能来衡量。以 IoU 为例,过拟合情况在训练日志上可表示为训练集上 IoU 随着经验的增加而继续增加,同时验证集的 IoU 上升到一个点并开始再次降低,这个拐点可能是训练停止的点,因为该点之后的模型为过拟合状态。如下图所示,可以看到在训练集上模型性能逐步上升;而在验证集上,模型的精度在 30 个 epoch 之后就开始下降,模型开始出现过拟合。
如果过早过拟合并具有尖锐倒“U”形,除数据自身问题外还可能是由于学习率过大,可根据模型学习的速度适当调小学习率,并观察验证集上的拐点找到合适的 epoch大小。
2.3 模型收敛
模型收敛是训练的目标,以 loss 作为评价指标为例,模型收敛的训练日志情况应该是训练集上 loss 下降到稳定点,验证集上 loss 下降到稳定点,且两者的泛化差距很小(在理想情况下几乎为零)。泛化差距是指模型在训练集和验证集上表现的差距,是由于训练集和验证集的数据差异导致的。如下图所示,可以看到模型在训练集和验证集上的 loss 趋于稳定且波动较小,并且两者差异不大,模型达到收敛状态。

2.4 数据集的选择
训练日志还可用于诊断数据集选择是否合适(是否具有代表性)。不具有代表性的数据集是指该数据集无法概括样本中所有的特征信息。在训练和验证数据集之间,如果数据集中的样本数量相对于另一个数据集太少,就会发生这种情况。假设某项目需要同时识别影像中山地中稀疏的平房和市中心密集分布的高楼,如果训练集只包含了密集房屋的标签,就会使训练数据的信息不够全面,训练出的模型可能会对稀疏房屋没有很好的预测效果。这种情况可扩增对应数据集的样本,扩充时要尽量保证验证集和测试集的样本类别分布相似且较为均衡,以达到更好的训练效果。
数据集选择不佳在日志上可能表现为训练集的 loss 下降的很好,而验证集上的 loss波动较大且没有改进(如下图所示)。另一种表现形式可参考模型欠拟合的第一种情况,可能是由于训练数据正负样本之间区别不够明显或正样本特征不够突出造成的