- 论文标题:《Communication-Efficient Learning of Deep Networks from Decentralized Data》从分散数据中进行深度网络的通信高效学习
- 发表年份:2017年
- 发表会议:Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS 2017)
Abstract
为了解决分布式的大量数据由于隐私性,不容易使用常规方法进行训练,论文提倡一种替代方案,将训练数据分布在移动的设备上,并通过聚合本地计算的更新来学习共享模型。我们将这种分散的方法称为联邦学习。
使用 5 种模型和 4 种数据集 进行评估,该方法对不平衡和非独立同分布的数据( unbalanced and non-IID data )具有 鲁棒性 与 同步随机梯度下降(synchronized stochastic gradient descent)相比,此方法所需的通信轮次减少了10-100倍
鲁棒是 Robust 的音译,也就是健壮和强壮的意思。它是在异常和危险情况下系统生存的能力
1 Introduction
我们研究了一种学习技术,该技术允许用户集体获得从这些丰富数据中训练的共享模型的好处,而无需集中存储它。每个客户端都有一个本地训练数据集,它永远不会上传到服务器。相反,每个客户端计算对服务器维护的当前全局模型的更新,并且仅传递此更新
这种方法的主要优点是 将模型训练与直接访问原始训练数据的需求解耦。但仍然需要对协调训练的服务器有一定的信任。然而,对于可以根据每个客户端上的可用数据指定训练目标的应用程序,联邦学习可以通过将攻击面限制在设备上而不是设备和云之间,这样 显著降低了隐私和安全风险。
贡献:
- 识别来自移动的设备的分散数据的训练问题作为一个重要的研究方向
- 选择一个简单实用的算法,可以应用于此设置
- 所提出的方法的广泛的实证评估
更具体地,我们引入了 Federated Averaging 算法,该算法将每个客户端上的局部随机梯度下降(SGD)与 执行模型平均的服务器相结合
联邦学习的理想问题:
联邦学习的理想问题具有以下属性:
1)在来自移动的设备的真实数据上进行训练,与在数据中心通常可用的代理数据上进行训练相比,具有明显的优势
2)这些数据是隐私敏感的,或者数据量很大(与模型的大小相比),因此最好不要将其记录到数据中心,纯粹用于模型训练(服务于集中收集原则)
3)对于监督任务,数据上的 标签(label)可以从用户交互中自然推断出来
(注:FedAvg 的监督是有标签的 监督学习)
Federated Optimization:
Federated Optimization(联邦优化)特点:
1)Non-iid
给定客户端上的训练数据通常基于特定用户对移动终端的使用,因此任何特定用户的本地数据集将不代表群体分布
2)Unbalanced
一些用户会比其他用户更频繁地使用服务或应用程序,导致本地训练数据的数量不同
3)Massively distributed
我们期望参与优化的客户端数量远大于每个客户端的平均示例数量。
4)Limited communication
移动的设备经常离线或连接速度慢或连接费用高。
联邦优化要解决无数 实际问题,例如:
- 客户端数据集随着数据的增加和删除而变化
- 客户端的可用性以复杂的方式与本地数据分布相关联(例如,使用美国英语的手机可能在不同的时间被插入电源,而不是使用英国英语的手机)
- 从不响应或发送损坏更新的客户端
但是作者说这些问题超出了当前工作的范围,所以本文使用一个适合实验的受控环境,仍然解决了客户端可用性、不平衡和 non-IID 数据的关键问题
(紧接着给出了方案)↓
联邦学习过程:
我们假设一个同步更新方案,该方案通过通信轮次进行
有一个固定的 K 个客户端,每个客户端都有一个固定的本地数据集。在每一轮的开始,随机选择 C 比例的客户端,服务器将当前的全局算法状态发送给这些客户端(例如,当前的模型参数)我们只选择一部分客户端以提高效率
因为我们的实验表明,超过某个点之后增加更多客户端的收益会递减
然后,每个选定的客户端根据全局状态和其本地数据集进行本地计算,并向服务器发送更新。服务器随后将这些更新应用于其全局状态,然后重复该过程
成本问题:
在数据中心优化中,通信成本相对较小,计算成本占主导地位,最近的重点是使用 GPU 来降低这些成本
相比之下,在联邦优化中,通信成本占主导地位——我们通常会受到1 MB/s或更少的上传带宽的限制
此外,我们预计每个客户端每天只会参与少量的更新轮。另一方面,由于任何单个设备上的数据集与总数据集大小相比都很小,并且现代智能手机具有相对快速的处理器(包括 GPU),因此与许多模型类型的通信成本相比,计算基本上是免费的。
因此,我们的目标是使用额外的计算,以减少训练模型所需的通信轮数
增加额外计算的方法:
1)increased parallelism
增加并行性,我们使用更多的客户端在每个通信回合之间独立工作
2)increased computation on each client
每个客户端在每个通信回合之间执行更复杂的计算,而不是执行类似梯度计算的简单计算
2 The FederatedAveraging Algorithm
FedSGD 基线算法:
在联邦学习设置中,增加更多客户端在实际时间上的成本很小,因此我们使用大批量同步随机梯度下降(SGD)作为基线。为了将这种方法应用于联邦学习环境,我们在每一轮中选择 C 比例的客户端,并计算这些客户端持有的所有数据的损失梯度
因此,C 控制了全局批量大小,C = 1 对应于全批量(非随机)梯度下降。我们将这种基线算法称为 FederatedSGD(或 FedSGD)



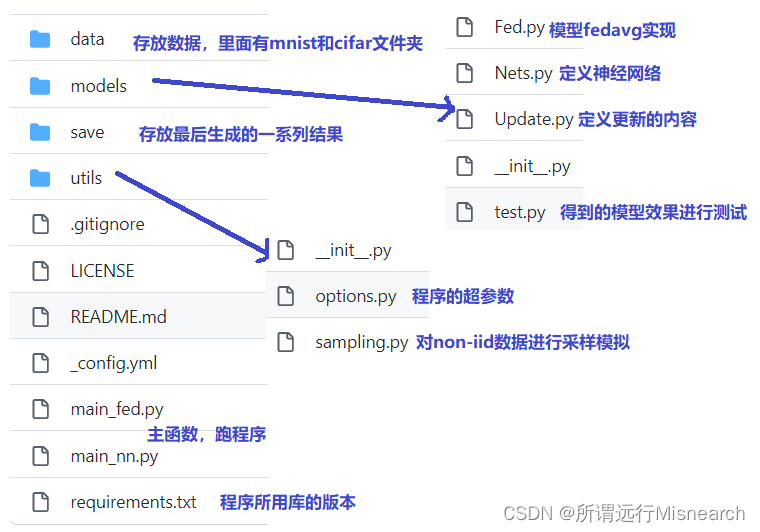
代码

当一个文件夹中含有" __init_.py "文件时,代表是一个 python 软件包
models
Fed.py
import copy
import torch
from torch import nn
def FedAvg(w):
w_avg = copy.deepcopy(w[0])
for k in w_avg.keys():
for i in range(1, len(w)):
w_avg[k] += w[i][k]
w_avg[k] = torch.div(w_avg[k], len(w))
return w_avgcopy
- 浅拷贝(Shallow Copy):创建一个新对象,其内容是原始对象中对象的引用。如果原始对象包含对其他对象的引用,则拷贝后的对象也会引用这些相同的对象
- 深拷贝(Deep Copy):创建一个新对象,并且递归复制对象中的所有内容。深拷贝会创建原始对象的完全独立副本,修改副本不会影响原始对象
Nets.py
import torch
from torch import nn # neural network nn模块
import torch.nn.functional as F
class MLP(nn.Module): # 继承 torch.nn.Module,这是在 PyTorch 中定义所有神经网络模块的基类
def __init__(self, dim_in, dim_hidden, dim_out): # dimensionality 维度,输入层,隐藏层,输出层
super(MLP, self).__init__() # 调用父类构造函数
self.layer_input = nn.Linear(dim_in, dim_hidden) # 创建一个线性层(nn.Linear),它将输入维度 dim_in 映射到隐藏层维度 dim_hidden
self.relu = nn.ReLU() # 创建一个 ReLU(Rectified Linear Unit)激活函数层,用于在 layer_input 之后引入非线性
self.dropout = nn.Dropout() # 创建一个 dropout 层,用于在训练过程中随机丢弃一些神经元的输出,以减少过拟合
self.layer_hidden = nn.Linear(dim_hidden, dim_out) # 创建第二个线性层,将隐藏层的输出维度 dim_hidden 映射到输出层维度 dim_out
# 前向传播
def forward(self, x):
# 将输入 x 重塑为一个二维张量,其中 -1 表示自动计算第一个维度的大小,第二个维度是输入张量所有其他维度的乘积
x = x.view(-1, x.shape[1]*x.shape[-2]*x.shape[-1])
x = self.layer_input(x) # 将输入 x 通过第一个线性层
x = self.dropout(x) # 将 dropout 应用于第一个线性层的输出
x = self.relu(x) # 将 ReLU 激活函数应用于 dropout 的输出,引入非线性
x = self.layer_hidden(x) # 将 ReLU 激活后的输出通过第二个线性层
return x # 返回网络的最终输出
class CNNMnist(nn.Module):
def __init__(self, args):
super(CNNMnist, self).__init__()
self.conv1 = nn.Conv2d(args.num_channels, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, args.num_classes)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, x.shape[1]*x.shape[2]*x.shape[3])
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return x
class CNNCifar(nn.Module):
def __init__(self, args):
super(CNNCifar, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, args.num_classes)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
utils
options.py
用来存放程序的一些超参数的值,方便在程序运行过程中直接调节
sampling.py
用来对 Non-IID 的数据分布进行采样的模拟
def mnist_iid(dataset, num_users):
"""
Sample I.I.D. client data from MNIST dataset
:param dataset:
:param num_users:
:return: dict of image index 返回一个包含图像索引的字典,key 值是用户 id,values 是用户拥有的图片 id
"""
num_items = int(len(dataset) / num_users) # 计算每个客户端应该获得的数据项数
dict_users, all_idxs = {}, [i for i in range(len(dataset))]
for i in range(num_users): # 对于每个客户端:
dict_users[i] = set(np.random.choice(all_idxs, num_items, replace=False)) # 这里使用 np.random.choice 函数
# 从 all_idxs 中随机选择 num_items 个不重复的索引,并将它们作为集合赋值给 dict_users[i]。replace=False 表示不允许重复选择,
# 确保每个客户端获得的数据唯一
all_idxs = list(set(all_idxs) - dict_users[i]) # 在为当前客户端采样数据后,更新 all_idxs,移除已经被当前客户端采样的索引,
# 以确保下一个客户端不会获得重复的数据
# 使用了集合减法
return dict_users
def mnist_noniid(dataset, num_users):
"""
Sample non-I.I.D client data from MNIST dataset
:param dataset:
:param num_users:
:return:
"""
num_shards, num_imgs = 200, 300 # num_shards 数据集被分成的碎片数量
# num_imgs 每个碎片中的图像数量
idx_shard = [i for i in range(num_shards)] # 碎片的索引
dict_users = {i: np.array([], dtype='int64') for i in range(num_users)}
idxs = np.arange(num_shards * num_imgs) # 所有图像的索引
labels = dataset.train_labels.numpy() # 将 MNIST 数据集中的训练标签转换为 NumPy 数组
# sort labels
idxs_labels = np.vstack((idxs, labels)) # 垂直堆叠成一个二维数组
idxs_labels = idxs_labels[:, idxs_labels[1, :].argsort()] # 根据标签对图像索引进行排序
idxs = idxs_labels[0, :] # 选择 idxs_labels 数组的第一行,即图像索引的排序结果
# divide and assign
# 分划和分配
for i in range(num_users):
# 从 idx_shard 数组中随机选择 2 个不同的元素,不允许重复选择
rand_set = set(np.random.choice(idx_shard, 2, replace=False))
idx_shard = list(set(idx_shard) - rand_set) # 将 rand_set 中的元素从 idx_shard 中移除
for rand in rand_set:
# 沿着 axis=0(行)拼接数组
dict_users[i] = np.concatenate((dict_users[i], idxs[rand * num_imgs:(rand + 1) * num_imgs]), axis=0)
return dict_users
# 与 mnistiid 一样
def cifar_iid(dataset, num_users):
"""
Sample I.I.D. client data from CIFAR10 dataset
:param dataset:
:param num_users:
:return: dict of image index
"""
num_items = int(len(dataset) / num_users)
dict_users, all_idxs = {}, [i for i in range(len(dataset))]
for i in range(num_users):
dict_users[i] = set(np.random.choice(all_idxs, num_items, replace=False))
all_idxs = list(set(all_idxs) - dict_users[i])
return dict_usersI.I.D. (Independent and Identically Distributed) 采样
- 定义:每个客户端获得的数据是完全独立且同分布的,即数据在客户端之间随机分配,且每个客户端获得的数据集具有相同的分布特性。
- 实现方式:
- 每个客户端获得相同数量的数据项(
num_items)。 - 使用
np.random.choice函数从所有数据索引中随机选择不重复的索引,确保每个客户端获得的数据是唯一的。 - 通过集合操作移除已经被分配的数据索引,避免数据重复。
- 每个客户端获得相同数量的数据项(
Non-I.I.D. 采样
- 定义:非独立同分布,即客户端获得的数据可能在分布上存在差异,例如,某些客户端可能获得更多某类标签的数据。
- 实现方式:
- 数据集被预先分成多个碎片(
num_shards),每个碎片包含一定数量的图像(num_imgs)。 - 客户端随机选择一些碎片索引,但每次选择两个,且不允许重复。
- 客户端获得的数据是所选碎片中图像的索引,这些图像的标签可能不是均匀分布的。
- 数据集被预先分成多个碎片(



























![AGI 之 【Hugging Face】 的【零样本和少样本学习】之二 [零样本学习] / [ 少样本学习 ] 的简单整理](https://i-blog.csdnimg.cn/direct/56f6c0b77975450b9041f971acaf4a39.jpeg)


