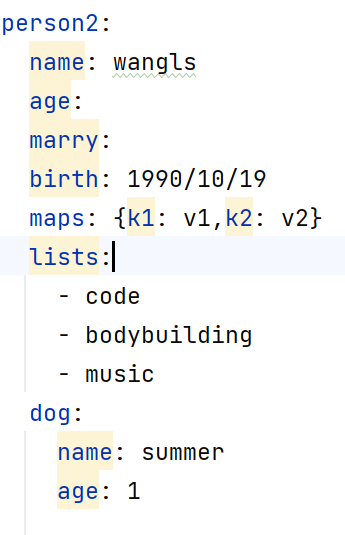
TopK算法
TopK问题基本框架就是:
[!IMPORTANT]
从n个数中,找出最大(或最小)的前k个数。
在我们生活中,经常会遇到TopK问题
比如大众点评的必吃榜;成绩单的前十名;各种数据的最值筛选;

我们应该知道的是
TopK问题的最基本流程包括以下几个阶段:
- 首先对数据进行排序,从小到大或者从大到小
- 直接返回排序后的数组的前k个即可
这是最简单的排序思想,我们可以使用快速排序或者冒泡排序等来实现排序过程
一、冒泡排序
冒泡排序作为常见的排序方法,它在这的核心思想和算法步骤是这样的:
不断比较前后a[i]和a[i+1]两个元素,将较大的那一个往后放;直到冒泡完,最后的k个即为要求TopK元素
代码详解
//冒泡排序的解法
void TopK_BubSort(int* a, int n, int k)
{
for (int i = 0; i < n - 1; i++)
{
for (int j = 0; j < n - 1 - i; j++)//冒泡排序的核心代码
{
int tmp = 0;
if (a[j] > a[j + 1])//进行冒泡排序
{
tmp = a[j];
a[j] = a[j + 1];
a[j + 1] = tmp;
}
}
}
for (int i = n - 1; i >= n - k; i--)//返回排序完之后的k个元素
{
printf("%d ", a[i]);
}
}
时间复杂度
O(n^2)
二、快速排序
第二种排序方法我们可以使用快速排序
//快速排序的解法
void TopK_QuickSort(int* a, int n, int k)
{
QuickSort(a, 0, n - 1, k);
for (int i = n - 1; i >= n - k; i--)
{
printf("%d ", a[i]);
}
}
void QuickSort(int* a, int left, int right, int k)
{
if (left >= right)//当左边大于右边的时候,直接返回即可
{
return;
}
int div = PartSort(a, left, right);//进行快排
if (div == k)//当div等于k的时候,直接返回
{
return;
}
else if (div < k)//当div小于k的时候,继续递归
{
QuickSort(a, div + 1, right, k);
}
else//当div大于k的时候,继续递归
{
QuickSort(a, left, div - 1, k);
}
}
int PartSort(int *a,int left,int right)
{
//设置左右两个指针,分别指向数组的第一个元素和最后一个元素
int begin = left;
int end = right;
int tmp = a[right];//我们选择数组最后一个元素作为基准值
while (begin < end)//快排的核心代码(具体的算法思想自行搜索)
{
while (begin < end && a[begin] >= tmp)
{
begin++;
}
while (begin < end && a[end] <= tmp)
{
end--;
}
if (begin < end)
{
Swap(&a[begin], &a[end]);
}
}
Swap(&a[begin], &a[right]);
return begin;
}
时间复杂度
在最坏的情况下,即每次分区都选择了当前序列的最大或最小元素作为基准值,快速排序的时间复杂度为O(n^2)。但是在平均情况下,快速排序的时间复杂度为O(nlogn)。
O(nlogn)
三、快速选择
快速选择算法是快速排序的变种,利用分治思想,通过不断划分数组,将枢轴(pivot)放在其正确位置,最终找到第k大的元素;同时要注意的是:快速选择需要较好的平均性能且对最坏情况性能要求不高。
int partition(int arr[], int low, int high) {
int pivot = arr[high];
int i = low - 1;
for (int j = low; j < high; j++) {
if (arr[j] >= pivot) {
i++;
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
int temp = arr[i + 1];
arr[i + 1] = arr[high];
arr[high] = temp;
return i + 1;
}
int quickSelect(int arr[], int low, int high, int k) {
if (low <= high) {
int pi = partition(arr, low, high);
if (pi == k - 1)
return arr[pi];
else if (pi > k - 1)
return quickSelect(arr, low, pi - 1, k);
else
return quickSelect(arr, pi + 1, high, k);
}
return -1;
}
void topKQuickSelect(int arr[], int n, int k) {
for (int i = 0; i < k; i++) {
int result = quickSelect(arr, 0, n - 1, i + 1);
printf("%d ", result);
}
printf("\n");
}
时间复杂度:
期望时间复杂度是O(n),但最坏情况为O(n^2)。
O(n)
除了排序以外,实际上还有其他的方法来实现。
四、堆排序
无序地返回TopK
我们了解到TopK的核心思想是找出这k个数,但并非要我们对这k个数也进行排序;所以我们直接使用堆来找出k个数即可。在时间复杂度上会大大降低从而提高时间效率。
具体的算法步骤是这样的:
初始化
首先建一个小堆,将数组的前k个元素放入堆中(注意:这里是前k个元素,而不是最终要求的k个元素,我们最终要返回这个堆,所以初始化也使用k个元素的空间)
比较
将堆顶元素与数组中第k+1个元素以及以后的元素依次进行比较,假设这里我们要得到的是最大的k个元素,那么当数组中元素比堆顶元素大时,就进行交换;
返回
最终当所有元素都比较完后,此时堆中的k个元素就是我们最终要求的那k个元素,返回即可。
代码详解
void TopK_Heap(int* a, int n, int k)
{
HP hp;
HeapInit(&hp);
for (int i = 0; i < k; i++)//先将k个元素放入一个小顶堆中,方便后续用于比较元素的大小
{
HeapPush(&hp, a[i]);
}
for (int i = k; i < n; i++)//从第k+1个元素开始,与堆顶元素进行比较,完成TopK问题的主要流程
{
if (a[i] > HeapTop(&hp))//当前元素比堆顶元素大的时候,将堆顶元素替换为这个元素
{
HeapTop(&hp);//首先弹出堆顶元素
HeapPush(&hp, a[i]);//再将当前元素放入堆中
}
}
while (!HeapEmpty(&hp))//当循环到结束时,这时堆中的元素就是所求的k个元素,将它们先打印再弹出即可、
{
printf("%d ", HeapTop(&hp));//依次打印元素
HeapPop(&hp);//弹出元素
}
//完成一切工作之后,不要忘了销毁这个堆
HeapDestory(&hp);
}
时间复杂度
这个算法的时间复杂度可以分为两个部分来分析。
首先,对于前面的循环,它将前k个元素依次插入堆中,插入一个元素的时间复杂度是O(logk),而循环执行k次,所以这部分的时间复杂度是O(klogk)。
接下来,对于后面的循环,它从第k+1个元素开始,依次与堆顶元素进行比较。如果当前元素比堆顶元素大,就将堆顶元素替换为当前元素,并进行堆的调整。堆的调整操作的时间复杂度是O(logk)。这个循环执行了n-k次,所以这部分的时间复杂度是O((n-k)logk)。
综合起来,这个算法的时间复杂度是O(klogk + (n-k)logk)。从数量级上来看,平均的时间复杂度就是:。
O(nlogk)
需要注意的是,这个算法的时间复杂度是基于堆的操作的时间复杂度,而堆的操作的时间复杂度是基于堆的大小的,即k。因此,这个算法的时间复杂度与k的大小有关。当k较小的时候,算法的时间复杂度较低;当k接近n时,算法的时间复杂度较高。
有序地返回TopK
事实上,如果要求我们有序地返回这k个数的话,我们只需多写一个Sort函数即可。
void HeapSort(int* a, int n)//排序函数
{
for (int i = (n - 1 - 1) / 2; i >= 0; i++)
{
AdjustDown(a, n, i);
}
int end = n-1;
while (end > 0)
{
Swap(&a[end], &a[0]);
AdjustDown(a, end, 0);
end--;
}
}
//TopK排序版
void TopK_Sort(int* a, int n, int k)
{
HeapSort(a, n);//排序完直接返回前k个元素即可
for (int i = n - 1; i >= n - k; i--)
{
printf("%d ", a[i]);
}
printf("\n");
}
总结
读完这篇文章,相信你对TopK问题已经有了大致的了解并且基本知道其算法思想了。
TopK问题是我们生活中也会常常遇见的问题,所以说掌握它的常见算法绝对不是一件坏事。针对上方的几种算法:
- 排序法适用于数据集较小且有排序需求的情况。
- 快速选择法适用于期望时间复杂度较低,能容忍最坏情况的场景。
- 堆排序法适用于数据集较大且k远小于n的情况。
这三种方法各有优缺点,我们可以根据具体需求选择合适的算法,从而在生活和工作中提高时间效率。























![[MySQL][索引][下][理解索引]详细讲解](https://i-blog.csdnimg.cn/direct/6d9e53dda3844ddebaaf2185e88a0969.png)