摘要
这一周对李宏毅机器学习内容进行了更进一步的学习,学习了机器学习任务攻略。此外还对贝叶斯定理进行了更进一步的拓展学习,加深了对贝叶斯定理的理解。最后对Pytorch进行了学习,学会使用了Tensorboard。
Abstract
This week, I further studied Li Hongyi’s machine learning content and learned about machine learning task strategies. In addition, further extended learning was conducted on Bayes’ theorem, deepening the understanding of Bayes’ theorem. Finally, I learned Pytorch and learned how to use Tensorboard.
机器学习任务攻略
通过下图,回顾一下机器学习的三步骤:

简单的执行,只能让结果刚好到平均偏上的水平。我们肯定要让结果做的更好,我们要怎么办?
如下图所示:
如果我们感觉自己的训练结果不好,我们可以按照如下攻略进行优化。
1.loss on training data
1、检查我们的training data的loss
为什么不是看testing data的loss?
因为要看training data有没有学起来,因为training data的Loss过大证明没有训练好,更别谈再测试集中的表现了,所以之后再看testing data的Loss。
1.1 training data的loss过大怎么办?
造成loss过大,有两个可能
第一个可能:Model bias(模型偏差)
Model bias的意思就是模型过于简单,需要将你的模型复杂化
假如我们设计了一个简单的model,对于不同的θ输出不同的值,把所有的值组合成一个set(集合)后,即便我们找到在这个集合范围里面最佳的θ*使得Loss变得小,但是离我们的small loss还是相差很远,这就是模型过于简单带来的劣势。
就好比如:
在大海里面捞针本来就是一件很难的事情,可是针并不在大海上,所以做再多努力也无法找到一个small loss。

解决方法:需要重新设计我们的模型,使我们的简单模型复杂化
方式1:就是增加更多的feature(特征,即x输入)
从我们学习周报第一周的视频观看人数的例子中就可以看出来,更多的feature能够有效的减少Loss值第一周学习周报链接–点击进入
方式2:增加更多的neurons(神经元)和layers(层数)
例如,增加一个sigmoid函数运算;将这一层的输出作为下一层的输入增加层数。

第二个可能:optimization(最佳化)做的不好
在第一周学习时候,我们就知道我们是通过Gradient Descent(梯度下降)来完成optimization的,但是会存在local minima和global minima,我们所找到随机初始点不同,得到的local minima是不一样的
就好比如:我们在大海捞针,针确实在海里,但是我们捞不出来

那么当我们的Loss过大时,如何确定是哪一种情况呢,是Model Bias还是Optimization?

方式1:比较不同和的Model
通过比较不同的Model来判断是否存在Model Bias的问题。
从下图中,我们可以清楚的看到20层比56层在测试集上的Loss更低,难道这是overfitting吗?
很显然不是
因为overfitting是,在训练集上表现的很好,但是在测试集上表现的很差。
所以,再比较Training data中的Loss 发现20层比56层在测试集上的Loss更低。
很显然,其Loss偏大是由于Optimization造成的。

那么我们如何更好的判断Optimization issue呢?
我们可以从更浅层次的network或者其他更简单的模型(例如:linear model)开始optimize,因为这些更浅层次和更简单的model可以更加容易的去优化,先确定大致的情况
然后在更深层次的network中我们如果得到的loss不降反升,就证明是Optimization issue。
比如,下图中的一栏数据,5层比4层在training data的loss还要高,就证明是Optimization issue。

1.2 training data的loss过小,但是testing data loss大怎么办?
造成这种情况有两种可能:过拟合和Mismatch
Mismatch指的是训练集和测试集有着不同分布(一般不常见,所以不讨论)
接下来再重点学习一下overfitting(过拟合)
再次强调,overfitting是,在训练集上表现的很好,但是在测试集上表现的很差。是在训练集和测试集上的事情
导致overfitting的情况如下:
1、模型问题
举一个比较极端的例子:
假如,我们找到了一个一无是处的function,遇到对应的x输出真实值y,否则则随便输出一个值。
那在训练集中,肯定是100%正确率的
就是好像平时训练,你看着试卷的答案,你再写出来
但在测试集中,表现结果会非常糟糕
就比如你一直作弊,考试就寄了
这种模型很显然就会导致过拟合

2、training data太少
比如,我们正确的曲线如下图左边所示
但是我们训练集只有三个,即便我们的model很强很厉害,但在这三点之外,这个model制作的图像可能就会天马行空,完全脱离了testing data,就会导致testing data的Loss很大

3、模型过于复杂
如下图情况中,随着模型越来越复杂 training data的loss一直降低,但是testing data的loss过了一个点会一直升高。

解决overfitting方法:
一、简化模型
因为造成overfitting很可能是模型过于复杂导致的。
简化模型的方式:给模型增加更多的限制
就比如这个情况,我们假设已知是二元二次方程,我们给model添加限制后,过这三个点的曲线只能是这样的。

添加限制可以用如下方法:
1、减少变量数量,共享变量
2、更少的features(特征)
3、早停法(Early Stopping)
Early Stopping是一种训练技术,旨在监控模型在验证数据集上的性能,以决定是否继续训练。
当模型的验证性能停止提升,或者甚至开始下降时,训练过程将被终止。
这种技术可以防止模型在训练数据上过拟合,从而提高模型的泛化性能。
4、Regularization(正则化,前面周报有提到)
5、Dropout层(深度学习CNN内容,通过Dropout层可以减少过拟合)
注意:有些概念后续会在深度学习进行补充,现在了解即可

但是过多的限制不是好事,如下图所示:
如果我们限制在一个二元一次方程(直线),永远也没有一条直线可以通过这三个点,于是就会找距离这三个点最近的直线,导致训练集和测试集的表现效果都很差,又会回到model bias问题

二、增加更多训练集数据(data augmentation)(如果训练的是图片可以将图片左右翻转)因为training data过少会导致过拟合现象,因为很可能有发生个例当成普遍的错误,从而在testing data中表现很差。

2. 如何选择一个中最好的模型?
随着模型越来越复杂 training data的loss一直降低,但是testing data的loss过了一个点会一直升高那么我们怎么找到一个最佳的model(就比如找到下图中的点),让其loss最小呢?

假设我们有三个模型,他们的复杂的程度不太一样,我不知道选哪一个模型才会刚刚好在测试资料上得到最好的结果。因为你选太复杂的就会导致overffting,太简单的有model bias的问题。
那怎么选一个不偏不倚的的模型呢?
把这三个模型的结果都跑出来。然后上传到kaggle上面,你及时的知道了你的分数,看看哪个分数最低,那个模型显然就是最好的模型。但是并不建议你这么做
Kaggle 是一个面向数据科学和机器学习爱好者的在线平台
它提供了一个用于数据科学竞赛、数据集分享和模型训练的环境。
为什么不建议你这么做呢?
我们举一个极端的例子,我们再把刚才那个极端的例子拿出来,假设现在有一群model。这一群model不知道为什么都非常费他们每一个model产生出来的都是一无是处的方式。
这一到1M的model,他们会做的事情都是:训练资料里面有的就记录下来,没有的就Random值
你再把这1M个模型的结果上传到kaggle上面,你就得到1M的分数,然后这1M的分数里面哪一个结果最好,你就觉得那个模型是最好的。所以也许编号56789的那一个模型,它找出来的方式正好在testing data上面,就给你一个好的结果。
但是如果你这样做,往往就会得到非常糟的结果

因为这个model有些结果毕竟是随机的,它恰好在test public的testing set上面得到一个好结果。但是private testing set的结果可能仍然是随机的。
为什么分成public跟private?为什么我们不能就通通都分public?
你仔细想想看,假设所有的 testing set都是public。刚刚算是一个一无是处的model,得到的一无是处的function,它也有可能在public的testing set上面得到好的结果。
如果我们今天只有public没有private
那你就回去写一个方程,该方程不断random产生输出就好,然后不断把这些众多model上传到kaggle,然后看你什么时候可以认得出一个好的结果,那就结束了,那这个显然没有意义,显然不是我们要的。

2.1 Cross Validation(交叉验证)
那到底要怎么做才选择才是比较合理的呢?
我们就需要用到Cross Validation(交叉验证)
可以把training的资料分成两部分:
一部分叫做training set,另一部分叫做validation set(校验集)
90%的资料用于training set里面,有10%的资料会被拿来做validation set。
验证集可以防止过拟合。
通过验证集,开发者可以调整模型参数、选择模型结构和进行超参数优化。
验证集与训练集相互独立,但与测试集相似,通常包含较训练集少一些的样本,以便更快地评估模型。
验证集的表现作为参数调整和模型选择的依据,帮助选择最佳的超参数和模型结构。
此外,验证集还能提供一个信号,即在模型开始过拟合时提供一个停止优化的信号,因为当验证集上的性能开始下降时,通常意味着模型已经开始过度适应训练数据,而忽略了新数据的泛化能力
在training set训练出来的模型,用validation set去衡量分数。
validation set去衡量的结果。上传到kaggle上面去看看你得到的它的分数。
那因为你在挑分数的时候是用validation state来挑model,所以在public上的testing set分数就可以反映你的private上的testing set分数。
就不会得到在public上面结果很好。但是在private上面结果很差的状况。

2.2 N-fold Cross Validation(N倍交叉验证法)
但是这边会有一个问题,就是怎么分training set呢?可能搞不好我分到很奇怪的validation。
那么就需要用到N-fold Cross Validation(N倍交叉验证法)
切成n等份啊,在这个例子里面呢,我们切成三等份,切完以后你拿其中一份当做validation set。另外两份当做训练集
然后这件事情你要重复三次。
也就是说,你先第一、二份当trian,第三份当Val。
然后第一、三份当train,第二份当val
以此类推

然后接下来有三个模型。你不知道哪一个是好的,要怎么做呢?
如下图所示:
把这三个模型在这三个设置下,在这三组training跟validation的data set在上面通通跑一次。
然后把这三个模型在这三种状况的结果都平均起来,把每一个模型在这三种状况的结果都平均起来,再看看谁的结果最好。
假设用这3-fold得出来的结果是这个Model 1最好,就把Model 1用在全部的training set上。
最后将Model 1训练出来的模型才用在testing set上

至此机器学习的攻略就到此结束。
拓展专题——贝叶斯
在上一周的机器学习中,我们在二分类问题中用到了贝叶斯公式,贝叶斯对于我们的Classification具有重大的作用,因此需要开一个拓展专题来研究一下贝叶斯。
1.什么是贝叶斯定理
举个不太恰当的例子:
比如说有一个家人,有父亲、母亲、和一个正在读初中的儿子
母亲有一天打扫房间卫生,发现儿子的房间多了一个打火机,于是她就会怀疑在小学的儿子是不是在外面结识了社会人士学会抽烟了。
出于对儿子的担心于是她咨询她的朋友,她的朋友是一名数学家,于是她的朋友告诉她就可以用贝叶斯定理来计算她儿子抽烟的几率有多大
她的朋友跟她说,
贝叶斯模型,主要有这几个重要组成部分:
1、先验概率:即根据先前的经验对事物产生初步的判断(可以理解为,根据自己的社会经验、生活经验判断儿子抽烟的概率有多大)
2、**接收新信息:**例如隔几天再看看儿子的房间有没有烟,或者衣服上有没有烟味
3、根据新信息更新对事物的判断:即根据2再去判断儿子抽烟的概率有多大,得出一个后验概率
所以这位母亲开始收集这些信息。
首先是先验概率: **如果这个打火机没有出现在儿子的房间,儿子抽烟的几率有多大。**这个问题肯定是不好估计的,于是母亲根据自己的见解和生活经验给出了答案:她觉得5%比较合适
然后 根据贝叶斯定理,
还需要有两个概率
1、如果儿子真的抽烟,那在儿子房间发现打火机的概率有多少?
2、如果儿子没有抽烟,那在儿子房间发现打火机的概率有多少?
对于1,母亲觉得其儿子是一个比较粗心的人,如果真的抽烟,在房间里遗落打火机的可能性很大,于是她将1的概率定为50%
对于2,也有合理的解释,是不是其父亲抽烟时候不小心把打火机留在耳机房间了,又或者儿子的打火机是外面捡到的,出于好奇心就带回家了。于是她将2的概率定为5%
接下来,我们把先验概率、概率1、概率2带入贝叶斯定理
P ( A i ∣ B ) = P ( A i ) P ( B ∣ A i ) ∑ j = 1 n P ( A j ) P ( B ∣ A j ) = P ( A i ) P ( B ∣ A i ) P ( A 1 ) P ( B ∣ A 1 ) + … + P ( A n ) P ( B ∣ A n ) P\left(A_{i} \mid B\right)=\frac{P\left(A_{i}\right) P\left(B \mid A_{i}\right)}{\sum_{j=1}^{n} P\left(A_{j}\right) P\left(B \mid A_{j}\right)}=\frac{P\left(A_{i}\right) P\left(B \mid A_{i}\right)}{P\left(A_{1}\right) P\left(B \mid A_{1}\right)+\ldots+P\left(A_{n}\right) P\left(B \mid A_{n}\right)} P(Ai∣B)=∑j=1nP(Aj)P(B∣Aj)P(Ai)P(B∣Ai)=P(A1)P(B∣A1)+…+P(An)P(B∣An)P(Ai)P(B∣Ai)
具体计算如下:‘
可以看发现打火机的情况下,儿子抽烟的几率为34%,称之为后验概率,证明可能性是比较低的。
这是由于母亲相信耳机仅有5%可能性抽烟的先验概率前提下导致的

但是如果,出现了第二次这样的情况(即获取到了新信息,例如发现了烟,或者在衣服闻到烟味),这个概率就会随之改变。
于是我们把上一步得到的后验概率当作这一次的先验概率,来判断儿子是否抽烟,可得儿子抽烟的概率为84%

经过不断收集新的信息,又发现了儿子的可疑事件,,就可以基本上确认儿子抽烟了,即使她的母亲对其一开始就很信任。
这就是贝叶斯定理的原理:简单来说就是通过信息不断更新先验概率的过程
其实我们小时候听过的故事———狼来了,就很形象的描述了这一过程
《狼来了》寓言故事是出自古希腊伊索所著的《伊索寓言》中。
该故事讲述了一个放羊的孩子喜欢撒谎,两次通过告诉村里人说狼来了,骗取村民急忙赶来,而这个孩子还以此为乐。
村民们由于受骗而不再相信孩子的话,有一天,狼真来了,孩子呼救,没人相信,孩子的羊被狼吃光。
从贝叶斯定理我们可以看出,先验概率是无论是5%或者80%,只要们有足够多的证据,概率一定会收敛在事实附近
但是有一种情况是贝叶斯无法判断的,那就是极端情况,如下:

从这里我们可以得到些许反思,一个人不要有极端思想,否则,任何东西都输入不到你的观念中,从而变得狭窄落后,闭关锁国就是经典的例子。
贝叶斯定理在我们机器学习中有许多应用场景,如下:
1.自然语言处理:在自然语言处理中,贝叶斯公式用于求解语句中的概率关系,对语句进行分类和聚类,并预测语句可能的未来发展情况。这有助于实现理解、生成和检索等多种功能。
2.文本分类:贝叶斯方法可以用于识别、分类主题性文本,例如新闻报道分类或公司新闻等。
3.信用评分:在信用评分系统中,高斯朴素贝叶斯(GaussianNB)模型是一种广泛应用的机器学习算法。该模型基于朴素贝叶斯理论,假设特征之间相互独立,并且每个特征都服从高斯分布(正态分布)。例如,在银行构建的自动化的信用评分系统中,GaussianNB模型通过收集大量用户的信用数据,学习到各个特征与信用好坏之间的关系及其概率分布。
2. 贝叶斯公式模型的理解
在学习贝叶斯公式时,需要了解两个公式
1、全概率公式:
P ( B ) = P ( A 1 ) P ( B ∣ A 1 ) + P ( A 2 ) P ( B ∣ A 2 ) + P ( A 3 ) P ( B ∣ A 3 ) + . . . . + P ( A n ) P ( B ∣ A n ) P(B)=P(A_1)P(B|A_1)+P(A_2)P(B|A_2)+P(A_3)P(B|A_3)+....+P(A_n)P(B|A_n) P(B)=P(A1)P(B∣A1)+P(A2)P(B∣A2)+P(A3)P(B∣A3)+....+P(An)P(B∣An)
2、贝叶斯公式:
P ( A i ∣ B ) = P ( A i ) P ( B ∣ A i ) ∑ j = 1 n P ( A j ) P ( B ∣ A j ) = P ( A i ) P ( B ∣ A i ) P ( A 1 ) P ( B ∣ A 1 ) + … + P ( A n ) P ( B ∣ A n ) P\left(A_{i} \mid B\right)=\frac{P\left(A_{i}\right) P\left(B \mid A_{i}\right)}{\sum_{j=1}^{n} P\left(A_{j}\right) P\left(B \mid A_{j}\right)}=\frac{P\left(A_{i}\right) P\left(B \mid A_{i}\right)}{P\left(A_{1}\right) P\left(B \mid A_{1}\right)+\ldots+P\left(A_{n}\right) P\left(B \mid A_{n}\right)} P(Ai∣B)=∑j=1nP(Aj)P(B∣Aj)P(Ai)P(B∣Ai)=P(A1)P(B∣A1)+…+P(An)P(B∣An)P(Ai)P(B∣Ai)
3、联合概率公式(为了解释几个事件同时发生的概率,例如只有两个事件A、B):
P ( A , B ) = P ( A ∣ B ) ∗ P ( B ) = P ( B ∣ A ) ∗ P ( A ) P(A,B) = P(A|B)*P(B) = P(B|A)*P(A) P(A,B)=P(A∣B)∗P(B)=P(B∣A)∗P(A)
在这个基础上,我们用模型图来理解贝叶斯公式:

3. 朴素贝叶斯法(Naive Bayes model)
下面我们学习一下机器学习中经常提到的Naive Bayes model(朴素贝叶斯法)
朴素贝叶斯方法是在贝叶斯算法的基础上进行了相应的简化,即假定给定目标值时属性之间相互条件独立(没有哪个属性变量对于决策结果来说占有着较大的比重,也没有哪个属性变量对于决策结果占有着较小的比重。)
虽然这个简化方式在一定程度上降低了贝叶斯分类算法的分类效果,但是在实际的应用场景中,极大地简化了贝叶斯方法的复杂性。所以在机器学习中其算法可以用来处理大量的数据。
我们上面的2.1例子中,讲的都是一个特征判断一个事件(只通过是否有打火机来判断是否抽烟),假设我们有多个特征要怎么处理呢?
这个时候就要用到我们的朴素贝叶斯分分类算法,我们用一个买瓜的例子进行理解学习。



还有很多贝叶斯算法,因为时间有限,后续我们继续研究学习。
Pytorch——TensorBoard学习
1.TensorBoard的安装
使用TensorBoard有利于我们探究模型在不同阶段的输出。例如运行完一个方法之后,想要看看运行后的图像,就可以使用TensorBoard。
我们在pycharm中的terminal安装我们TensorBoard(也可以在anaconda进入pytorch环境安装)

输入,如下指令:
pip install tensorboard
显示如下图红框部分,证明安装成功

我们继续打开我们之前学习的learn_pytorch文件,并创建一个python文件(test_tb.py)

然后在里面输入如下内容
from torch.utils.tensorboard import SummaryWriter

按住ctrl + 鼠标左键点击SummaryWriter可以查看用法(也可以在控制台使用help()函数查看,但是Pycharm方便)
可以看到,这个SummaryWriter的作用就是,直接向一个文件夹(log_dir,也可以自己命名)写入一个事件文件,这个事件文件可以背TensorBoard解析。

然后下面就是其每个参数说明
最常用的是第一个(log_dir),就是保存文件的位置,其有默认的位置叫做保存目录位置。
默认值为runs/CURRENT_DATETIME_HOSTNAME(现在的时间以及主机名),它在每次运行后都会发生变化(因为时间是不断变化的)。

这里是使用的例子:
1、什么都不加,就会给个默认的命名以及位置(默认的事件文件就会保存在runs…那里)
2、对其初始化,就会保存在对应的位置
3、对其加入一些参数,例如:comment,后面就会加上对应的文字。
的其中图中的LR(Learning Rate)表示学习率; BATCH(Batch size,是指在训练神经网络时,一次提供给模型的数据的数量)
关于Batch size
在训练神经网络的过程中,模型需要对整个训练数据集进行训练,但由于数据集通常很大,如果一次把整个数据集提供给模型训练,可能会导致内存不足或运算时间过长
因此,我们通常将数据集分成若干个Batch,每次提供一个Batch给模型训练。Batch size就是指一个Batch中数据的数量。

了解了其用法后,我们就可以开始使用了。
写入如下代码:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs') #使用SummaryWriter,输出文件在logs
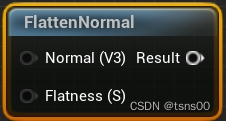
writer.add_image() #图片
writer.add_scalar() #数值
writer.close() #关闭
2. add_scalar()的使用
如果我们想要输出这样的loss图
我们可以使用其默认的输出图片方式,所以我们可以把write.add_image()注释掉
重点关注我们的writer.add_scalar()

可以看到,在add_scalar的使用说明中,有许多参数,例如:
tag:就是图片的标题
scalar_value:需要保留的数值(图片的纵轴(Y轴)值)
global_step:记录总共进行了多少步(图片的横轴(X轴)值)

scalar_value与global_step在图中效果所示:

我们在 test_tb python文件中输入:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs') # 使用SummaryWriter,输出文件在logs
writer.add_image() # 添加图片
#y=x图像
for i in range(100):
writer.add_scalar("y=x", i, i) # 第一个参数是tag、第二个参数是y轴值、第三个参数是x轴值
writer.close() # 关闭
运行后的结果:
可以看到生成了一个logs文件夹,里面就是刚刚生成的文件
接下来我们需要利用指令去打开它,在控制台新建一个local,再输入如下指令:
tensorboard --logdir=logs #logdir是事件文件所在文件夹名字
可以看到TensorBoard打开的窗口在主机的6006.

注意:主机名最好不用用英文,否则会出现编码错误
可以在设置–系统–重命名 进行改名,再重新运行程序

如果多人做训练,同时访问一个端口可能会引发错误,所以我们也可以通过参数设置,指定端口变成6007

我们访问这个网站,就可以看到我们做的图片了,我们可以点击下面的选项,来对图片进行操作


我们可以继续修改参数,画一个y=2x的图片:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs') # 使用SummaryWriter,输出文件在logs
# writer.add_image()
# y=2x
for i in range(100):
writer.add_scalar("y=2x", 2*i, i) # 第一个参数是tag、第二个是x
writer.close() # 关闭
图片如下:

但是,使用TensorBoard会造成一个问题
比如我们继续画一个y=3x的图片,但是不修改tag参数
for i in range(100):
writer.add_scalar("y=2x", 3*i, i) # 第一个参数是tag、第二个是x
会导致这样的情况,可以看到两个函数在拟合:


可以看到,我们使用write时,写入一个新的事件,其实也进入了上一个事件当中,就会出现上述情况。
遇到这种问题要怎么解决呢?
官方的建议是删掉原来的文件以及进程,再重新运行
(重新运行运行tensorboard --logdir=logs #logdir)
或者
把为每一个新的图像时候创建一个子文件夹
子文件,也就是创建新的SummaryWriter(“新文件夹”)

3. add_image()的使用
为了在里面写入图像,我们需要学习add_image()的使用
首先,先下载练手数据集,后解压重命名为data后,存放到pytorch项目文件中。
练手数据集下载地址(百度网盘):
https://pan.baidu.com/s/1jZoTmoFzaTLWh4lKBHVbEA 密码: 5suq

接下来,我们看看add_image()的用法。
可以看到image里面也有tag、img_tensor、step等等参数,都和上面的scalar差不多
其中,值得注意的是img_tensor,它规定的的格式有torch.Tensor、numpy.array或者字符串

接下来,我们输入如下代码进行运行:
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
writer = SummaryWriter('logs') # 使用SummaryWriter,输出文件在logs
image_path = "data/train/ants_image/0013035.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
writer.add_image("test", img_array, 1)
# y=2x
for i in range(100):
writer.add_scalar("y=2x", 2 * i, i) # 第一个参数是tag、第二个是x
writer.close() # 关闭
发现报了如下错误,是说TypeError: Cannot handle this data type(不能处理这类数据)

我们倒回到add_image()方法查看用法
可以看到,图片经过npy处理后是有格式的,分别为HWC排序,我们需要弄清楚我们这三个参数是怎么排序的,再加上dataformats='排序格式’的参数,再运行。

可以看到,我们的图片型式是HWC
 于是我们加上参数HWC(dataformats=‘HWC’)得
于是我们加上参数HWC(dataformats=‘HWC’)得
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
writer = SummaryWriter('logs') # 使用SummaryWriter,输出文件在logs
image_path = "data/train/ants_image/0013035.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
writer.add_image("test", img_array, 1, dataformats='HWC')
# y=2x
for i in range(100):
writer.add_scalar("y=2x", 2 * i, i) # 第一个参数是tag、第二个是x
writer.close() # 关闭
再在terminal上运行
tensorboard --logdir=logs --port=6007
运行结果:


我们修改python加入蜜蜂图片,再运行:
在Tensorboard刷新之后,再滑动圆轮至step2,就得到黄蜂图片

总结
这一周,继续对李宏毅机器学习进行了学习,了解了机器学习的任务攻略图,其中学会了training data的loss偏大的情况下,判断是model bias还是optimization问题。又对overfitting进行深度的学习。最后还学会了如何利用Cross Validation与N-fold Cross Validation挑选Model。紧接着还学习了贝叶斯专题,更深层次的理解了贝叶斯定理,从抽烟概率的例子和贝叶斯图像模型的角度深度理解了贝叶斯定理的含义,以及用贝叶斯思维引申出后面值得深思的问题,然后还对机器学习常用的朴素贝叶斯定理进行了学习,主要是为了解决多特征的分类问题。最后还学习了Pytorch中TensorBoard的运用,其中因为系统中文名(微软自动设置的)导致了很多package的安装产生了编码和路径错误,后面对系统进行了重装花费了大量的时间,因为上个星期没有学习Pytorch,所以这个星期无论如何都要辛苦的肝一下,这次学会了add_image()与add_scalar()函数的使用,以及图像展示,为接下来的训练做准备。
下一周计划继续对机器学习视频进行学习,然后继续学习Pytorch的transform使用。