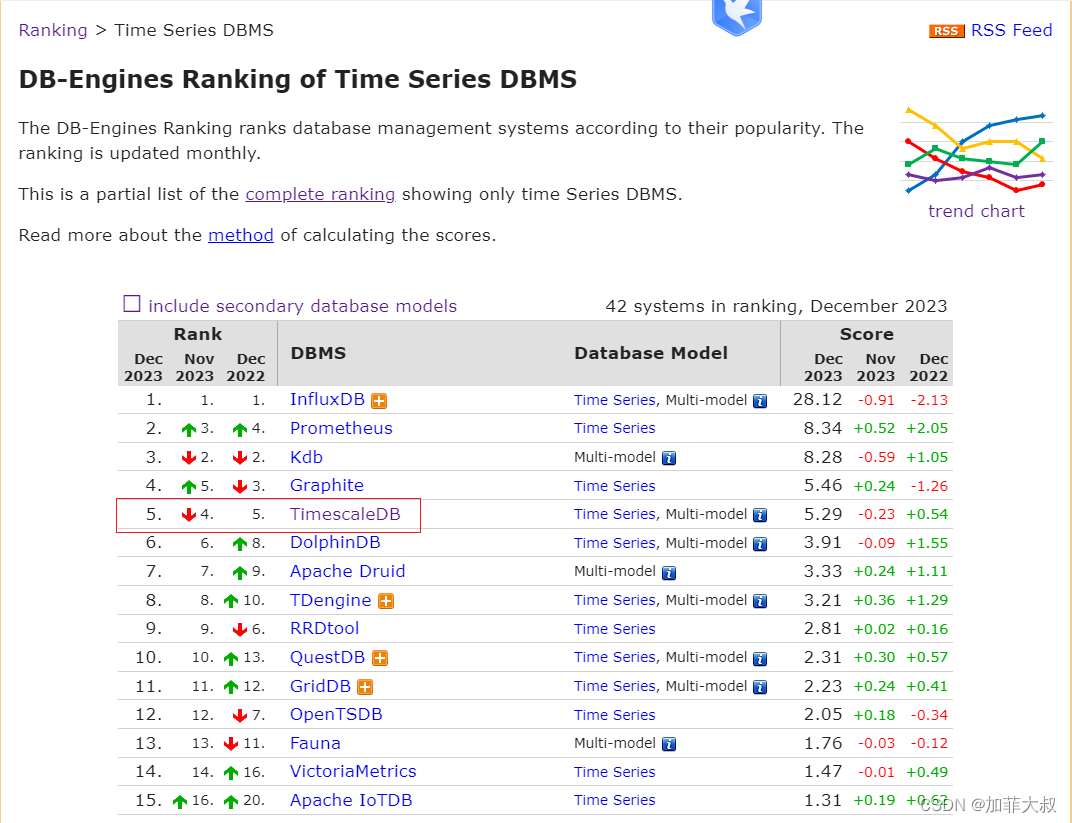
工业物联网场景,如何判断什么才是好的时序数据库?
工业物联网将机器设备、控制系统与信息系统、业务过程连接起来,利用海量数据进行分析决策,是智能制造的基础设施,并影响整个工业价值链。工业物联网机器设备感知形成了海量时间序列数据(带时间标签的数据,每条时间序列是按时间戳顺序存贮的一组数据点),蕴含丰富的工业语义,是工业大数据的规模与价值主体。
为应对海量工业物联网数据管理,更好地实现工业数字化、智能化发展,专门管理时序数据的时序数据库产品应运而生。那么如果需要使用时序数据库,该如何衡量时序数据库的性能表现?好用的时序数据库,又该满足哪些条件?本文将梳理时序数据库的性能选型标准,供大家参考。
01 时序数据管理难点
时序数据库的选型标准,跟时序数据本身处理的难点是息息相关的。
(1)软件技术挑战
工业生产涉及的设备数量庞大,常见的业务场景中包含数万到数百万个设备,而单设备的传感器数量也可能很多,每一个传感器上报对应的指标/测量值(比如温度、速度等等),最终上报时序数据的测点(也就是指标/测量值的数量)可能达到几十万、上百万,甚至亿级,还会随着业务扩展动态地继续增加。
同时,时序数据的采样频次可能很高,实际应用中可能达到毫秒级的上报。设备多、测点多、采样频次高,这就导致时序数据的体量是非常庞大的,存储的成本也就随之增加,而且因为业务的需要,经常需要实现历史数据长期的存储。
(2)工业特色需求
工业物联网业务背景也催生了与工业应用强相关的特性需求。测点层级管理成为工业领域使用时序数据库的功能需求之一。这意味着时序数据库需要能够处理从集团、厂站、系统、设备到传感器等不同层级的测点数据,并能够实现这些数据的有效组织和管理,让企业可以方便地对应到数据产生的不同层级。
此外,端边云数据协同也是时序数据库在工业应用中的关键需求。因为工业设备的部署状态与边缘计算的兴起,数据不再只是从设备端直接传输到集团云端,而是在厂站或省域的边缘节点进行初步处理和分析,再向云端进行同步。这种协同机制能够充分利用边端算力,节省云端带宽成本。因此,时序数据库需要确保数据在不同终端之间能够顺畅协同,从而实现更加智能和高效的工业管理。
02 基本能力:写入、压缩、查询、分析
了解了上述的时序数据管理难点,再结合时序数据库应用的主要业务场景,也就是针对工业大数据智能管理转型所衍生的状态监控、故障告警、数字画像等等,选型时需要注重的性能指标主要包括以下几项:
(1)写入吞吐
第一是写入吞吐,也就是单位时间内成功写入时序数据的量,这个值越大代表同样时间内能写入的数据量越大。体量庞大的时序数据,需要保障其能够全量写入时序数据库,不产生数据丢失,同时需要保障自带强时间属性的低频时序数据和高频时序数据的写入实时性。实际场景中,时序数据库的高通量写入性能需要达到百万或千万数据点/秒。
(2)压缩比
第二是压缩比,也就是原始数据量除以磁盘存储空间的值,这个值越大代表数据库的压缩性能越好。时序数据量庞大会很容易导致磁盘空间占用很高,而能够实现高压缩比的时序数据库,同样的数据量占用的空间、需要的存储成本也就越小。实际场景中,时序数据库的压缩比需要达到至少 20 倍以上,在企业对比数据存储成本时会更加有竞争力。
(3)查询耗时及分析能力
第三是查询耗时及分析能力,耗时越短、分析能力越强,也就代表着企业能够更快地获知所需的数据结果,并进行更多样的深度挖掘。实际应用中,对于最新值查询、聚合查询等业务常用场景,时序数据库的查询延迟需要控制在毫秒级。在保障海量数据处理低延迟的基础上,时序数据库还需要支持数据计算、查看数据走向、数据缺失修复等分析功能。
03 挑战需求:面向工业物联网进行优化
上述指标能够让时序数据库实现工业数据管理的基本需求,而面对工业物联网场景的需求特性,更好的时序数据库可以实现为工业物联网“量身定制”的适配架构及功能。
(1)测点建模
工业时序数据常常是按照类似“集团-省域-厂站-产线-设备-传感器”的层级彼此关联起来的,而因为数据量庞大、层级多,管理的时候存在天然的困难度。因此,在数据建模方面,时序数据库应该在保证存储规模的前提下,实现与工业场景中的层级相对应的数据结构,并能够做到以采集、应用等团队的不同视角,实现对数据结构按设备地点、分析应用的多面组织管理,以减少企业的学习、理解成本。
(2)数据同步
工业设备常常部署于多个省域的不同厂站,时序数据可能从多地同时产生,并需要汇总到省域侧或集团侧进行分析。因此,时序数据库需要适配多类主流协议,实现实时、易用、安全的数据同步方案,把设备端侧,厂站边侧,集团云侧的数据链路打通,方便企业更好地实现数据协同,也需要支持跨网闸传输、加密传输等工业场景所需要的特性传输方式,并保证在数据同步的过程中不影响本地的数据存储、计算。
(3)高可扩展
多终端、分散的工业设备上报时序数据的特性,也要求时序数据库能够以分布式的形态部署于多个厂站。面对多站点、更庞大的数据量,时序数据库需要保证集群容量的扩展性,能够管理上亿设备和测点,并具有高可用性,全面消除单点瓶颈,容忍部分节点失效,并能够随负载增加实现秒级扩容,及时分担负载压力。
(4)乱序写入、AI 分析
其实,对于上面提到的写入、分析等基础性能,也可以针对工业物联网场景进一步实现优化。比如,面对工业环境断网、延迟而产生的乱序数据,时序数据库需要能够有效应对,保障乱序数据写入的高实时性。再比如,面对工业故障监控、告警需求的进一步延伸,对于故障预测需求场景,时序数据库需要拥抱智能化分析,引入多类机器学习算法,以实现序列预测、异常预测等深度学习功能。
04 总结
针对不同工业领域和细分场景,时序数据库还可能有更多的关注重点,与更多技术融合的可能,上文总结的时序数据选型指标必将在未来进一步更新、扩展。
而国产自研的时序数据库 IoTDB,针对上面的选型指标都达到了稳定、高效的性能表现。IoTDB 的写入吞吐、存储占用、读取延迟等指标,在国际数据库第三方性能测试排行榜 benchANT 中,均位居第一,并在乱序数据写入、智能数据分析、数据协同传输、分布式扩展部署等工业物联网场景需求方向,都实现了相关功能的支持。
同时,IoTDB 商业化友好,具备便捷的二次开发能力,并已拥有一系列适配的易用性工具,包括集群管理工具 IoTDB-OpsKit、系统监控面板、可视化控制台 Workbench、组态软件等等,无疑能够更好地帮助数据库运维人员与业务人员发挥 IoTDB 的最大价值。
想要详细了解 IoTDB 的相关功能,欢迎点击阅读“时序数据库IoTDB:功能详解与行业应用”并联系我们!