Redis
简介
Redis全称为 Remote Dictionary Server,表示远程字典服务器,是跨平台的非关系型数据库。Redis 是一个开源的使用键值对(Key-Value)存储数据库,也是一种NoSQL数据库。(总结:Redis是一个基于内存的高性能非关系型Key-Value数据库。)
NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
功能
- 可以用于存储用户的登陆信息和认证信息(单点登录 SSO,在分布式系统中的任一一台服务器登录,访问其他的服务器均不需要再进行登录)
- Redis中最大的功能可能就是做系统数据的缓存(这是这个时代的一个技术特点)
- 可以用来做秒杀系统
- 用来存储一些可以容忍丢失的数据
因为Redis本身是基于内存的,怎么都有可能存在数据丢失的风险,所以Redis的适用场景,一定是对数据要求 不严格的地方,比如:评论数、点赞数、最热商品 - 接口的防刷和限流
RESP协议
Redis 的客户端和服务端之间采取了一种名为 Redis序列化的协议(REdis Serialization Protocol,简称RESP),是基于 TCP 的应用层协议 ,RESP 底层采用的是 TCP 的连接方式,通过 TCP 进行数据传输,然后根据解析规则解析相应信息。
在RESP协议中,数据的类型取决于第一个字节:
- +开始表示单行字符串
- -开始表示错误类型
- :开始表示整数
- $开始表示多行字符串
- *开始表示数组
在RESP协议中,构成协议的每一部分必须使用\r\n作为结束符
示例:
SET key value
*3\r\n #3表示这个命令由3部分组成
$3\r\n # 第一部分的长度是3
SET\r\n # 第一部分的内容
$3\r\n # 第二部分的长度是3
key\r\n # 第二部分的内容
$5\r\n # 第三部分的长度是5
value\r\n # 第三部分的内容
Redis命令
1.通用命令
del key #删除键
exists key #检测键是否存在,1-表示存在,0-表示不存在
expire key seconds #为键设置过期时间 单位是秒
pexpire key milliSeconds #为键设置过期时间 单位是毫秒
keys pattern #使用正则表达式查找键,尽量不要使用这个名来来查找,这个名来查找时可能会造成服务器卡顿
persist key #持久化键,过期时间就相当于没有了
ttl key #获取键的剩余过期时间 单位是秒
pttl key #获取键的剩余过期时间 单位是毫秒
type key #获取键的存储的值的类型
select 0~15 #选择操作的库
move key db #移动键到另外一个库中
flushdb #清空当前所在的数据库
flushall #清空全部数据库
dbsize #查看当前数据库中有多少个键
lastsave #查看最后一次操作的时间
monitor #实时监控Redis服务接收到的命令
2.String命令
set key value #设置键的值,如果存在就是修改,不存在就是增加
get key #获取键的值
mset key value[key value ...] #批量设置键的值
mget key [key ...] #批量获取键的值
setex key seconds value #设置键的值,同时设置键的过期时间
setnx key value #当键不存在时才设置键的值
incr key #将键存储的值增加1,只有存储数字的时候有效
incrby key increment #将键存储的值增加给定的增量,只有存储数字的时候有效
decr key #将键存储的值减去1,只有存储数字的时候有效
decrby key decrement #将键存储的值减少给定减量,只有存储数字的时候有效
append key value #当键存在且存储的值是一个字符串时,将值追加到存储的字符串的末尾
3.Hash命令
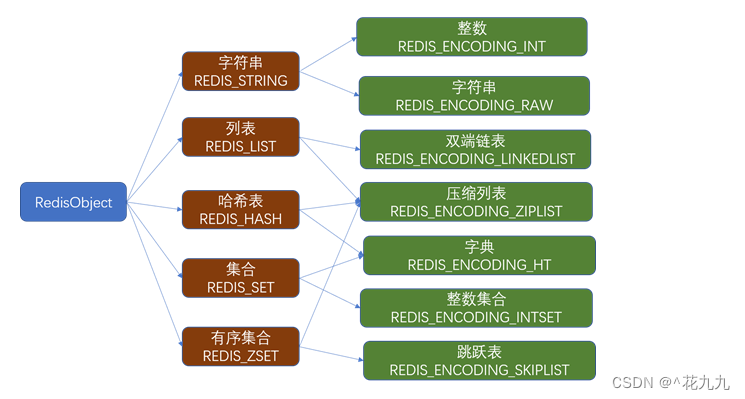
string: key --> value
hash: key --> {field:value , field2:value2}
hset key field value #设置键存储的字段和值
hget key field #获取键存储的字段值
hmset key field value[field value ...] #批量设置键的存储的字段和值
hmget key [field ...] #批量获取键存储的字段值
hincrby key field increment #键存储的字段值自增1
hsetnx key field value #不存在字段就添加
hexists key field #检查键存储的字段是否存在
hdel key field [field ...] #批量删除键中存储的字段
hgetall key #获取当前键存储的字段和值
hkeys key #获取当前键存储的所有字段
hvals key #获取当前键存储的所有值
hlen key #获取当前键存储的字段数量
4.List命令
list: key -->[elment1, elment2, …] 是有序的
#存储数据(从左侧插入数据,从右侧插入数据)
lpush key value [value ...]
rpush key value [value ...]
lpushx key value #将一个值插入到已存在的列表头部
rpushx key value #为已存在的列表添加值
lset key index value #通过索引设置列表元素的值
#弹栈方式获取数据(左侧弹出数据,从右侧弹出数据)
lpop key
rpop key
lrange key start stop #获取列表指定范围内的元素 -1表示末尾
lindex key index #获取指定索引位置的数据
llen key #获取列表的长度
#删除列表中的数据(他是删除当前列表中的count个value值,count > 0从左侧向右侧删除,count < 0从右侧向左侧删除,count == 0删除列表中全部的value)
lrem key count value
#对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
ltrim key start stop
#将一个列表中最后的一个数据,插入到另外一个列表的头部位置
rpoplpush list1 list2
5.Set命令
set: key --> [elment1, element2] 无序且去重
#存储数据
sadd key member [member ...]
#获取数据(获取全部数据)
smembers key
#随机获取一个数据(获取的同时,移除数据,count默认为1,代表弹出数据的数量)
spop key [count]
#交集(取多个set集合交集)
sinter set1 set2 ...
#并集(获取全部集合中的数据)
sunion set1 set2 ...
#差集(获取多个集合中不一样的数据)
sdiff set1 set2 ...
#删除数据
srem key member [member ...]
#查看当前的set集合中是否包含这个值
sismember key member
6.Zset(Sorted Set) 命令
数据结构:跳跃表
#添加数据(score必须是数值。member不允许重复的。)
zadd key score member [score member ...]
#修改member的分数(如果member是存在于key中的,正常增加分数,如果memeber不存在,这个命令就相当于zadd)
zincrby key increment member
#查看指定的member的分数
zscore key member
#获取zset中数据的数量
zcard key
#根据score的范围查询member数量
zcount key min max
#删除zset中的成员
zrem key member [member...]
#根据分数从小到大排序,获取指定范围内的数据(withscores如果添加这个参数,那么会返回member对应的分数)
zrange key start stop [withscores]
#根据分数从大到小排序,获取指定范围内的数据(withscores如果添加这个参数,那么会返回member对应的分数)
zrevrange key start stop [withscores]
#根据分数的返回去获取member(withscores代表同时返回score,添加limit,就和MySQL中一样,如果不希望等于min或者max的值被查询出来可以采用 ‘(分数’ 相当于 < 但是不等于的方式,最大值和最小值使用+inf和-inf来标识)
zrangebyscore key min max [withscores] [limit offset count]
#根据分数的返回去获取member(withscores代表同时返回score,添加limit,就和MySQL中一样)
zrevrangebyscore key max min [withscores] [limit offset count]
Java操作Redis
依赖
<dependencies>
<!-- jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
</dependencies>
操作
redis中的操作命令
public class GenericCommandTest {
public static void main(String[] args) throws InterruptedException {
Jedis jedis = new Jedis("localhost", 6379);
if (jedis.exists("name")) {
jedis.del("name");
}
jedis.expire("time", 20);
while (true){
Long rest = jedis.ttl("time");
if(rest == -2) break;
System.out.println(rest);
Thread.sleep(1000);
}
}
}
SCAN操作
SCAN操作可以根据提供的匹配方式和扫描数量来进行扫描,但是每次扫描的结果不一定与扫描数量匹配,只是返回一个在扫描数量范围左右的结果。可能比扫描数量多也可能少。
@Test
public void scan(){
Jedis jedis = new Jedis("localhost", 6379);
jedis.select(0);
jedis.flushDB();
jedis.mset("name","张三","age","20","address","四川成都","phone","18912345678","class","BigDataManage");
//scan 就是扫描 扫描需要配置扫描的条件 这个条件就是ScanParams
ScanParams params = new ScanParams().match("*a*").count(3);
//这个静态变量标识的就是光标开始的位置,默认是0
String cursor = ScanParams.SCAN_POINTER_START;
do {
//扫描后会得到扫描的结果ScanResult
ScanResult<String> scanResult = jedis.scan(cursor,params);
List<String> result = scanResult.getResult();
result.forEach(System.out::println);
System.out.println("=====================================");
cursor = scanResult.getStringCursor();
//当光标位置再次归0 表示扫描完成
} while (!ScanParams.SCAN_POINTER_START.equals(cursor));
jedis.close();
}
@Test
public void hscan(){
Jedis jedis = new Jedis("localhost", 6379);
jedis.select(1);
jedis.flushDB();
Map<String,String> map = new HashMap<>();
map.put("name","波多");
map.put("age","23");
map.put("address","四川成都");
map.put("phone","13812345678");
map.put("class","BigDataManage");
jedis.hmset("user",map);
ScanParams params = new ScanParams().match("*a*").count(3);
String cursor = ScanParams.SCAN_POINTER_START;
do {
ScanResult<Map.Entry<String, String>> scanResult = jedis.hscan("user", cursor, params);
List<Map.Entry<String, String>> result = scanResult.getResult();
result.forEach(System.out::println);
System.out.println("======================================");
cursor = scanResult.getStringCursor();
}while (!ScanParams.SCAN_POINTER_START.equals(cursor));
jedis.close();
}
@Test
public void sscan(){
Jedis jedis = new Jedis("localhost", 6379);
jedis.select(2);
jedis.flushDB();
jedis.sadd("info","bac","abc","cab","bca","cba");
ScanParams params = new ScanParams().match("a*").count(3);
String cursor = ScanParams.SCAN_POINTER_START;
do {
ScanResult<String> infos = jedis.sscan("info", cursor, params);
List<String> result = infos.getResult();
result.forEach(System.out::println);
System.out.println("===================================");
cursor = infos.getStringCursor();
}while (!ScanParams.SCAN_POINTER_START.equals(cursor));
jedis.close();
}
@Test
public void zscan(){
Jedis jedis = new Jedis("localhost", 6379);
jedis.select(3);
jedis.flushDB();
Random r = new Random();
List<String> members = Arrays.asList("bac","abc","cab","bca","cba");
Map<String,Double> memberAndScores = new HashMap<>();
members.forEach(str->memberAndScores.put(str, (double) r.nextInt(100)));
jedis.zadd("infos",memberAndScores, ZAddParams.zAddParams().nx());
ScanParams params = new ScanParams().match("*a*").count(3);
String cursor = ScanParams.SCAN_POINTER_START;
do {
ScanResult<Tuple> infos = jedis.zscan("infos",cursor,params);
List<Tuple> result = infos.getResult();
result.forEach(t -> System.out.println(t.getElement() + "=>" + t.getScore()));
System.out.println("=========================================");
cursor = infos.getStringCursor();
} while (!ScanParams.SCAN_POINTER_START.equals(cursor));
jedis.close();
}
Redis数据类型应用场景
String:点赞数,粉丝数,查询缓存,评论数等
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.incr("comments");//将评论数增加1
Hash: 购物车,抢购,限购,限量发送优惠券等
private void shoppingCar(){
//购物车
//用户名 => 多个商品
//用户名 => {商品1的编号:数量,商品2的编号:数量}
String username = "zhangSan";
String goodsId = "G000001";
Jedis jedis = new Jedis("localhost", 6379);
//不需要判断,因为hincrBy如果没有会创建
jedis.hincrBy(username,goodsId,1);
}
private void sopping(){
Jedis jedis = new Jedis("localhost", 6379);
//抢购
//一个商家一般都会发布几款做活动的商品进行抢购
//商家 => 多个商品
String seller = "lisi";
jedis.hset(seller,"G000001","50");
jedis.hset(seller,"G000002","50");
jedis.hset(seller,"G000003","50");
jedis.hset(seller,"G000004","50");
//模拟抢购
Long result = jedis.hincrBy(seller, "G000001", -1);
if(result!=null && result >=0){
System.out.println("抢购成功");
}
}
List: 消息队列,最新评论等
private static void comment (){
//评论
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.lpush("comments", "第一条评论");
jedis.lpush("comments", "第二条评论");
jedis.lpush("comments", "第三条评论");
jedis.lpush("comments", "第四条评论");
jedis.lpush("comments", "第五条评论");
jedis.lpush("comments", "第六条评论");
//展示评论列表,评论展示都是最后的评论在最前,取前5条展示
List<String> comments = jedis.lrange("comments", 0, 4);
comments.forEach(System.out::println);
}
private static void messageQueue(){
//消息队列 可以简单的理解为存放消息的队列,既然是队列,就具有先进先出的特性
//使用redis来模拟这个特性就是消息队列
Jedis jedis = new Jedis("127.0.0.1", 6379);
//用户发出的第一条消息
jedis.lpush("message_queue", "第一条消息");
//用户发出的第二条消息
jedis.lpush("message_queue", "第二条消息");
//用户发出的第三条消息
jedis.lpush("message_queue", "第三条消息");
//服务器端只需要依次取就可以了
while (true){
//如果message_queue不存在,那么就阻塞等待1秒,如果还不存在,就抛出异常
List<String> messages = jedis.brpop(1000,"message_queue");
messages.forEach(System.out::println);
}
}
Set:交集,并集,差集,黑白名单等
private static void black(){
Jedis jedis = new Jedis("localhost", 6379);
Random r = new Random();
for (int i = 0; i < 100; i++) {
int first = r.nextInt(255) + 1;
int second = r.nextInt(255) + 1;
int third = r.nextInt(255) + 1;
int fourth = r.nextInt(255) + 1;
String ip = first + "." + second + "." + third + "." + fourth;
int times = r.nextInt(100);//访问次数
System.out.println(ip + "=>" + times);
//利用hash结构将每一个ip的访问次数存储起来
jedis.hset("accessTimes",ip,Integer.toString(times));
if(times > 60){//访问次数超过60次的,认为这些操作属于恶意操作
jedis.sadd("invalidIpAddress",ip);//将IP记录下来,下次再访问的时候直接拒绝
}
}
System.out.println("==============================");
Set<String> ips = jedis.hkeys("accessTimes");
for (String ip : ips) {
if(jedis.sismember("invalidIpAddress",ip)){
System.out.println(ip+"不能再进行访问");
}
}
}
Zset :延迟队列,排行榜,限流等
private static void currentLimiting(){
//假设每个用户5秒内访问了10次,则将被限流,后续请求将不再被处理
Jedis jedis = new Jedis("127.0.0.1", 6379);
Random r = new Random();
String[] names = {"AA", "BB","CC","DD","EE", "FF","GG"};
long currentTime = System.currentTimeMillis();
for(String name: names){
//使用随机数模拟访问次数
int times = r.nextInt(15);
System.out.println(name + " => 访问 " + times + "次");
for(int i=0; i<times; i++){
//这里考虑sorted set的原因是 key只存在一个,但可以有多个得分,这里使用的是时间来作为得分,那么统计的时候就
//只需要统计5秒内的成员数量,这样就能得到5秒内的访问次数。虽然使用hash也能得到这样的访问次数,但是hash在移出
//过期的记录时没有规则,sorted set可以根据得分范围来进行移出,也就是可以通过时间范围来进行移出,这样可以避免
//记录无限增长的情况
jedis.zadd(name, currentTime- r.nextInt(5000), name + System.nanoTime());
}
jedis.zremrangeByScore(name, 0, currentTime - 5000);//移出前5秒的访问记录
}
System.out.println("=========================================");
String name = "AA";
long time = System.currentTimeMillis();
Set<String> results = jedis.zrevrangeByScore(name, time, time - 5000);//统计5秒内访问次数
if(results.size() >= 10){
System.out.println(name + " => 被限流了");
} else {
System.out.println(name + " => 当前访问次数为" + results.size() + ",可以继续访问");
}
}
private static void delayQueue() throws InterruptedException {
//延迟队列,指的是队列中的信息将在未来进行处理
Jedis jedis = new Jedis("localhost", 6379);
long time = System.currentTimeMillis();
jedis.zadd("orders",time+5000 , "ORDER00001");
jedis.zadd("orders",time+6000 , "ORDER00002");
jedis.zadd("orders",time+7000 , "ORDER00003");
jedis.zadd("orders",time+8000 , "ORDER00004");
while (true){
long currentTime = System.currentTimeMillis();
//将当前时间作为最大的得分
Set<Tuple> tuples = jedis.zrangeByScoreWithScores("orders", 0, currentTime);
for (Tuple tuple : tuples) {
String order = tuple.getElement();
double score = tuple.getScore();
System.out.println(order + "=" + score);
System.out.println("正在处理" + order + ",处理时间:" + currentTime);
//消息处理完后,需要将消息从队列中移除
jedis.zrem("orders",order);
}
Thread.sleep(1000L);
}
}
private static void attack(){
Jedis jedis = new Jedis("127.0.0.1", 6379);
Random r = new Random();
String[] names = {"AA", "BB","CC","DD","EE", "FF","GG"};
for(String name: names){
int score = r.nextInt(100000) + 10000;
System.out.println(name + " => " + score);
jedis.zadd("attack", score, name);
}
System.out.println("攻击排行榜");
Set<Tuple> attacks = jedis.zrevrangeWithScores("attack", 0, 4);
attacks.forEach(t -> System.out.println(t.getElement() + " => " + t.getScore()));
}
Jedis连接池
其目的似乎为了避免频繁地创建和关闭连接带来的性能开销。
public static void main(String[] args) {
GenericObjectPoolConfig config = new GenericObjectPoolConfig();
config.setMaxIdle(8);//设置最大空闲连接数
config.setMinIdle(0);//设置最小空闲连接数
config.setMaxTotal(8);//设置最大连接数
config.setMaxWaitMillis(2000);//设置最大等待的毫秒数(考虑连接池中的连接已经被用完)
JedisPool pool = new JedisPool(config,"localhost",6379);
Jedis jedis = pool.getResource();//从连接池中获取一个资源,这个资源就是一个连接
jedis.set("jedisPool","success");
System.out.println(jedis.get("jedisPool"));
jedis.close();
pool.close();
}
Jedis管道操作
对于每一个Redis命令,都需要经过网络然后到达Redis,再经过网络回到客户端,如果每条命令都这样执行,效率会很低下,因此可以将多条命令一起打包发送,节约时间。这样的操作就是管道操作。具体来说,就是通过Redis的管道,先将命令放到客户端的一个Pipeline中,之后一次性的将全部命令都发送到Redis服务,Redis服务一次性的将全部的返回结果响应给客户端。
public static void main(String[] args) {
GenericObjectPoolConfig config = new GenericObjectPoolConfig();
config.setMaxIdle(8);//设置最大空闲连接数
config.setMinIdle(0);//设置最小空闲连接数
config.setMaxTotal(8);//设置最大连接数
config.setMaxWaitMillis(2000);//设置最大等待的毫秒数(考虑连接池中的连接已经被用完)
JedisPool pool = new JedisPool(config,"localhost",6379,5);
Jedis jedis = pool.getResource();//从连接池中获取一个资源,这个资源就是一个连接
Pipeline pipeline = jedis.pipelined();//从当前连接中获取管道信息
//管道的操作方式与jedis一样,只是最终执行的时候会将指令一起发送
pipeline.set("boy","spiderMan");//这里并没有执行命令,而是将命令放入管道中
pipeline.get("boy");
pipeline.lpush("heroes","superMan");
pipeline.lpush("heroes","spiderMan");
pipeline.lrange("heroes",0,-1);
//管道一次性将所有的命令全部发送到服务器,并接收服务器返回的所有结果
List<Object> results = pipeline.syncAndReturnAll();
for (Object result : results) {
System.out.println(result);
}
jedis.close();
pool.close();
}
Redis事务
Redis中也有事务,具备ACID特性,Redis中的事务需要使用watch监听机制,具体来说就是专门设立一个键,作为watch监听的对象,而事务则基于这一个键进行标识,如果在事务中这个键的值发生了改变,则这个事务也会取消,当事务完成或者取消后,watch监听自动消除。
- 开启事务命令:multi
- 输入要执行的命令:被放入到一个队列中
- 执行事务命令:exec
- 取消事务命令:discard
public static void main(String[] args) throws InterruptedException {
Jedis jedis = new Jedis("localhost", 6379);
jedis.select(1);
jedis.flushDB();
jedis.set("transaction","1");
jedis.hset("user","username","zhangsan");
jedis.hset("user","age","20");
jedis.hset("user","sex","man");
//======================基本信息=====================
jedis.watch("transaction");//监听一个键,基于这个键实现一个事务
Transaction transaction = jedis.multi();//开启事务
transaction.hset("user","age","21");
transaction.hset("user","sex","woman");
Thread.sleep(5000L);
List<Object> results = transaction.exec();
System.out.println(results);
jedis.close();
}
注:这里在事务提交前设置了5s的时间,如果在这5s内在redis客户端中改变了transaction这个键的值,则事务会取消,当查询时数据就会是20,和man,而不是事务中修改的数据。
Redis密码设置
在进行密码设置之前,可以先将redis默认的开机自启关闭,关闭步骤如下:
打开服务管理器:
- 按下
Win + R,打开运行对话框。 - 输入
services.msc,然后按下回车键。
找到 Redis 服务:
- 在服务列表中找到
Redis服务(名称可能是Redis或者redis-server,具体取决于安装时的配置)。
修改启动类型:
- 右键点击
Redis服务,选择属性。 - 在
常规选项卡中,找到启动类型。 - 将
启动类型设置为手动或者禁用。
应用更改:
- 点击
应用按钮,然后点击确定。
之前开启Redis的方式是直接点击redis-cli.exe文件,现在建议使用命令行开启, 也就是说要先用redis-server.exe redis.windows.conf命令(显示地加载指定的redis.windows.conf文件)启动,再新开一个命令行客户端,使用redis-cli开启输入 。
在安装目录下找到 redis.windows.conf 文件,这个文件就是 Redis 的配置文件。可以在该配置文件中配置 Redis 密码。
requirepass 密码
注意:这里需要将前面缩进的空格全部删除!
在 windows 下,密码生效首先需要关闭 Redis 服务, 然后在命令行中进入 Redis 安装目录,然后执行命令
redis-service.exe redis.windows.conf
redis-cli 连接 Redis: 首先需要执行命令
auth 密码
Jedis 连接 Redis:
Jedis jedis = new Jedis("121.199.174.183", 6379);
jedis.auth(密码);
JedisPool 连接 Redis:
JedisPool pool = new JedisPool(config, "121.199.174.183", 6379, 2000, 密码);
Redis持久化机制
从Redis3.0开始,提供了三种持久化机制,即RDB、AOF(Append Only File)和混合持久化。其中RDB是默认开启的,而AOF默认是关闭的。
RDB
RDB:RDB机制是指Redis在一定条件下对当前内存中存储的所有数据进行快照并存储到磁盘上,存储的格式为二进制文件,当需要进行数据恢复的时候就直接读取这个二进制文件,速度较快。
RDB触发的条件可以有用户在配置文件中自定义,由两个参数组成,分别为时间(秒)和改动的键的个数。逻辑为当在指定时间内被更改的键的个数大于了指定的数值时就会进行快照。 RDB是redis默认采用的持久化方式,在配置文件中提供了三种预置的条件:
save 900 1
save 300 10
save 60 10000
分别表示: 在900秒内,有1个键发生了改变就进行RDB持久化;
在300秒内,有10个键发生了改变就进行RDB持久化;
在60秒内,有10000个键发送改变才进行RDB持久化。
RDB的数据同步机制:
RDB模式下,首先清楚原来的rdb文件中的所有内容,清空之后再将内存中的数据同步进rdb文件中,相当于更新操作。
RDB的优点:
1.数据存储和恢复的速度快,因为是以二进制文件进行的存储和读取,所以速度快。
2.不会无限增加数据,因为RDB是以更新的形式进行的存储,每满足条件就会将原来的文件内容清空,所以不会一直叠加内容长度。
RDB的缺点:
从上面RDB的数据同步机制可以看出,如果RDB删除了数据还没完成数据的写入或者还没开始更新,但是Redis宕机或者断电了,那么就会失去这一段时间内的内存中的数据,所以无法保证数据的绝对安全。
AOF
AOF持久化类似于sql中的做法,不是存储数据本身,而是存储操作数据,因此AOF持久化文件是一个文本文件,速度相对于RDB较慢,且随着操作的增加内容会不断增加,传输较为困难。开启AOF后每执行一条更改Redis中数据的命令,Redis就会将该命令写入硬盘中的AOF文件。这样就保证了即使RDB丢失了数据,也可以利用AOF进行数据的恢复。
同样,在Redis中有AOF的配置项:
appendonly yes # 开启AOF持久化
appendfilename "appendonly.aof" # AOF持久化文件
#appendfsync always
appendfsync everysec
#appendfsync no
对于如何写入操作数据,Redis也提供了三种预设置:
appendfsync always 表示每执行一个写操作,立即持久化到AOF文件中,性能比较低。
appendfsync everysec 表示每秒执行一次持久化,在开发时,综合考虑使用这种方案。
appendfsync no 表示不同步,数据只保存在内存中,操作系统需要时刷新数据即可。
AOF重写
在AOF保存文件的时候,相同的操作AOF文件会记录多次,导致占用空间却没有意义,所以可以进行优化,需要手动使用bgrewriteaof命令。但是手动重写显然不满足生产环境的需要,所以Redis提供了以下配置:
auto-aof-rewrite-percentage 100 # 触发的条件:下面设置的文件大小增加100%,也就是1倍,才会重写
auto-aof-rewrite-min-size 64mb # aof文件大小达到64M才可能重写记录的命令
当aof进行重写后,会将原来相同的写操作合并为一次写操作,此时aof文件仍然是纯文本文件。
混合持久化
混合持久化默认是关闭的
aof-use-rdb-preamble no # 关闭混合持久化
# aof-use-rdb-preamble yes 开启混合持久化,需要开启aof才有效
混合持久化就是当触发AOF重写的时候,Redis会根据重写内容中的写操作生成一个RDB格式的快照,并将这部分追加到AOF文件中。所以AOF文件中既包含了完整的数据快照,也包含最新的增量日志,即变成了一个既有二进制数据,又有文本数据的文件。
注意: 启用混合持久化不会阻止 Redis 生成独立的 RDB 文件 。
Redis数据淘汰策略
Redis服务器的内存是有限的,硬件一旦确定了,内存大小也就确定了。当不停的向内存中写数据时,就会出现内存写满的情况,此时,就需要使用到Redis的数据淘汰策略了。Redis中设计了多种数据的淘汰策略,详情如下:
方案中针对淘汰对象又有两种方案:
volatile主要针对的是设置了过期时间的key,如果需要淘汰redis中的数据,那么这些设置了过期时间的key优先被淘汰,如果空间依然不足,那么才会在没有设置过期时间的key进行淘汰。
allkeys主要针对的是所有的键,不管有没有设置过期时间。
淘汰的方案有:
LRU: Least Recently Used ,即优先淘汰最久未使用的键。
LFU: Least Frequently Used ,即淘汰访问频率最小的键,访问频率指的是在一定时间范围内的访问次数。
random:随机进行淘汰。
ttl: Time To Live ,淘汰掉过期时间最短的键(只针对volatile方案)
noeviction:不淘汰任何数据。
# 优先淘汰掉设置了过期时间的key,然后才淘汰掉使用的比较少的key,假设key没有设置过期时间,那么不会优先淘
# 汰,这种模式也是在开发中使用的比较多的一种缓存策略模式
#volatile-lru -> Evict using approximated LRU among the keys with an expire set.
# 对所有key通用,优先删除最近最少使用的Key
# allkeys-lru -> Evict any key using approximated LRU.
# Redis中存储的每一个key都有一个内部时钟,当key使用频率高时,内部时钟会递增,当key使用频率低时,内部时钟会
# 递减,该策略是淘汰设置了过期时间且内部时钟最小的key
# volatile-lfu -> Evict using approximated LFU among the keys with an expire set.
# Redis中存储的每一个key都有一个内部时钟,当key使用频率高时,内部时钟会递增,当key使用频率低时,内部时钟会
# 递减,该策略是淘汰所有key中内部时钟最小的key
# allkeys-lfu -> Evict any key using approximated LFU.
# 随机淘汰具有过期时间的key
# volatile-random -> Remove a random key among the ones with an expire set.
# 淘汰的是随机的key
# allkeys-random -> Remove a random key, any key.
# 根据key剩余的过期时间(ttl值)来进行数据淘汰, ttl值越小,越先被淘汰
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
# 只要缓存满了,就不继续服务器里面的写请求,读请求是可以完成的,这种模式缓存里面的所有数据都不会丢失,但会导致
# 参与Redis的业务会失败
# noeviction -> Don't evict anything, just return an error on write operations.
maxmemory-policy volatile-lru #这个就是配置缓存的淘汰策略的
maxmemory <bytes> #这个是配置Redis的缓存的大小





























![[MySQL][索引][下][理解索引]详细讲解](https://i-blog.csdnimg.cn/direct/6d9e53dda3844ddebaaf2185e88a0969.png)