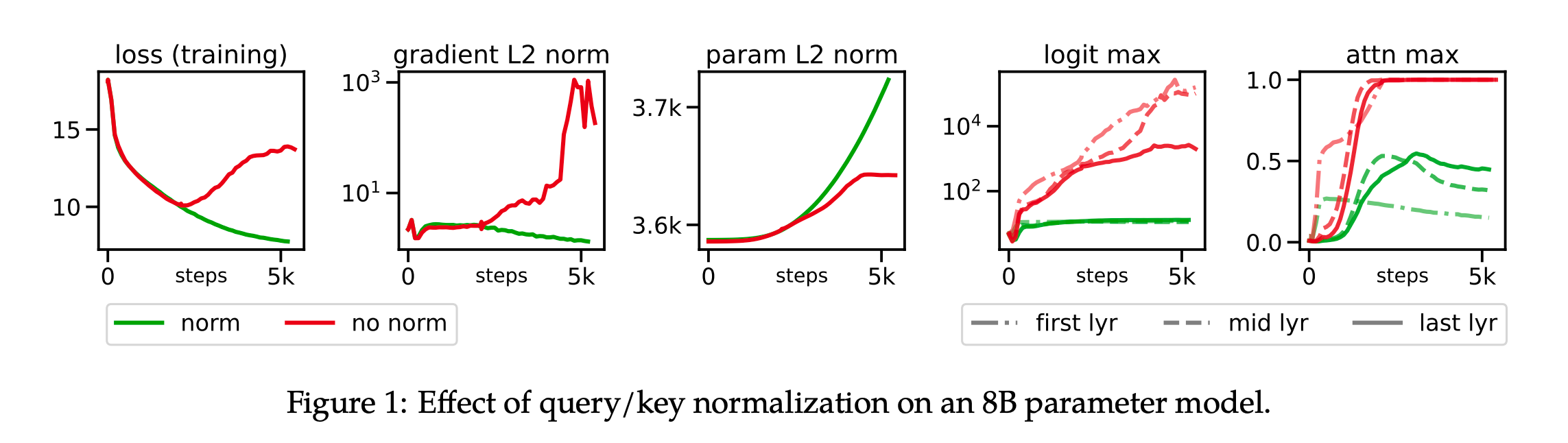
urllib介绍
除了requests模块可以发送请求之外, urllib模块也可以实现请求的发送, 只是操作方法略有不同!
urllib在python中分为urllib和urllib2, 在python3中为urllib
urllib的基本方法介绍
urllib.Request
构造简单请求
import urllib.request
# 构造请求
request = urllib.request.Request('http://www.baidu.com')
# 发送请求获取响应
response = urllib.request.urlopen(request)
传入headers参数
import urllib.request
url = 'http://www.baidu.com'
# 构造headers
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0"}
# 构造请求
request = urllib.request.Request(url = url, headers = headers)
# 发送请求
response = urllib.request.urlopen(request)
# 打印响应状态码
print(response.getcode())
# 打印响应内容
print(response.read().decode('utf-8'))
# 下载图片
urllib.request.urlretrieve('https://image.so.com/view?q=%E8%99%8E%E5%9B%BE%E7%89%87&correct=%E8%99%8E%E5%9B%BE%E7%89%87&ancestor=list&cmsid=8a6458dfa047475a670bff31e9de0f3b&cmras=0&cn=0&gn=0&kn=0&crn=0&bxn=0&fsn=60&cuben=0&pornn=0&manun=2&adstar=0&clw=250#id=09b4212daa5fcf6ddc4ea4015d50763b&currsn=0&ps=90&pc=90',filename='taigger.webp')
# 下载视频
url = 'https://vdept3.bdstatic.com/mda-qg7mssmgjd0m5fkc/cae_h264/1720465211156013709/mda-qg7mssmgjd0m5fkc.mp4?v_from_s=hkapp-haokan-nanjing&auth_key=1721408824-0-0-b00e72a2bb1d10291afb346c6011164d&bcevod_channel=searchbox_feed&pd=1&cr=0&cd=0&pt=3&logid=0424608341&vid=8632596696396555616&klogid=0424608341&abtest='
urllib.request.urlretrieve(url, filename='1.mp4')
get传参
单个参数传递
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/s?wd='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.6261.95 Safari/537.36'
}
name = urllib.parse.quote("迪丽热巴")
url = url + name
print(url)
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
多个参数传递
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/s?wd='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.6261.95 Safari/537.36'
}
data = {
'wd': '迪丽热巴',
'sex': '女',
}
data = urllib.parse.urlencode(data)
url = url + data
print(url)
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
post传参
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.6261.95 Safari/537.36'
}
data = {
'wd': '迪丽热巴',
'sex': '女',
}
data = urllib.parse.urlencode(data).encode('utf-8')
print(url)
request = urllib.request.Request(url=url,headers=headers,data=data)
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
案例:爬取豆瓣Top250
import urllib.request
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.6261.95 Safari/537.36'
}
page = 25
for i in range(10):
url = f'https://movie.douban.com/top250?start={i*page}'
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
tree = etree.HTML(content)
alts = tree.xpath('//div[@class="item"]//img/@alt')
srcs = tree.xpath('//div[@class="item"]//img/@src')
for j in range(len(alts)):
urllib.request.urlretrieve(srcs[j], filename=f"./images/{alts[j]}.jpg")
requests模块的入门使用
requests的作用与安装
作用: 发送网络请求, 返回响应数据
安装: pip install requests
requests模块发送简单的get请求、获取响应
import requests
# 目标url
url = 'https://www.baidu.com'
# 向目标url发送get请求
response = requests.get(url)
# 打印响应内容
print(response.text)
response的常用属性:
* response.text 响应体str类型
* response.encoding 从HTTP header中猜测的响应内容的编码方式
* response.content 响应体bytes类型
* response.status_code 响应状态码
* response.request.headers 响应对应的请求头
* response.headers 响应头
* response.cookies 响应的cookie(经过了set-cookie动作)
* response.url 获取访问的url
* response.json() 获取json数据 得到内容为字典(如果接口响应体格式是json格式时)
* response.ok status_code<200返回True,大于200返回False
下载网络图片
import requests
url = 'https://up.enterdesk.com/edpic_source/da/c6/0e/dac60e3104fabefec3e0209990b55905.jpg'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'
}
response = requests.get(url,headers=headers)
with open('1.jpg', 'wb') as f:
f.write(response.content)
requests模块发送简单的post请求、获取响应
用法
response = requests.post(‘http://www.baidu.com/’,data = data,headers = headers)
data的形式: 字典
获取百度词典返回的结果
import requests
import json
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'
}
data = {
'kw': '你好'
}
response = requests.post(url=url,headers=headers,data=data)
content = response.content.decode('utf-8')
jsObj = json.loads(content)
print(jsObj)
print(jsObj['data'][0]['v'])
使用代理
为什么要使用代理
- 让服务器以为不是同一个客户端在请求
- 防止我们的真实地址被泄露,防止被追究
代理的用法
用法
requests.get(‘http://www.baidu.com’, proxies = proxies)
proxies的形式: 字典
例如
proxies = {
'http': 'http://12.34.56.78:9527',
'https': 'https://12.34.56.78:9527',
}
代理IP的分类
根据代理ip的匿名程度, 代理IP可以分为下面三类:
- 透明代理(Transparent Proxy): 透明代理的意思是客户端根本不需要知道代理服务器的存在, 但是它传送的仍然是真实的IP。使用透明代理时, 对方服务器是可以知道你使用了代理的, 并且他们也知道你的真实IP。
- 匿名代理(Anonymous Proxy): 匿名代理隐藏了您的真实IP, 但是向访问对象可以检测是使用代理服务器访问他们的。会改变我们的请求信息, 服务器端有可能会认为我们使用了代理。不过使用此种代理时, 虽然被访问的网站不知道你的ip地址, 但仍然可以知道你在使用代理, 当然某些能够侦测ip的网页也是可以查到你的ip。
- 高匿代理(Elite proxy或High Anonymity Proxy): 高匿名代理不改变客户机的请求, 这样在服务器看来就像有个真正的客户浏览器在访问它,这时客户的真实ip是隐藏的, 完全用代理服务器的信息替代了您的所有信息, 同时服务器端不会认为我们使用了代理。
代码配置
urllib
handle = urllib.request.ProxyHandler({'http': '114.215.95.188:3128'})
opener = urllib.request.build_opener(handler)
# 后续都使用opener.open方法去发送请求即可
requests
# 用到的库
import requests
# 写入获得到的ip地址到proxy
# 一个ip地址
proxy = {
'http': 'http://221.178.232.130:8080'
}
"""
# 多个ip地址
proxy = [
{'http': 'http://221.178.232.130:8080'},
{'http': 'http://221.178.232.140:8080'}
]
import random
proxy = random.choice(proxy)
"""
# 使用代理
result = requests.get('http://httpbin.org/ip', proxies=proxy)
print(result.text)
案例
爬取笔趣阁小说
import requests
from lxml import etree
def download(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0'
}
response = requests.get(url=url, headers=headers)
print(response)
tree = etree.HTML(response.text)
data = tree.xpath('//div[@id="chaptercontent"]/text()')
with open('1.html', 'a', encoding='utf-8') as f:
for i in range(len(data)):
f.write(data[i])
f.write('\n')
f.close()
if __name__ == '__main__':
for i in range(1,10):
url = f'https://www.bqka.cc/book/3315/{i}.html'
download(url)
使用cookies参数接收字典形式的cookie
cookies的形式: 字典
cookies = { “key”: “value”}
使用方法
requests.get(url, headers=headers, cookies=cookies)
使用requests.session处理cookie
requests提供了一个叫做session类, 来实现客户端和服务端的会话保持
会话保持有两个内涵:
- 保存cookie, 下一次请求会带上前一次的cookie
- 实现和服务端的长连接, 加快请求速度
使用方法
session = requests.session()
response = session.get(url, headers)
session实例在请求了一个网站后, 对方服务器设置在本地的cookie会保持在session中, 下一次在使用session请求对方服务器的时候, 会带上前一次的cookie
小结
- cookie字符串可以放在headers字典中, 键为Cookie, 值为cookie字符串
- 可以把cookie字符串转化为字典, 使用请求方法的cookies参数接收
- 使用requests提供的session模块, 能够自动实现cookie的处理, 包括请求的时候携带cookie, 获取响应的时候保存cookie
requests模块的其他方法
requests中cookieJar的处理方法
使用request获取的response对象, 具有cookies属性, 能够获取对方服务器设置在本地的cookie, 但是如何使用这些cookie呢?
方法介绍
- response.cookies是CookieJar类型
- 使用requests.utils.dict_from_cookiejar, 能够实现把cookiejar对象转化为字典
方法展示
import requests
url = 'http://www.baidu.com'
# 发送请求, 获取response
response = requests.get(url)
print(type(response.cookies))
# 使用方法从cookiejar中提取数据 等同于 dict(response.cookies)
cookies = requests.utils.dict_from_cookiejar(response.cookies)
print(cookies)
requests处理证书错误
import requests
url = 'https://www.12306.cn/mormhweb/'
response = requests.get(url, verify = False)
超时参数的使用
使用方法
response = requests.get(url, timeout=3)
注意:
这个方法还能够拿来检测代理ip的质量, 如果一个代理ip在很长时间没有响应, 那么添加超时之后也会报错, 对应的这个ip就可以从代理ip池中删除
retrying模块
retrying模块的使用
retrying模块的地址: https://pypi.org/project/retrying/
pip install retrying
retrying模块的使用
- 使用retrying 模块提供的retry模块
- 通过装饰器的方式使用, 让装饰器的函数反复执行
- retry中可以传入函数stop_max_attempt_number, 让函数报错后继续重新执行、达到最大执行次数的上限, 如果每次都报错, 整个函数报错, 如果中间有一个成功, 程序继续执行
# parse py
import requests
from retrying import retry
headers = {}
# 最大重试3次, 3次全部报错, 才会报错
@retry(stop_max_attempt_number=3)
def _parse_url(url):
# 超时的时候会报错并重试
response = requests.get(url, headers, timeout=3)
# 状态码不是200, 也会报错并重试
assert response.status_code == 200
return response
def parse_url(url):
try:
response = _parse_url(url)
exception Exception as e:
print(e)
response = None
return response
扩展
kwargs: 控制访问的参数, 均为可选项
- params: 字典或字节序列, 作为参数增加到url中
- data: 字典, 字节序列或文件对象, 作为Request的内容
- headers: 字典, HTTP定制头
- timeout: 设定超时时间, 秒为单位
- proxies: 字典类型, 设定访问代理服务器, 可以增加登录认证
- verify: True/False默认True, 认证ssl证书开关