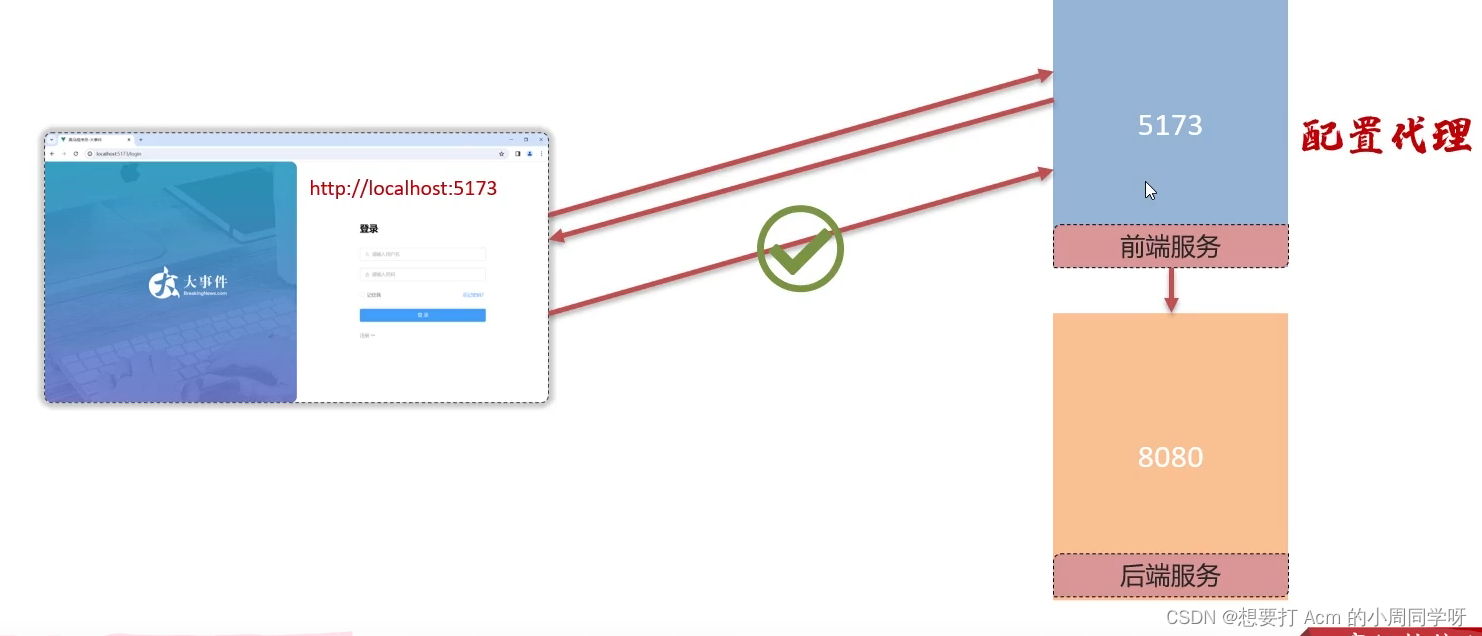
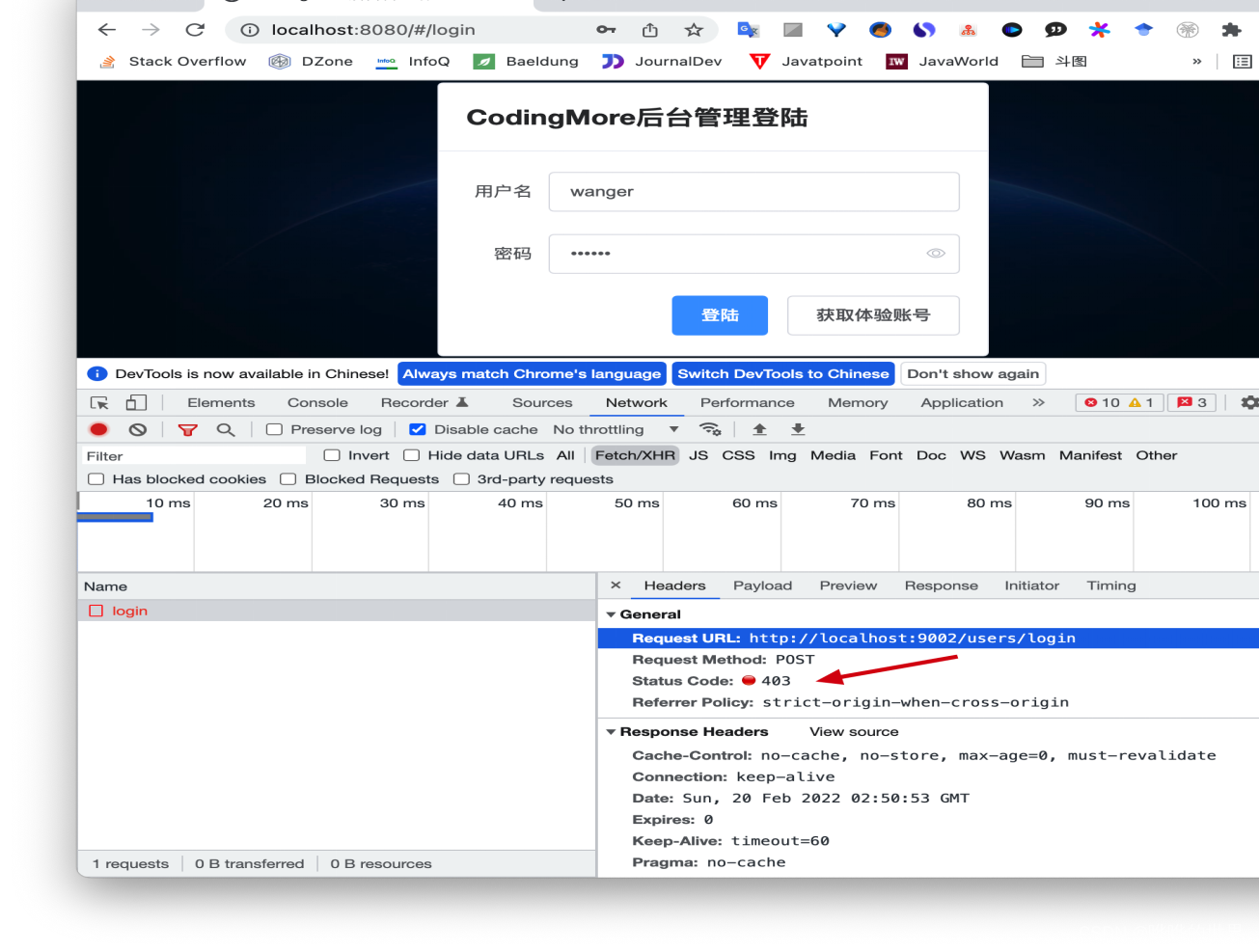
前端跨域问题,实际上是指浏览器出于安全考虑实施的“同源策略”(Same-origin policy)限制。以下是关于跨域的详细解释:
同源策略
同源策略是Web浏览器最核心也最基本的安全功能之一。它规定:从一个源加载的文档或脚本如何与另一个源的资源进行交互。它能帮助阻止恶意文档,减少可能窃取数据的安全威胁。
如果两个页面的协议、域名(或ip地址)、端口三者之一不同,则这两个页面就属于不同的源。
跨域
当尝试从与原始文档不同的域、协议或端口加载资源时,就会发生跨域请求。由于同源策略的限制,从一个域上加载的脚本尝试向另一个域发起HTTP请求时会受到限制。例如:
http://www.example.com与https://www.example.com属于跨域,因为协议不同。http://www.example.com与http://sub.example.com属于跨域,因为域名不同。http://www.example.com与http://www.example.com:8080属于跨域,因为端口不同。
为什么需要跨域
在现实开发中,往往后端服务与前端项目是分离部署的,或者一个前端应用需要调用多个不同域名的后端服务,这种情况下就需要跨域请求。
跨域解决方案
虽然同源策略限制了跨域请求,但开发中经常需要实现跨域操作,以下是一些常用的跨域解决方案:
- JSONP(只支持GET请求):通过
<script>标签的src属性发送跨域请求。 - CORS(Cross-Origin Resource Sharing):通过后端在HTTP头部添加
Access-Control-Allow-Origin等字段来允许跨域请求。 - 代理服务器:前端开发时使用代理服务器转发请求,绕过浏览器的同源策略。
- Websocket:WebSocket协议支持跨域通信。
- Node中间件:在Node.js中可以设置中间件来支持跨域请求。
跨域操作虽然能够满足开发需求,但同时也带来了安全风险,因此开发时需要谨慎处理跨域请求,确保不会因此导致安全漏洞。
意思跨域是前端自带的,而且是前端不能更改的?只能在后端想办法?
是的,跨域限制是浏览器内置的同源策略(Same-origin policy)的一部分,这是前端无法更改的安全特性。这个策略是为了保护用户免受恶意网站攻击而设计的。由于这个限制是由浏览器实现的,因此前端代码本身无法直接绕过跨域限制。
前端开发者通常有以下几种方式来处理跨域问题:
- 使用CORS(推荐):通过后端服务器设置相应的HTTP头部(如
Access-Control-Allow-Origin)来允许特定的外部域访问资源。 - JSONP:利用
<script>标签没有跨域限制的特性,通过动态创建<script>标签来发送跨域请求。但这种方法只支持GET请求,并且不如CORS安全。 - 代理服务器:在前端应用部署的服务器上设置代理,将请求转发到后端服务器,然后将响应返回给前端。这样前端请求看起来是同源的,因为请求都是通过同一个域名发出的。
- Websocket:使用Websocket协议可以绕过同源策略的限制,实现跨域通信。
- 后端转发:在需要跨域请求时,前端先请求自己的后端,然后由后端转发请求到其他域名的服务器,并将响应返回给前端。
所以,虽然前端不能直接更改跨域限制,但可以通过上述方法之一来间接处理跨域请求。通常情况下,最佳实践是使用CORS,因为它是最直接、最安全的解决方案。其他方法则可以作为备选方案,或者在某些特定场景下使用。
当我们谈论浏览器打开的域名时,通常指的是前端服务。以下是前端服务和后端服务的简单解释:
前端服务(Frontend Service)
- 定义:前端服务通常是指用户直接与之交互的Web应用程序部分。它包括HTML、CSS和JavaScript代码,以及可能包含的图片、视频等资源。
- 部署位置:前端代码通常部署在Web服务器上,例如Apache、Nginx等,这些服务器负责将静态文件发送到用户的浏览器。
- 功能:前端负责展示用户界面、响应用户操作(如点击、输入等),并通过发送HTTP请求与后端服务进行通信以获取或发送数据。
后端服务(Backend Service)
- 定义:后端服务是指应用程序的逻辑、数据库交互、业务规则处理等部分,通常运行在服务器上。
- 部署位置:后端代码可能部署在应用服务器上,如Node.js、Python的Django或Flask、Java的Spring等。
- 功能:后端负责处理前端发送的请求,执行相应的逻辑操作(如数据库查询、数据处理等),并将结果返回给前端。
浏览器打开的域名
当你通过浏览器访问一个域名时,通常是以下流程:
- 域名解析:浏览器解析域名以获取相应的IP地址。
- 请求发送:浏览器向该IP地址发送HTTP请求。
- 前端响应:Web服务器(通常是负责托管前端资源的服务器)接收到请求,并返回HTML、CSS、JavaScript等文件。
- 页面加载:浏览器加载这些文件并渲染页面,用户开始与前端交互。
在这个过程开始时,用户实际上是与前端服务交互。然而,前端服务可能依赖于后端服务来处理数据。例如,当用户填写表单并提交时,前端会发送一个请求到后端API,后端处理这个请求,然后将结果返回给前端,前端再根据这些结果更新页面。
示例
假设你访问 http://www.example.com:
- 前端服务:浏览器加载来自
http://www.example.com的HTML、CSS和JavaScript文件。 - 后端服务:当你在这个页面上执行某个操作(如登录),前端代码会发送一个请求到后端服务(可能是
http://api.example.com/login),后端处理登录逻辑并返回结果。
总结来说,浏览器打开的域名通常是指向前端服务,而前端服务可能会与后端服务进行交互以处理更复杂的数据处理和业务逻辑。
是的,浏览器可以被视为一个客户端对象。在客户端-服务器(Client-Server)架构中,浏览器是客户端的一部分,负责发送请求到服务器,并接收、解析、显示服务器返回的数据。
以下是前后端与浏览器的关系,以及它们是如何部署和交互的详细解释:
浏览器作为客户端
- 浏览器是一个用户代理,它代表用户发起网络请求。
- 浏览器通过HTTP协议与服务器进行通信,发送请求并接收响应。
- 浏览器负责渲染HTML、CSS和执行JavaScript,以向用户提供交互式的Web体验。
前端服务与后端服务
- 前端服务:通常指的是Web应用的前端部分,它包括静态资源(HTML、CSS、JavaScript)和可能的一些动态客户端逻辑。前端服务通常部署在Web服务器上,如Apache、Nginx等。
- 后端服务:指的是Web应用的后端部分,包括应用程序逻辑、数据库操作等。后端服务通常部署在应用服务器上,如Node.js、Java Tomcat、Python WSGI服务器等。
部署位置
- 前端服务和后端服务都部署在服务器上,但它们可能位于不同的服务器或不同的服务实例上。在某些情况下,它们也可能部署在同一台服务器上,但通常是分开的,以便于管理和扩展。
前后端与浏览器的交互
- 用户输入URL:用户在浏览器中输入URL或点击链接。
- 域名解析:浏览器解析域名以获取服务器的IP地址。
- 发送请求:浏览器向该IP地址发送HTTP请求。
- 前端响应:Web服务器(托管前端资源的服务器)接收到请求,并返回HTML、CSS、JavaScript等文件。
- 页面渲染:浏览器加载并渲染页面,用户开始与前端交互。
- 前端与后端交互:当用户执行某些操作(如提交表单、点击按钮)时,前端可能会发送AJAX请求(例如使用
fetch或XMLHttpRequest)到后端API。 - 后端处理:后端服务接收到请求,执行相应的逻辑(如数据库操作、业务逻辑处理),并将结果返回给前端。
- 前端更新:前端接收到后端的响应,并据此更新页面,展示给用户。
示例
假设用户在浏览器中访问 http://www.example.com:
- 浏览器请求
http://www.example.com,获取前端资源。 - 前端页面加载完毕,用户看到并可以与之交互。
- 用户点击一个按钮,前端发送一个请求到
http://api.example.com/data(后端API)。 - 后端API处理请求,返回数据。
- 前端接收到数据,更新页面内容。
总结来说,浏览器是客户端的一部分,用户通过它与前端服务交互,前端服务再与后端服务通信以完成更复杂的操作。前端和后端服务都部署在服务器上,但它们各自有不同的职责和部署方式。
好的,让我们用一个更加通俗易懂的方式来解释这些概念。
通俗理解
- 服务器:想象成一家餐厅,服务器就是餐厅本身,它负责提供食物(即数据或网页)给顾客。
- 后端:后端就像餐厅的厨房,顾客看不到厨房里发生了什么,但厨房负责准备食物(处理数据),然后交给服务员(前端)。
- 前端:前端就像餐厅的服务员,他们把厨房准备好的食物(数据)端给顾客(用户),并接受顾客的订单(用户操作)。
- 浏览器:浏览器就像是顾客,他们来到餐厅(访问网站),点菜(发送请求),然后吃(查看和使用网页)。
- URL(统一资源定位符):URL就像是餐厅的地址,顾客可以通过这个地址找到餐厅,而浏览器可以通过URL找到网站。
前端服务部署和URL
- 前端服务部署:当你完成前端开发后,你需要把你的前端代码放到一个服务器上,这样用户才能通过互联网访问它。这个过程叫做部署。
- URL接口:前端服务部署后,通常会有一个或多个URL,用户可以通过这些URL访问你的网站。比如
http://www.yourwebsite.com。
开启前端服务的代码
以下是一个简单的例子,展示如何在Node.js环境中使用Express框架来部署和开启一个前端服务:
// 安装Express:npm install express
const express = require('express');
const path = require('path');
const app = express();
// 告诉Express你的静态文件(HTML, CSS, JS等)位于哪个文件夹
app.use(express.static(path.join(__dirname, 'public')));
// 设置一个基本的路由,比如首页
app.get('/', (req, res) => {
res.sendFile(path.join(__dirname, 'public', 'index.html'));
});
// 启动服务器,监听3000端口
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});
在这个例子中:
express.static告诉Express服务器静态文件的位置。app.get定义了一个路由,当用户访问网站根目录时,服务器会发送index.html文件给用户。app.listen让服务器在3000端口上监听请求。
理解服务器、后端、前端、浏览器、URL
- 服务器:就是一台24小时开着的电脑,它通过互联网提供数据或服务。
- 后端:是服务器上运行的一些程序,它们处理数据、逻辑运算,通常不直接与用户交互。
- 前端:是用户可以直接看到和与之交互的部分,通常包括网页的设计和布局。
- 浏览器:用户用来访问网站的工具,就像打开电视的遥控器。
- URL:是网站的地址,告诉浏览器去哪里找到你想要访问的网站。
通过这些比喻,希望你能更容易地理解这些概念。
是的,前端服务和后端服务通常都会有一个IP地址和端口,以便它们可以在网络上被访问。以下是详细解释:
前端服务和后端服务的IP和端口
- 前端服务:当你部署一个前端应用时,它会被托管在一个服务器上,这个服务器有一个IP地址和一个端口号。通常情况下,Web服务器(如Apache、Nginx)会监听80端口(HTTP)或443端口(HTTPS)来提供前端服务。例如,一个前端服务可能会在
http://www.example.com:80上被访问。 - 后端服务:后端服务同样运行在服务器上,它们也会监听特定的端口来接收和处理请求。这些端口可以是标准的HTTP端口,也可以是其他自定义端口。例如,一个后端API可能会在
http://api.example.com:3000上被访问。
浏览器访问前端服务
- 浏览器通过前端服务的URL来访问前端应用。这个URL通常包含服务器的IP地址和端口号(如果端口号不是80或443,否则可以省略)。
例如:http://www.example.com(默认端口80)https://www.example.com(默认端口443)http://www.example.com:3000(自定义端口3000)
前端服务访问后端服务
- 前端服务通常通过发送HTTP请求来访问后端服务。这些请求可以是直接在浏览器中通过JavaScript发起的(例如使用
fetch或XMLHttpRequest),也可以是通过服务器端代码(如Node.js中间件)转发的。
例如,前端代码可能会这样发送请求到后端服务:
在这个例子中,前端服务通过IP地址fetch('http://api.example.com:3000/data') .then(response => response.json()) .then(data => console.log(data)) .catch(error => console.error(error));api.example.com和端口3000访问后端服务。
总结
- 前端服务和后端服务都有自己的IP地址和端口。
- 浏览器通过前端服务的URL(包含IP和端口)访问前端应用。
- 前端服务通过发送HTTP请求到后端服务的URL(包含IP和端口)来与后端服务进行交互。
在实际部署中,前端和后端服务可能位于同一台服务器上,也可能位于不同的服务器上,但它们都需要能够通过网络被访问。如果前端和后端服务部署在同一台服务器上,它们可能共享同一个IP地址,但通常会使用不同的端口。
跨域问题确实与后端服务有关,这是因为浏览器同源策略的限制不仅作用于前端资源,也作用于通过前端发起的任何网络请求。以下是跨域问题与后端服务关系的逻辑流程:
浏览器同源策略
浏览器实施同源策略,目的是为了保护用户免受恶意网站的侵害。同源策略规定,从一个源加载的文档或脚本如何与另一个源的资源进行交互。如果两个页面的协议、域名(或IP地址)、端口三者之一不同,则这两个页面就不属于同一个源。
前端与后端交互的过程
- 用户操作:用户在浏览器中与前端页面交互,比如点击一个按钮。
- 前端请求:前端页面根据用户的操作,通过JavaScript(例如使用
fetch或XMLHttpRequest)发起一个HTTP请求,尝试从后端服务获取数据。 - 浏览器检查:浏览器在发送请求之前,会检查请求的目标URL是否与前端页面的源相同。
- 跨域请求:如果请求的目标URL与前端页面的源不同,那么这个请求就是一个跨域请求。
跨域问题的出现
- 浏览器限制:当浏览器检测到一个跨域请求时,它会根据同源策略限制这个请求,不会直接发送请求到后端服务,或者即使发送了请求,也不会允许前端页面读取返回的数据。
- 后端响应:即使后端服务愿意响应这个请求,由于浏览器的限制,前端页面也无法获取响应数据。
后端服务的作用
- 设置CORS:后端服务可以通过设置HTTP响应头(如
Access-Control-Allow-Origin)来告诉浏览器,它允许哪些源的前端页面访问它的资源。 - 代理请求:在某些情况下,后端服务可以作为代理,转发前端页面的请求到其他域名的服务器,并将响应返回给前端页面,从而绕过浏览器的同源策略。
为什么跨域问题与后端服务有关
- 权限控制:跨域问题的解决需要后端服务的配合,因为只有后端服务能够告诉浏览器,哪些请求是被允许的。
- 数据共享:如果后端服务没有正确设置CORS,前端页面就无法获取后端服务的数据,这直接影响了前端页面的功能。
总结
跨域问题之所以与后端服务有关系,是因为浏览器在发送跨域请求时会限制前端页面的行为,而后端服务需要通过特定的设置来允许这些请求。没有后端服务的配合,前端页面无法完成跨域请求。因此,解决跨域问题通常涉及到前端和后端服务的协作。
后端服务告诉浏览器允许跨域请求的方式是通过在HTTP响应中添加特定的头部字段。以下是详细解释:
CORS(跨源资源共享)头部字段
后端服务通过在HTTP响应中包含以下头部字段来告诉浏览器允许跨域请求:
Access-Control-Allow-Origin:这个头部字段指定了允许哪些域的脚本访问资源。它可以设置为特定的域名(如http://www.frontend.com),也可以设置为*来允许任何域名的请求。
例如:Access-Control-Allow-Origin: http://www.frontend.comAccess-Control-Allow-Methods:这个头部字段用于指定允许哪些HTTP方法(如GET, POST, PUT, DELETE等)进行跨域请求。
例如:Access-Control-Allow-Methods: GET, POST, PUT, DELETEAccess-Control-Allow-Headers:这个头部字段用于指定除了简单头部(如Accept和Content-Type)之外,还允许哪些自定义头部字段。
例如:Access-Control-Allow-Headers: X-Requested-With, Content-Type, AuthorizationAccess-Control-Allow-Credentials:这个头部字段用于指定是否允许浏览器发送凭据(如cookies和HTTP认证信息)。
例如:Access-Control-Allow-Credentials: true
接口交互
后端服务设置这些头部字段通常是在处理HTTP请求的接口中完成的。以下是一个简单的Node.js/Express后端接口示例,展示如何设置CORS头部:
const express = require('express');
const app = express();
// CORS设置
app.use((req, res, next) => {
res.header('Access-Control-Allow-Origin', '*'); // 允许任何源
res.header('Access-Control-Allow-Methods', 'GET, POST, PUT, DELETE'); // 允许的HTTP方法
res.header('Access-Control-Allow-Headers', 'Content-Type, Authorization'); // 允许的头部字段
next();
});
// 一个简单的GET接口
app.get('/data', (req, res) => {
res.json({ message: '这是您请求的数据' });
});
// 启动服务器
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
在这个例子中,app.use 中间件用于设置CORS头部,使得任何源都可以访问这个接口。/data 接口是一个简单的GET请求处理器,它会返回一些数据。
总结
后端服务通过在HTTP响应中添加特定的CORS头部字段来告诉浏览器哪些跨域请求是被允许的。这些头部字段是在后端服务的接口中设置的,它们定义了跨域请求的规则和限制。通过这种方式,后端服务可以安全地控制哪些外部域可以访问其资源。
HTTP接口协议(即HTTP协议)是互联网上应用最广泛的协议之一,它定义了客户端和服务器之间交换数据的方式。HTTP协议使用一系列的字段(headers)和请求/响应体(body)来传输数据。以下是HTTP接口协议中常见的字段和它们的作用:
请求头(Request Headers)
- Host:指定请求资源的网络地址。
- User-Agent:客户端的浏览器或设备类型和版本信息。
- Accept:客户端可以处理的媒体类型和优先级。
- Accept-Language:客户端首选的语言。
- Accept-Encoding:客户端可以处理的压缩编码类型。
- Content-Type:请求体的MIME类型。
- Content-Length:请求体(如果有)的长度。
- Cookie:客户端发送的cookie信息。
- Referer:发起请求的原始URL。
- Authorization:用于HTTP认证的凭证信息。
- Origin:发起请求的源(域名)。
- X-Forwarded-For:代理服务器添加的头部,包含原始客户端的IP地址。
响应头(Response Headers)
- Status Code:表示请求成功与否的代码。例如,200表示成功,404表示未找到,500表示服务器内部错误。
- Content-Type:响应体的MIME类型。
- Content-Length:响应体(如果有)的长度。
- Set-Cookie:服务器发送的cookie信息。
- Location:重定向URL。
- Server:服务器软件的名称和版本。
- Date:服务器生成响应的时间。
- Expires:响应过期的日期和时间。
- Last-Modified:资源最后修改的时间。
- ETag:资源的唯一标识符。
- Vary:告诉客户端如何缓存响应。
请求体(Request Body)
- 发送POST、PUT、PATCH等请求方法时,请求体包含了要发送给服务器的数据。
- 请求体可以是表单数据、JSON对象、XML文档等。
响应体(Response Body)
- 响应体包含了服务器返回的数据,如HTML页面、JSON对象、XML文档等。
为什么这些字段很重要?
这些字段帮助客户端和服务器之间进行有效的通信。例如:
- Host:告诉服务器请求的是哪个域名下的资源。
- User-Agent:服务器可以根据这个字段来适配不同的客户端。
- Content-Type:服务器需要知道请求体的格式才能正确处理。
- Status Code:客户端可以根据这个代码来判断请求是否成功。
通过这些字段,客户端和服务器可以交换信息,服务器可以响应客户端的请求,客户端可以处理服务器返回的数据。
希望这个解释能够帮助您更好地理解HTTP接口协议中的字段及其作用。如果您还有其他问题,请随时提问。
前端代码本身是静态的,不需要启动任何服务。前端代码(HTML、CSS、JavaScript)是预先编写好的,通常放在Web服务器上,如Nginx或Apache。当用户访问前端页面时,Web服务器直接将这些静态文件发送给浏览器,浏览器负责解析和渲染这些文件。
这里的服务是指Web服务器,它负责处理HTTP请求并返回静态文件。前端代码并不直接启动服务,而是由Web服务器提供服务。
以下是一个简单的例子,说明前端代码是如何通过Web服务器(如Nginx)来提供服务的:
- 前端代码:
- 创建一个目录结构,例如
public,并将您的HTML、CSS和JavaScript文件放入该目录中。
- 创建一个目录结构,例如
- Web服务器配置:
- 使用Nginx或其他Web服务器,配置一个指向
public目录的虚拟主机。 - 例如,在Nginx中,您可能会有一个配置文件,类似于这样:
server { listen 80; server_name example.com; location / { root /path/to/your/public; # 替换为您的文件夹路径 index index.html; } }
- 使用Nginx或其他Web服务器,配置一个指向
- 浏览器访问:
- 用户在浏览器中输入
http://example.com。 - 浏览器向服务器发送一个HTTP GET请求。
- 服务器接收到请求后,从
public目录中找到index.html文件,并将其发送给浏览器。 - 浏览器解析HTML文件,解析CSS和JavaScript文件,并将它们合并,以渲染出完整的网页。
在这个例子中,前端代码是通过Web服务器来提供服务的,而不是直接由前端代码启动服务。Web服务器负责处理HTTP请求,并返回前端代码。前端代码是静态的,不需要在运行时启动服务。
- 用户在浏览器中输入