前言
既然是做爬虫,那么肯定就会有一些小心思,比如去获取一些自己喜欢的资料等。
去百度图片去抓取图片吧
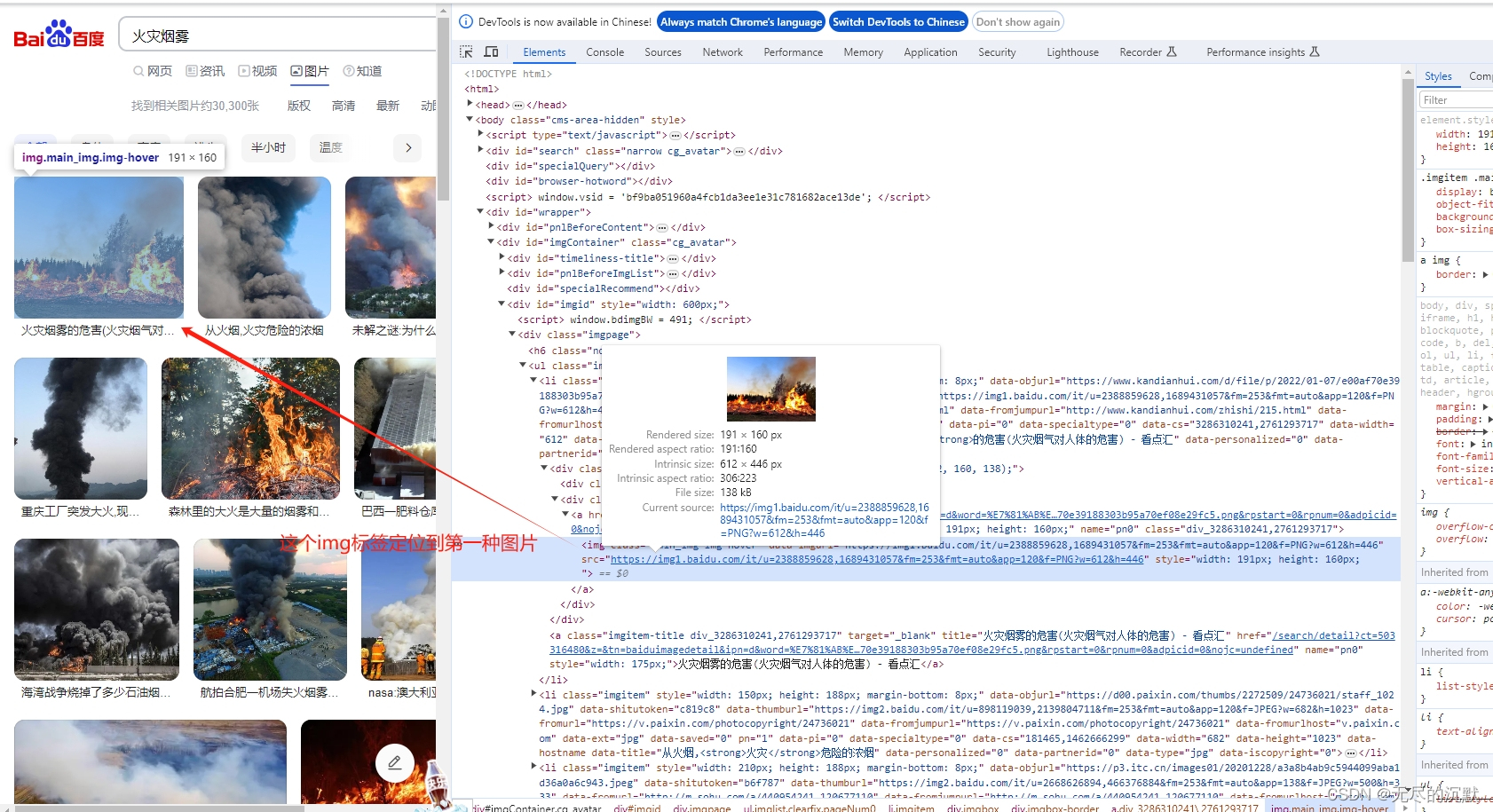
打开百度图片网站,点击搜索xxx,打开后,滚动滚动条,发现滚动条越来越小,说明图片加载是动态的,应该是通过ajax获取数据的,网站地址栏根本不是真正的图片地址。按F12打开开发者模式,我们边滚动边分析,发现下面的url才是真正获取图片地址的。
https://image.baidu.com/search/acjson?tn=resultjson_com&logid=xxxxxxx&ipn=rj&ct=201326592&is=&fp=result&fr=&word=你搜索的内容&queryWord=你搜索的内容&cl=&lm=&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&expermode=&nojc=&isAsync=&pn=120&rn=30&gsm=78&1721292699879=
盲目分析分析,其中pn=120,这有可能就是page number,这里的pn rn 很有可能就是page_size row_num,然后再去试着修改pn值为0,30,60去试试,发现果然数据不同,得。实锤了…
下面是pn=30的数据

(太严格了,只能发图片了,不知道能不能通过)
通过分析可知,data中就是真正的图片数据,好了我们可以拿到url,拿到各种数据了。
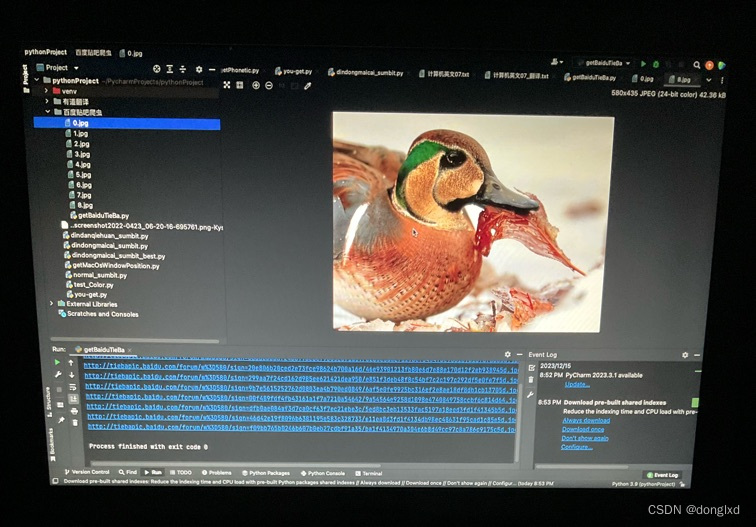
用python去爬取数据
这要分几个步骤:
- 我们是循环爬取数据的
- 爬取数据后还得保存到文件夹中
- 所以要引入os 以及 requests库
上代码
创建文件夹
# 需要用来创建文件夹
import os
# 在当前目录创建文件夹,咱就简单的弄吧,别搞复杂的
def mkdir_dir_at_curr_path(dir_name):
try:
os.mkdir(dir_name)
print('文件夹:',dir_name,'创建成功')
except FileExistsError:
print('文件夹:',dir_name,'已经存在')
def get_headers():
return {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"Access-Control-Allow-Credentials": "true",
"Access-Control-Allow-Origin": "https://m.baidu.com, https://www.baidu.com, http://m.baidu.com,http://www.baidu.com",
"Connection":"keep-alive",
"Content-Encoding": "br",
"Content-Type":"application/json"}
定义url以及headers
因为是循环爬取,所以url肯定是动态的,也就是改一下pn的值,查询的人物的名称,保证通用性。而且发现单纯的请求返回的数据不正常,这个时候我们就得加上headers了,这个没办法,百度肯定会有一些防御性的措施来防止爬虫捣乱。
# 需要发送请求
import requests
def get_headers():
return {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"Access-Control-Allow-Credentials": "true",
"Access-Control-Allow-Origin": "https://m.baidu.com, https://www.baidu.com, http://m.baidu.com,http://www.baidu.com",
"Connection":"keep-alive",
"Content-Encoding": "br",
"Content-Type":"application/json"}
def get_url(search_name,page_size):
url='https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8332766429333445053&ipn=rj&ct=201326592&is=&fp=result&fr=&word='+search_name+'&queryWord='+search_name+'&cl=2&lm=&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn='+str(page_size)+'&rn=30&gsm=3c&1721294093333='
return url
下载的主体逻辑
# 定义函数去下载图片
def down_load_pics(search_name):
# 创建文件夹
mkdir_dir_at_curr_path(search_name)
#是否继续循环去下载
flag=True
# 确定是第几次下载
request_count=0
while(flag):
print('第',request_count+1,'次下载中')
# 获取url
download_num=request_count*30
url= get_url(search_name,download_num)
# 获取请求头
headers=get_headers()
#发送请求获得响应数据
resp=requests.get(url,headers=headers)
# 确定是json数据了
jsonData=resp.json()
if 'data' not in jsonData or jsonData['data']==[] or jsonData['data']==[{}]:
print('已经全部下载完成')
# 下载完了就要跳出循环
flag=False
return
# 有数据就去下载
for item in jsonData['data']:
if 'thumbURL' in item and 'fromPageTitleEnc' in item and search_name in item['fromPageTitleEnc']:
# 图片的真正地址
sub_url=item['thumbURL']
if sub_url.startswith('http'):
response=requests.get(sub_url)
# 文件夹中文件数量,用来计算下载图片名称
file_size= len(os.listdir(search_name))
# 下载后图片名称下标
pic_index=file_size+1
#图片名称
curr_file_name=search_name+'_'+str(pic_index)
# 将下载好的图片数据保存到文件夹中
with open(str(search_name+'/'+curr_file_name)+'.jpg','wb') as f:
f.write(response.content)
print('第',pic_index,'张图片下载完成')
# 准备下一次循环
request_count = request_count + 1
最后可以去测试一下了
测试
if __name__ == '__main__':
down_load_pics('你搜索的内容')
真的是perfect!完全达到预期!
现在是不是感觉自己很帅啊哈哈
下面附上完整的代码,朋友们记得点个赞哦~~
# 需要发送请求
import requests
# 需要用来创建文件夹
import os
# 定义函数去下载图片
def down_load_pics(search_name):
# 创建文件夹
mkdir_dir_at_curr_path(search_name)
#是否继续循环去下载
flag=True
# 确定是第几次下载
request_count=0
while(flag):
print('第',request_count+1,'次下载中')
# 获取url
download_num=request_count*30
url= get_url(search_name,download_num)
# 获取请求头
headers=get_headers()
#发送请求获得响应数据
resp=requests.get(url,headers=headers)
# 确定是json数据了
jsonData=resp.json()
if 'data' not in jsonData or jsonData['data']==[] or jsonData['data']==[{}]:
print('已经全部下载完成')
# 下载完了就要跳出循环
flag=False
return
# 有数据就去下载
for item in jsonData['data']:
if 'thumbURL' in item and 'fromPageTitleEnc' in item and search_name in item['fromPageTitleEnc']:
# 图片的真正地址
sub_url=item['thumbURL']
if sub_url.startswith('http'):
response=requests.get(sub_url)
# 文件夹中文件数量,用来计算下载图片名称
file_size= len(os.listdir(search_name))
# 下载后图片名称下标
pic_index=file_size+1
#图片名称
curr_file_name=search_name+'_'+str(pic_index)
# 将下载好的图片数据保存到文件夹中
with open(str(search_name+'/'+curr_file_name)+'.jpg','wb') as f:
f.write(response.content)
print('第',pic_index,'张图片下载完成')
# 准备下一次循环
request_count = request_count + 1
def get_headers():
return {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36",
"Access-Control-Allow-Credentials": "true",
"Access-Control-Allow-Origin": "https://m.baidu.com, https://www.baidu.com, http://m.baidu.com,http://www.baidu.com",
"Connection":"keep-alive",
"Content-Encoding": "br",
"Content-Type":"application/json"}
def get_url(search_name,page_size):
url='https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8332766429333445053&ipn=rj&ct=201326592&is=&fp=result&fr=&word='+search_name+'&queryWord='+search_name+'&cl=2&lm=&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn='+str(page_size)+'&rn=30&gsm=3c&1721294093333='
return url
# 在当前目录创建文件夹,咱就简单的弄吧,别搞复杂的
def mkdir_dir_at_curr_path(dir_name):
try:
os.mkdir(dir_name)
print('文件夹:',dir_name,'创建成功')
except FileExistsError:
print('文件夹:',dir_name,'已经存在')
if __name__ == '__main__':
down_load_pics('xxx任何你喜欢的内容')