目录
Fully-Visible Attention(全连接注意力)
Causal Attention with Prefix(带前缀的因果注意力)
掩码语言建模(Masked Language Modeling)
下一个句子预测(Next Sentence Prediction)
干货分享,感谢您的阅读!
一、ChatGPT整体背景认知
ChatGPT是由OpenAI开发的对话机器人,于2022年11月30日上线,在上线的前五天内,其用户数量迅速突破百万,用户在社交平台上分享与ChatGPT的对话内容,引发了社交媒体上的巨大反响。截至2023年1月末,ChatGPT的用户数已经超过1亿,成为史上增长最快的消费者应用之一。平均每天有1300多万人次访问,较去年12月增长了两倍多。就其基本关注原因和与行业竞争来简单对其进行分析如下。
(一)ChatGPT引起关注的原因
卓越的语言理解和生成能力:ChatGPT的出色之处在于其强大的自然语言处理能力。它能够理解多种人类指令,并生成有趣、通顺、逻辑流畅的回复,使用户能够享受到更自然的对话体验。
广泛的知识基础:ChatGPT通过大规模的训练数据获得了广泛的知识,能够回答与现实世界相关的各种问题。用户可以向它提问各种话题,获得合理且准确的回答,甚至要求其扮演不同角色,增加了互动性和趣味性。
NLP领域学习范式的发展和变革:ChatGPT的成功反映了自然语言处理领域的技术进步。深度学习、大规模数据集和强化学习等技术的不断发展推动了对话机器人的性能提升,使其能够更好地满足用户需求。
(二)与其他公司的竞争情况
微软的投资和整合:微软早在2019年就向OpenAI投资了10亿美元,并与其合作研发Azure AI超级计算技术。随着ChatGPT的成功,微软于2023年1月末再次向OpenAI投资100亿美元,并宣布将其旗下所有产品整合到ChatGPT平台上,这进一步推动了ChatGPT的发展。于2023年2月8日正式发布了整合ChatGPT的新版必应搜索引擎,这一举措进一步提高了ChatGPT的曝光和影响力,使微软市值涨超800亿美元。
谷歌的竞争产品Bard:为了应对ChatGPT的竞争,谷歌于2023年2月宣布推出一款名为Bard的对话机器人产品,这表明谷歌也在积极参与对话机器人领域的竞争。
百度的项目“文心一言”:百度也跟随潮流,在2023年2月确定了内部类似于ChatGPT的项目名称为“文心一言”,显示了百度对对话机器人领域的兴趣。
ChatGPT之所以引起广泛关注,是因为它代表了自然语言处理技术的最新进展,并在用户界面和功能上实现了显著的提升。与此同时,微软、谷歌、百度等巨头公司的参与也加剧了对话机器人领域的竞争,推动了整个领域的创新和发展。这些因素使ChatGPT成为了NLP领域的焦点和资本圈的宠儿。
二、NLP学习范式的发展
NLP领域的发展不是线性的,各个阶段之间可能会存在重叠和交织。不同的方法和思想在不同的时间点都可能存在,并且随着技术和理论的不断进步,NLP领域的学习范式也会不断演化。NLP领域的学习范式的发展简单总结为如下四个阶段:
(一)规则和机器学习时期
这是NLP研究的早期阶段,研究者主要依赖手工设计的规则和特征来处理自然语言文本。这些规则和特征用于任务如语言模型、文本分类和信息检索。
以下是对这一时期的详细解释:
手工设计的规则:在这个时期,NLP研究者尝试通过定义和编写一系列语法和语义规则来理解和处理自然语言。这些规则旨在捕捉语言的结构、语法规范和语义含义。例如,可以定义规则来处理句子的句法结构,如主谓宾结构或从句的嵌套。
特征工程:研究者还会手工选择和构建特征,这些特征用于训练传统的机器学习模型,如决策树、支持向量机等。这些特征可以包括词汇特征(如词频、词性标签等)、句法特征(如句子长度、句法树结构等)以及语义特征(如词义、共现关系等)。
任务应用:手工设计的规则和特征用于各种NLP任务,包括但不限于:语言模型---建立了基于规则的语言模型,试图预测句子中下一个词汇的可能性;文本分类---使用手工设计的特征来对文本进行分类,如垃圾邮件检测或情感分析;信息检索---应用规则来检索文本中包含特定关键词或信息的文档或句子。
局限性:尽管这个时期的方法在当时具有一定效果,但它们存在一些显著的局限性。首先,手工设计规则和特征需要大量的人力工作,因此对于大规模的自然语言文本来说不太实际。其次,这些方法往往无法捕捉到语言的复杂性和多义性,因此在处理实际自然语言任务时效果有限。
NLP研究的早期阶段主要依赖手工设计的规则和特征,这些方法奠定了NLP领域的基础,但也在后来被更先进的数据驱动方法和神经网络技术所取代。然而,这些早期的工作为NLP研究提供了宝贵的经验和理论基础。
(二)基于神经网络的监督学习时期
随着神经网络技术的发展,NLP领域开始采用神经网络来解决问题。这一时期的突破包括循环神经网络(RNN)和卷积神经网络(CNN)的应用,以及诸如词嵌入(Word Embeddings)的技术。监督学习是主要范式,需要大量标记数据进行训练。
循环神经网络(RNN):RNN是一种具有循环连接的神经网络架构,特别适用于处理序列数据,如文本。在NLP任务中广泛用于处理文本序列,如语言建模、文本生成和情感分析等。
卷积神经网络(CNN):CNN是一种用于处理网格结构数据的神经网络,最初用于计算机视觉任务,但后来也被引入到NLP领域。在NLP中,CNN通常用于文本分类和文本表示学习,通过卷积操作捕捉文本中的局部特征。
词嵌入(Word Embeddings):词嵌入是一种将单词映射到低维向量空间的技术,它在这个时期的NLP中扮演了重要角色。Word2Vec、GloVe等词嵌入模型使单词的表示更加紧凑,同时保留了它们之间的语义关系,有助于提高NLP任务的性能。
监督学习范式:在这个时期,监督学习是主要的学习范式,这意味着模型需要在大量带有标签的训练数据上进行训练。NLP任务如文本分类、命名实体识别和机器翻译等通常采用监督学习方法。
数据量的需求:神经网络在NLP任务中取得显著成果,但也需要大量的标记数据来进行训练。这意味着收集和标注大规模数据集成为一个挑战,尤其对于一些特定领域和语言。
基于神经网络的监督学习时期标志着NLP领域向数据驱动方法和深度学习技术的过渡。这一时期的突破,包括RNN、CNN和词嵌入等技术的应用,为后续NLP领域的进一步发展和深化奠定了基础。然而,它也带来了对大规模标记数据的需求,这在某些情况下可能限制了模型的应用范围。随着技术的不断演进,NLP领域的研究不断取得新的突破和进展。
(三)Pretrain then Fine-tune时期
这一时期是近年来NLP领域的一大转折点。在这一范式中,模型首先在大规模文本数据上进行预训练(例如BERT、GPT等),然后在特定任务上进行微调(Fine-tune)。这种方法取得了巨大的成功,因为预训练的模型能够捕获通用语言表示,然后在不同任务上进行调整。
预训练模型的兴起:在这一时期,预训练模型如BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pretrained Transformer)等出现在NLP领域。这些模型在大规模文本语料库上进行预训练,通过学习通用的语言表示,捕捉了语言的语法、语义和丰富的上下文信息。这使得它们能够更好地理解自然语言。
微调:一旦模型完成了预训练,它可以在特定的下游任务上进行微调。微调是指在任务相关的数据上对预训练模型的参数进行调整,以适应特定的任务。这使得模型能够根据任务要求进行细粒度的调整,从而提高性能。
自监督学习:这一时期还涌现出了自监督学习方法,其中模型通过利用大规模无标注语料来自我训练。自监督学习方法允许模型从未标记的文本数据中学习,从而更好地理解语言的结构和含义。
SOTA性能:Pretrain then Fine-tune时期的最大突破之一是取得了一系列NLP任务的新的状态-of-the-art(SOTA)性能。这些预训练模型不仅在传统NLP任务中表现出色,还在问答、文本生成、机器翻译等各种自然语言处理任务中刷新了性能记录。
降低数据需求:由于预训练模型具有更强大的通用语言理解能力,它们通常需要更少的任务特定标记数据来在下游任务上进行微调。这降低了数据收集和标注的成本,使NLP技术更加易于应用。
Pretrain then Fine-tune时期代表了NLP领域的一次技术革命。预训练模型的引入为NLP任务带来了更好的语言理解和表现能力,同时也提高了任务的效率。这一时期的创新推动了NLP领域的迅猛发展,使其在各种应用领域取得了显著的突破和进展。预训练模型的成功还启发了其他领域对于迁移学习和自监督学习的研究,对深度学习领域产生了深远的影响。
(四)Prompt Learning时期
这是近年来的新发展,其中研究者探索了一种更加交互式的方法,即为模型提供任务特定的提示(prompts),以使其执行特定任务。这种方法在一些任务上取得了良好的性能,并减少了对大量标记数据的需求。一些例子包括GPT-3的使用,通过修改提示来执行各种任务。
提示学习的概念:在Prompt Learning时期,研究者将注意力集中在如何为NLP模型提供有效的任务提示上。提示是一种特定的文本或问题,可以指导模型执行特定的自然语言处理任务。这种方法旨在使模型更具交互性和可控性,以满足用户的具体需求。
GPT-3的例子:GPT-3(Generative Pretrained Transformer 3)是一个具有1750亿参数的大型语言模型,广泛用于Prompt Learning。用户可以通过修改输入提示,要求GPT-3执行各种任务,包括文本生成、翻译、问题回答、代码生成等。例如,用户可以提供以下提示:"Translate the following English text to French: 'Hello, how are you?'",然后GPT-3会生成相应的法语翻译。
减少标记数据需求:Prompt Learning方法的一个重要优势是减少了对大量标记数据的需求。传统的监督学习方法通常需要大量的任务特定数据来训练模型,而Prompt Learning允许模型通过提示进行任务,无需大规模标记数据。这使得更多领域和任务可以受益于NLP技术,尤其是在数据有限的情况下。
可解释性和控制性:Prompt Learning还具有一定程度的可解释性和控制性。用户可以直接定义提示,以明确指示模型的行为。这为用户提供了更多的控制权,使他们能够塑造模型的输出以满足其特定需求。
挑战与研究方向:尽管Prompt Learning在一些任务上取得了成功,但它仍面临一些挑战,如提示设计的复杂性、模型的鲁棒性和通用性等。因此,研究者正在积极探索更有效的提示生成和模型训练方法,以进一步提高性能和可用性。
Prompt Learning时期代表了NLP领域朝着更加交互式、可控和数据效率的方向发展。这一方法为各种自然语言处理任务提供了一种新的方法,特别是在数据有限的情况下,它为模型提供了灵活性,使其能够适应多样化的用户需求。随着进一步的研究和发展,Prompt Learning有望在NLP应用中发挥越来越重要的作用。
三、预训练介绍
Transformer预训练模型在NLP学习范式的不同时期(Pretrain then Fine-tune时期和Prompt Learning时期)都起着关键作用,它们通过在大规模文本数据上学习通用的语言表示,赋予模型深层次的先验信息。这种先验信息使得模型更具语言理解能力,并能够根据任务要求进行适应。这两个时期的创新突出了先验信息的价值,将其成功地整合到NLP任务中,从而取得了显著的性能提升。
(一)预训练方法最重要三要素
预训练方法最重要的三要素:(1)Transformer架构(2)预训练目标(3)大规模语料。架构和预训练目标的组合构成了预训练的方法,而语料和模型的规模越大,往往模型的性能越强。
Transformer架构
Transformer是一种深度学习模型架构,最初由Vaswani等人在2017年提出。它引入了自注意力机制(Self-Attention),允许模型在处理序列数据时更好地捕捉上下文信息。Transformer的架构在NLP领域得到了广泛应用,因为它在各种自然语言处理任务中表现出色。
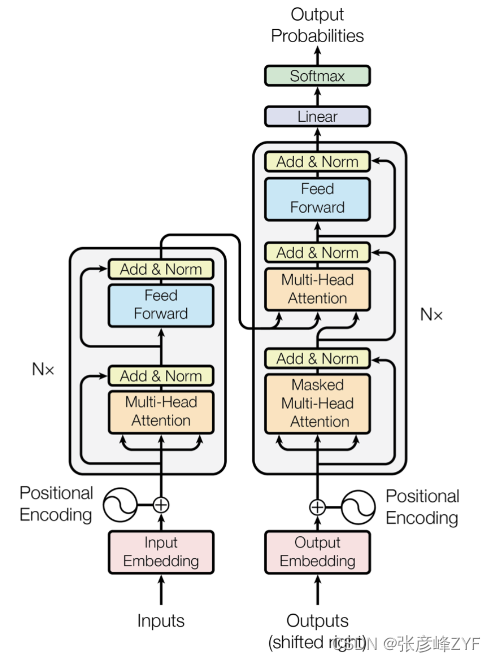
Transformer的架构包括编码器和解码器,但在预训练中通常只使用编码器部分,因为它具有强大的文本编码能力。这些编码器层堆叠在一起,形成深层的神经网络,使模型能够理解复杂的语言结构。
预训练目标
预训练目标是在大规模语料上训练模型的任务。这个任务通常是无监督的,模型在这个任务上自行学习。在NLP中,一些常见的预训练目标包括:
- 语言建模(例如BERT的Masked Language Modeling):模型被要求预测输入文本中部分词汇被遮盖的位置的词汇。
- 下一个句子预测:模型被要求判断两个句子是否是连续的。
- 自编码:模型将输入文本编码为向量,并尝试将其解码回原始文本。
预训练目标的选择对于模型学到的语言表示具有重要影响,因此研究人员根据任务需求进行设计和选择。
大规模语料
大规模语料是预训练模型成功的关键。模型需要在大量文本数据上进行预训练,以捕捉通用的语言知识和模式。这包括来自互联网、书籍、新闻文章、维基百科等多样化的文本来源。
大规模语料库的使用有助于模型更好地理解多样性的文本,使其更具通用性和泛化能力。较大规模的语料通常会产生更强大的预训练模型。
总的来说,三要素(Transformer架构、预训练目标和大规模语料)共同构成了预训练方法的关键组成部分。它们之间的组合和优化对于模型的性能至关重要,因此研究人员在这些方面进行了广泛的研究和实验,以不断改进NLP模型的性能和能力。这些要素的不断演进也推动了NLP领域的发展和进步。
(二)架构选择
架构的选择主要体现在Attention中mask的实现方式,主要包括如下三种:
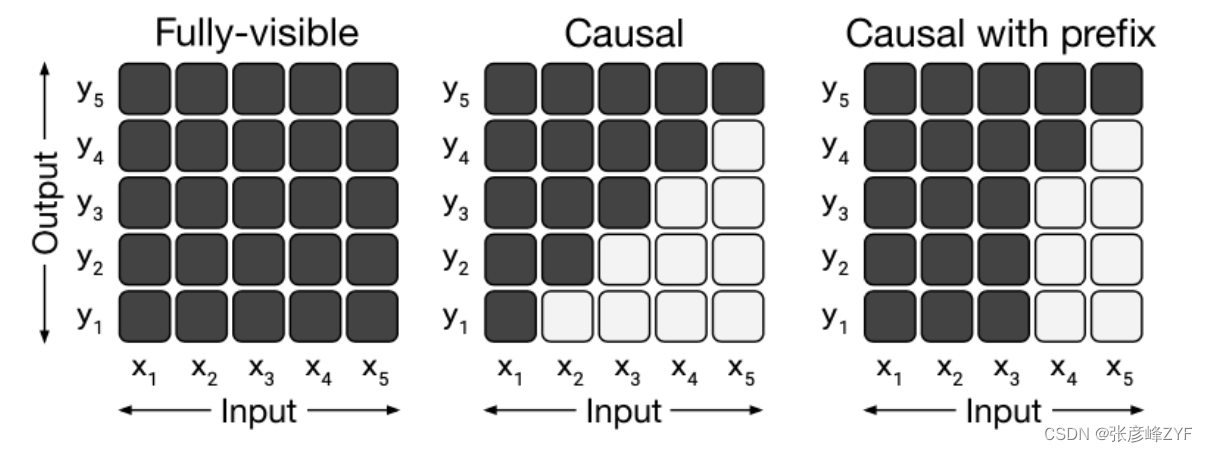
Fully-Visible Attention(全连接注意力)
在Fully-Visible Attention中,每个位置都可以关注到序列中的所有其他位置,没有任何掩码限制。这种注意力方式允许模型在计算注意力时考虑整个输入序列的上下文。
Fully-Visible Attention通常在全连接神经网络中使用,而不是在自注意力(Self-Attention)中。
Causal Attention(因果注意力)
因果注意力用于自注意力机制,以确保每个位置只能关注到自身之前的位置,而不能看到自身之后的位置。这在保持因果关系方面非常重要,例如,在语言建模任务中,一个词语的生成应该依赖于前面的词语,而不能依赖于后面的词语。
因果注意力通常在自注意力模型(如Transformer解码器)中使用,以确保生成的序列按照正确的顺序生成。
Causal Attention with Prefix(带前缀的因果注意力)
带前缀的因果注意力也用于自注意力机制,类似于因果注意力,但它还包括了前缀的信息。这种前缀信息可以用于引导模型生成特定前缀的输出。
这在一些NLP生成任务中很有用,例如在生成问题答案时,可以使用问题作为前缀来生成答案。
每种注意力实现方式都在不同的上下文和任务中具有不同的用途。全连接注意力适用于一些全连接神经网络架构,而因果注意力和带前缀的因果注意力通常在自注意力模型中使用,以满足因果关系和序列生成的需求。选择适当的注意力方式取决于任务的要求和模型的架构。
(三)训练目标
在无标注文本语料上,可以设计各种可行的训练目标,这导致了多种不同的预训练模型。然而,核心的训练目标通常包括以下几种:
语言建模(Language Modeling)
语言建模是一种经典的预训练任务,它的目标是让模型预测文本序列中的下一个词或子词。在语言建模中,模型接受一个文本序列的前面部分,并尝试预测接下来的词语。这种任务通常采用自回归(autoregressive)的方式,即逐词生成序列。
常见的语言建模方法包括单向语言建模和双向语言建模。BERT(Bidirectional Encoder Representations from Transformers)使用了双向语言建模,其中部分输入文本中的词汇被随机遮盖,模型需要预测这些遮盖词汇。
掩码语言建模(Masked Language Modeling)
掩码语言建模与语言建模类似,但与其不同的是,在输入序列中的一部分词汇被随机遮盖,而模型需要预测这些遮盖词汇。这使得模型需要更好地理解上下文信息来填补遮盖位置的词汇。
BERT就是一个采用了掩码语言建模的预训练模型,它通过这种方式来学习词汇之间的关系。
下一个句子预测(Next Sentence Prediction)
下一个句子预测是一种预训练任务,模型的目标是判断两个句子是否是连续的。在这个任务中,模型接受一对句子作为输入,并尝试预测它们是否是文本中的连续句子。
下一个句子预测任务有助于模型理解句子之间的关联性和上下文信息。它被用于BERT的预训练中。
这些核心的训练目标都有助于模型在预训练阶段学习通用的语言表示。此外,研究人员还可以设计其他自定义的预训练任务,以适应特定应用领域或任务需求。不同的训练目标和任务可以导致不同类型的预训练模型,使它们在各种NLP任务中表现出色。
(四)模型规模发展
美国各大科技公司,如Google、Facebook、Microsoft等,已经全面拥抱大规模预训练模型,并投入大量资源来推动这一领域的研究和发展。这些公司竞相发布更大规模的模型,以提供更先进的自然语言处理能力。大规模预训练模型的发展已经改变了自然语言处理领域的格局,它们在各种NLP任务中都表现出了强大的性能。然而,随着规模的增加,成本和资源需求也增加,因此在选择模型规模时需要权衡性能和可行性。以下是对预训练模型规模变化的分析:
模型规模的增长
- 随着时间的推移,预训练模型的规模经历了持续的增长。最初的模型规模约为数百万至数千万参数,然后逐渐扩大到亿级别、千亿级别,甚至千亿以上参数的规模。
- 这种规模的增长主要受到两个因素的推动:首先是认识到更大的模型可以在各种NLP任务上表现更好,其次是训练和硬件资源的改进,使得可以训练更大规模的模型。
性能的提升
- 随着模型规模的增加,性能通常会提升。更大规模的模型通常能够捕捉更多的语言知识和上下文信息,从而在各种NLP任务上取得更好的表现。
- 大规模模型在各种竞赛和基准测试中通常能够实现State-of-the-Art(SOTA)的性能,包括文本分类、命名实体识别、机器翻译等任务。
计算成本的增加
- 随着模型规模的增加,训练和部署这些模型的计算成本也大幅增加。更大规模的模型需要更多的计算资源和时间来进行训练,这可能会对研究和产业应用的可行性产生影响。
- 许多大型公司和研究机构投入大量资源来支持超大规模模型的研发和训练。
数据需求的增加
- 大规模模型通常需要更大规模的训练数据来实现好的性能。这意味着需要收集、清理和标记更多的文本数据,以满足模型的需求。
- 数据的规模和质量对于预训练模型的性能至关重要。
硬件和加速器的发展
- 为了支持超大规模模型的训练,硬件和加速器技术也在不断发展。GPU、TPU等专用硬件被广泛用于大规模模型的训练。
- 云计算平台也提供了大规模模型训练的基础设施和资源。
总的来说,预训练模型规模的增长是自然语言处理领域的一个显著趋势,它在提高NLP任务性能方面取得了重大突破。然而,这种规模增长也伴随着计算、数据和资源的挑战,需要综合考虑性能、成本和可行性,以选择适当规模的模型来满足特定任务的需求。
四、OpenAI的GPT系列
GPT(Generative Pre-trained Transformer)系列是自然语言处理领域中最具代表性的预训练模型之一,由OpenAI开发。
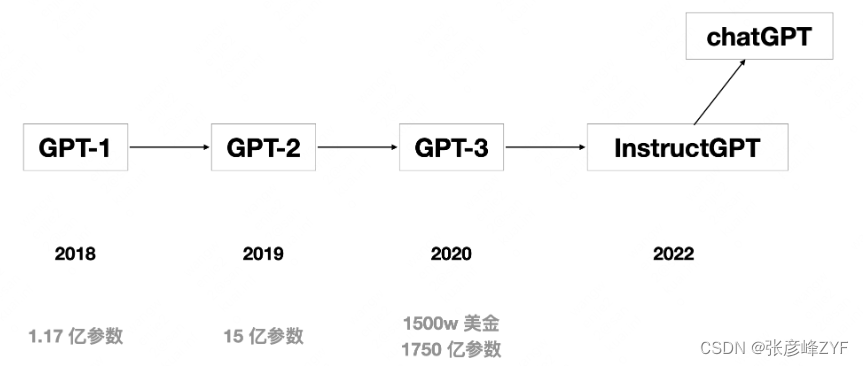
GPT-1:GPT系列的第一个模型,采用了预训练-微调(Pretrain then Fine-tune)的范式,这是NLP领域的一个重要创新。GPT-1在Transformer架构下进行单向的语言建模。
GPT-2:GPT-2引入了一个重要的思想,即预训练过程中隐式地建模多任务学习。这意味着模型在预训练期间学习了更多的通用语言知识,使其在各种下游任务上表现更好。
GPT-3:GPT-3是GPT系列的一个重大里程碑,因其巨大的参数规模和能够执行Few-shot In-Context Learning,即在不进行参数微调的情况下,根据少量任务示例有效地处理下游任务。这个能力引起了广泛的关注和讨论。
InstructGPT:InstructGPT是基于GPT-3的版本,通过Instruction Tuning进一步增强了模型理解和处理人类指令的能力。它展示了模型的Zero-Shot学习能力,即不需要提供示例展示就可以执行任务。
ChatGPT:ChatGPT是InstructGPT在对话领域的深度优化版本,使模型能够在对话中提供更自然和有趣的回复。ChatGPT的出现引发了对话AI领域的极大兴趣和关注。
总的来说,GPT系列代表了自然语言处理领域的先进技术,它们不断推动着预训练模型在各种自然语言理解和生成任务中的性能边界。从GPT-1到GPT-3以及后续版本的演进,突显了模型规模、多任务学习、Few-shot Learning、Zero-shot Learning等关键概念的重要性,为自然语言处理领域的发展带来了深远影响。