为什么业务容器化之后,多活容灾变得更具挑战?
不像之前使用CVM或者物理机部署时,业务容器化之后,底层资源的可控程度更弱,应用实例生命周期更短、变化更快,这就给业务做容灾部署带来了更大的难度。
除此之外,当前自研业务大部分都是面向Kubernetes集群进行编排的,业务需要感知Kubernetes集群和集群内的资源拓扑,然后再结合自己的容灾部署拓扑去选择合适的集群,配置合适的调度标签进行强有序的多活部署。当每个地域/可用区的集群数量很多时,这个动作也会变的较重。
有的云管平台,每个集群底层的资源拓扑并不是一层不变的,有些集群包含了多个Zone的资源,有些集群只有单个Zone的资源。有人会问,为什么我们不固化一个标准来建设集群,比如每个集群就只配置单个Zone的资源,或者每个集群都覆盖某个地域的所有Zone的资源。因为这两种集群资源模式都存在各自致命的问题:
如果每个集群只配置单个Zone的资源,当每个Zone资源都是充足的情况下,这并不会有什么问题,但是当某个Zone出现资源不足时,业务紧急情况需要继续扩容,此时一定是允许一定比例的应用实例扩容到其他Zone,此时业务只能手动去找其他Zone的集群,对Workload进行扩容操作。如果业务在每个集群都配置了HPA,那么资源不足的那个Zone对应的集群的HPA将持续告警,无法自动扩容到其他Zone。
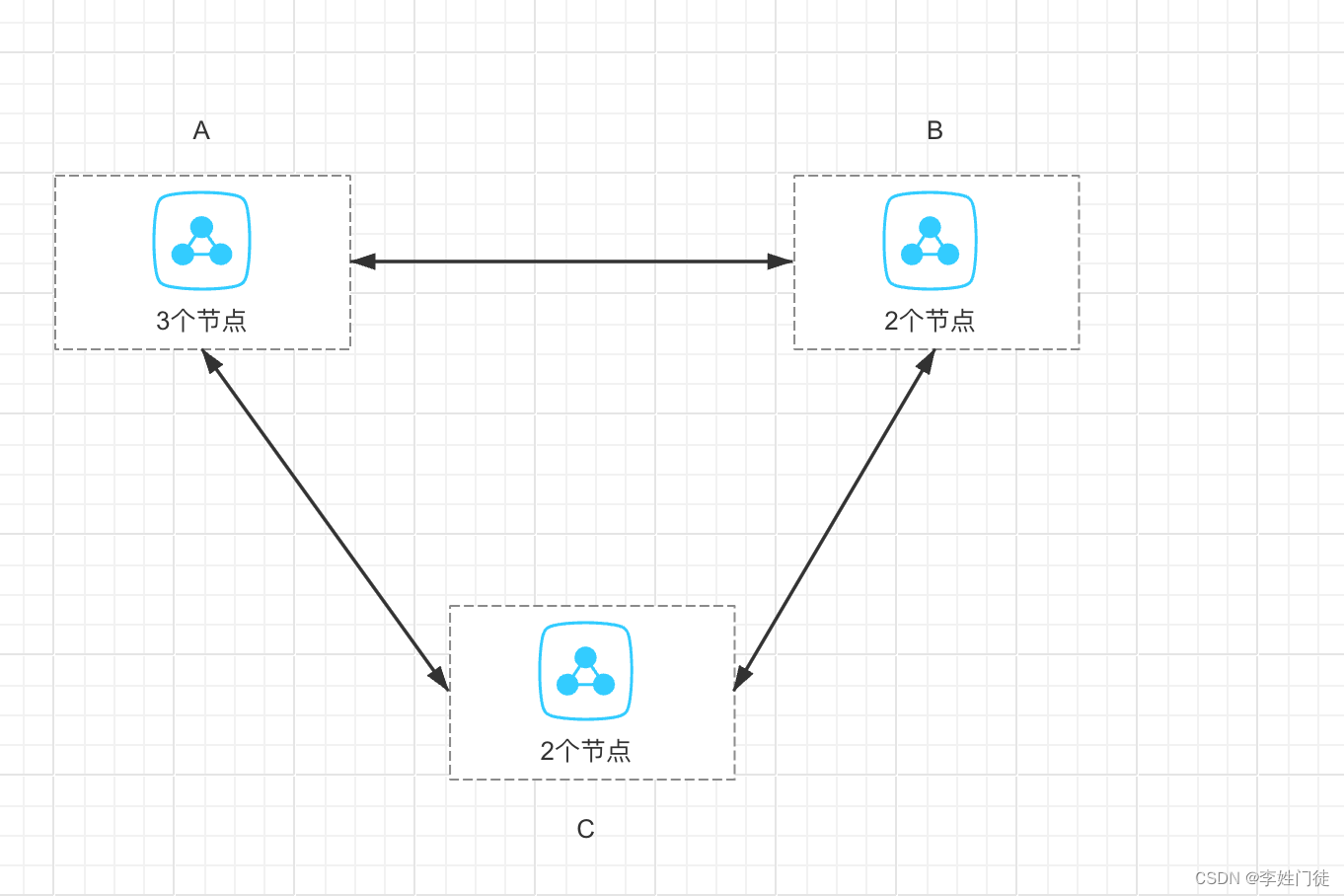
如果每个集群都覆盖多个Zone的资源,那么业务只需要在单个集群部署就能实现多Zone容灾的需求,这需要容器平台提供单集群内多Zone拓扑分布比例的调度能力,比如应用A需要在广三、广四部署1:1的拓扑。Kubernetes 1.27 支持的”Topology Spread Constraints“ 这一Beta特性还不足以满足我们的场景,除了它需要升级Kubernetes集群版和配置的复杂度、使用心智负担之外,还不支持自定义各个Zone分布比例等场景。另外,这种集群最后一定会演变为超大规模的单集群,它的故障爆炸半径也非常大。
业务需要底层多活容灾部署,到底是业务自己去根据复杂的底层集群和资源拓扑去精细化构建,还是说应该由容器平台来完全兜底,并作为一种不对用户感知的默认的产品能力?
不同的业务场景对容灾的需求存在差异,所以底层PaaS平台需要提供不同的业务容灾部署策略,客户根据自己的容灾需求配置部署策略。应用托管平台根据客户配置的部署策略声明,进行自动化的Reconcile,包括首次部署业务时,以及遇到底层集群、可用区甚至地域级别的异常时,始终能保证客户的部署策略能最大化的得到满足。
所以,业务的容灾,是需要业务和应用托管平台都关注的事情,业务评估自己的容灾场景,平台提供对应的容灾部署能力。





















![[C++]TinyWebServer](https://i-blog.csdnimg.cn/direct/64132595aa8544d7a33ce90667c11bc0.png)