一、什么是索引
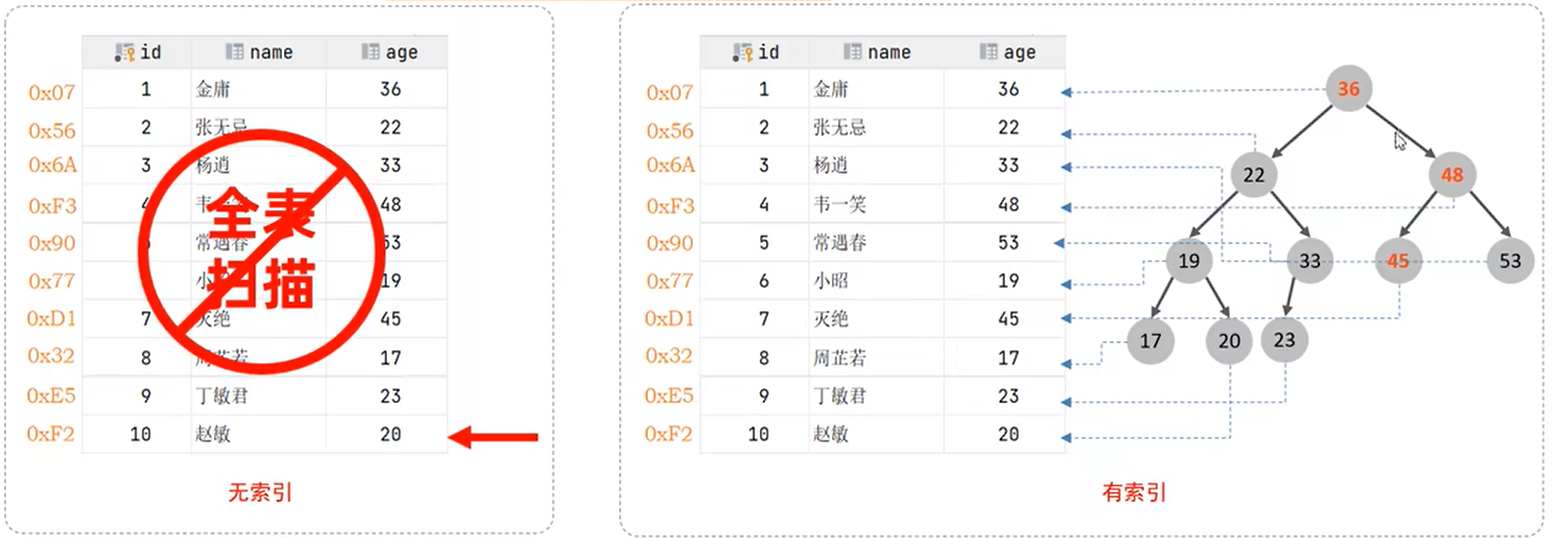
存储引擎用于快速找到记录的一种数据结构。
索引类似于目录。就比如我们要找书里的一段话,我们先按目录找,然后再具体定位,这样速度会很快。
二、索引的作用
通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
可以大大加快数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。
帮助服务器避免排序和临时表。
将随机IO变为顺序IO(索引加快查询速度的根因)
可以加速表和表之间的连接。
三、Mysql索引主要使用的两种数据结构
MySQL索引使用的数据结构主要有BTree索引 和 哈希索引 。
单条记录查询用哈希索引;其余大部分场景,建议选择BTree索引。
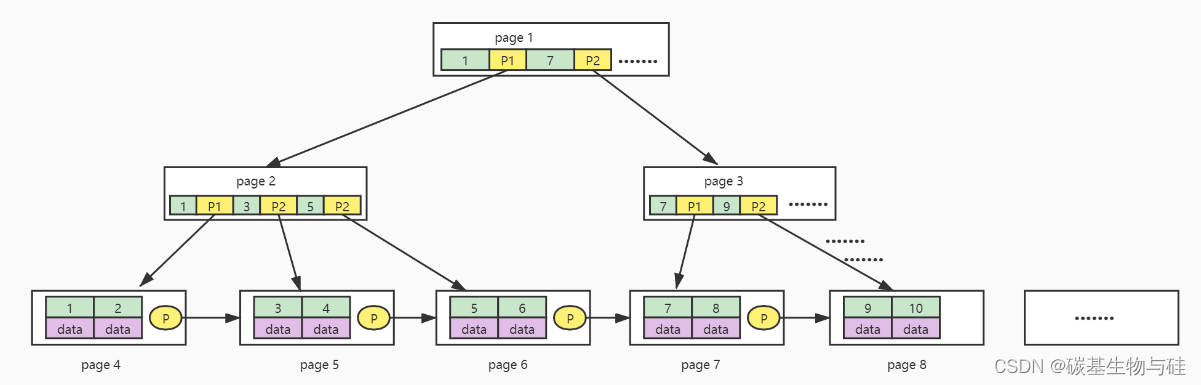
MySQL的BTree索引使用的是B树中的B+Tree,但对于主要的两种存储引擎的实现方式是不同的。
InnoDB: 其数据文件本身就是索引文件。这就是聚簇索引(或聚集索引)。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。(回表)辅助索引还包含当前列的值。因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
MyISAM: B+Tree 叶节点有key 和 value。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”(数据和索引分开)。
四、索引的分类

(1)逻辑上
按功能划分:
主键索引(Primary Key):一张数据表有只能有一个主键,并且主键不能为 null,不能重复。
数据表的主键列使用的就是主键索引。
在 mysql 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
二级索引(辅助索引):二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。
唯一索引,普通索引,前缀索引等索引属于二级索引。
- 唯一索引(Unique Key) :数据列不允许重复,允许为 NULL 值,一张表可有多个唯一索引,索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。建立唯一索引的目的大部分是为了该属性列的数据的唯一性,而不是为了查询效率。
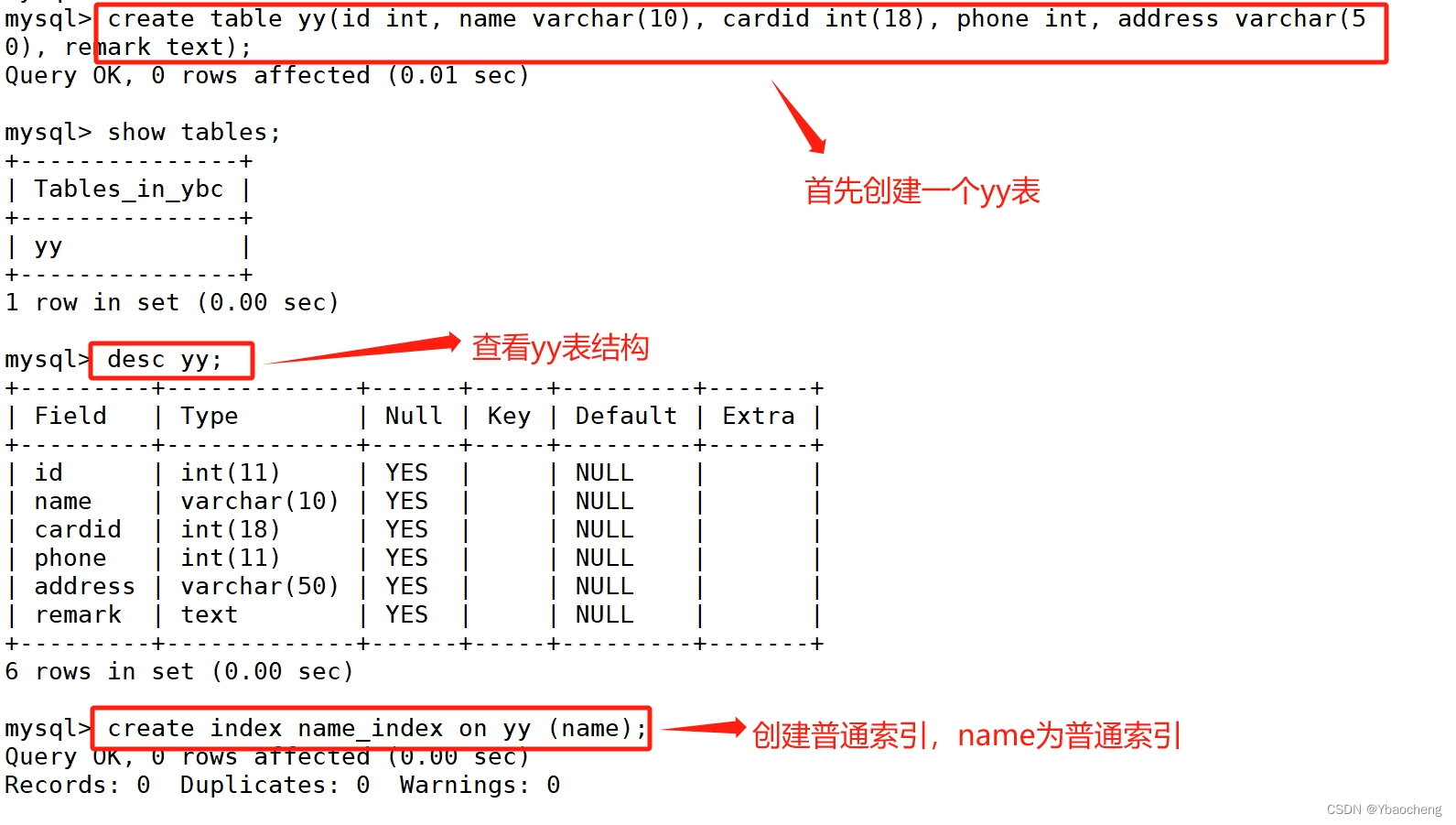
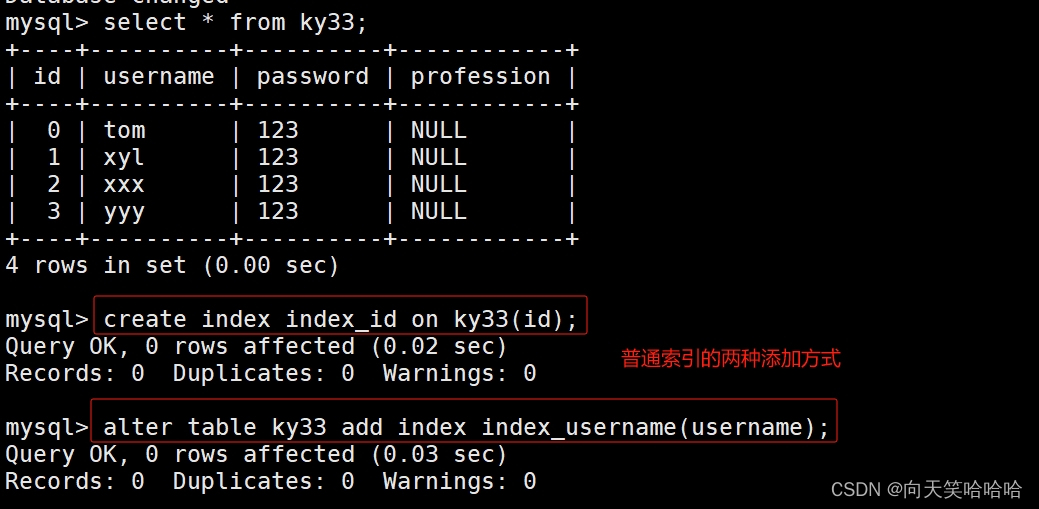
- 普通索引(Index) :普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。
- 前缀索引(Prefix) :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小, 因为只取前几个字符。
- 全文索引(Full Text) :一张表可以创建多个普通索引,一个普通索引可以包含多个字段,允许数据重复,允许 NULL 值插入;
按列数划分
- 单列索引:一个索引只包含一个列,一个表可以有多个单例索引。
- 组合索引:一个组合索引包含两个或两个以上的列。查询的时候遵循 mysql 组合索引的 “最左前缀”原则,即使用 where 时条件要按照建立索引的时候字段的排列方式放置索引才会生效。
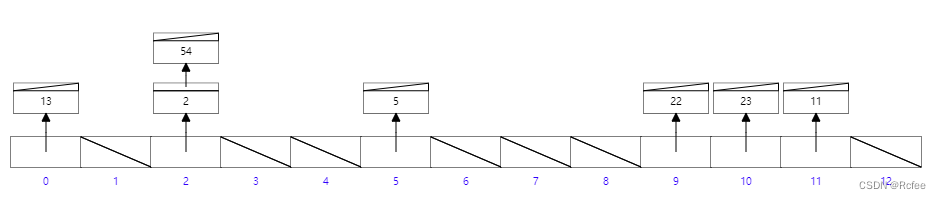
(2)物理上(聚簇索引和非聚簇索引)
聚簇索引:索引结构和数据一起存放的索引。主键索引属于聚集索引。
在 Mysql 中,InnoDB 引擎的表的 .ibd文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
非聚簇索引:非聚簇索引即索引结构和数据分开存放的索引。二级索引属于非聚集索引。
MYISAM 引擎的表的.MYI 文件包含了表的索引, 该表的索引(B+树)的每个非叶子节点存储索引, 叶子节点存储索引和索引对应数据的指针,指向.MYD 文件的数据。
可能会二次查询(回表) :这应该是非聚集索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
总结:聚簇索引优缺点
优点:
- 数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快
- 聚簇索引对于主键的排序查找和范围查找速度非常快
缺点:
- 依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键。
- 更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新。
补充覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢。覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
eg:
现在我创建了索引(username,age),我们执行下面的 sql 语句
select username , age from users where username = 'zql' and age = 21在查询数据的时候:要查询出的列在叶子节点都存在!所以,就不用回表。