MySQL 组提交原理
MySQL 中事务的两阶段提交保证了 redo log 与 binlog 两种日志文件的数据一致性,但是并发事务场景下还需要保证事务顺序的一致性,因此通过组提交机制在保证顺序一致性的前提下提高写入效率。因此组提交是两阶段提交的一部分。
两阶段提交
组提交是两阶段提交的一部分,因此首先回顾下两阶段提交(2PC)。其中:
prepare 阶段,其中负责 redo log 刷盘;
commit 阶段,其中负责 binlog 刷盘与存储引擎层面的事务提交。
事务提交的顺序
MySQL 的内部 XA 机制也就是两阶段提交保证了单个事务在 binlog 和 InnoDB 之间的原子性,但是在多个事务并发执行的情况下,怎么保证在 binlog 和 redo log 中事务的顺序一致?
在回答这个问题之前需要明确为什么需要保证 binlog 与 redo log 中事务顺序的一致性?
原因是这种一致性对于保持数据的完整性和一致性、支持高效的数据恢复和复制机制至关重要。其中:
数据恢复,比如基于 binlog 进行按时间点恢复(PITR)时,如果两者顺序不一致,将导致事务以不同的顺序被应用,违法 ACID 原则;
复制一致性,如果两者顺序不一致,将导致主从事务以不同的顺序被应用,从而导致主从数据不一致;
事务原子性,如果两者顺序不一致,将导致事务无法被正确的回滚或提交,可能导致只有部分事务更改被持久化,违反事务的原子性;
避免死锁,如果两者顺序不一致,可能导致恢复或复制过程中发生死锁,尤其是当涉及到多个事务并发修改同一数据行时。
早期解决方法
那么,如何保证 binlog 与 redo log 中事务的顺序一致呢?
MySQL 5.6 版本之前,使用 prepare_commit_mutex 对整个 2PC 过程进行加锁,只有当上一个事务 commit 后释放锁,下个事务才可以进行 prepare 操作,通过串行化的执行方式保证了顺序一致,类似于事务隔离级别中的串行化(Serializable)。
显然 prepare_commit_mutex 的锁机制会严重影响高并发时的性能,原因是多个小 IO 是非常低效的方式,串行化导致响应变慢。
在双 1 条件下,在每个事务执行过程中, 都会至少调用 3 次刷盘操作,包括写 redo log,写 binlog,写 commit。而多个小 IO 是非常低效的方式,因此可能导致写入出现性能瓶颈。为提高并发性能,细化锁粒度,引入组提交(group commit),可以理解为批量提交。
具体又可以分为 binlog 组提交与 redo log 组提交。注意 redo log 与 binlog 都是顺序写,而磁盘的顺序写比随机写速度要快。
组提交
binlog
MySQL 5.6 中针对 binlog 引入组提交功能,prepare 阶段不变,只针对 commit 阶段,将 commit 阶段拆分为三个阶段:
flush:多个线程按进入的顺序将 binlog 从 cache 写入日志文件(binlog write);
sync:将多个线程的 binlog 合并一次刷盘(binlog sync);
commit:各个线程按顺序做 InnoDB commit 操作。
其中:
对于每个子阶段,都可以有多个事务处于该子阶段;
每个子阶段有单独的 lock 进行保护,因此保证了事务写入的顺序。
组提交实现的基本思想是通过批量写入将日志文件的小数据量多次 IO 变为大数据量更少次数 IO,从而提升磁盘 IO 效率。但是为了合并日志的写入、刷盘参数,就需要一个协调者的角色。如果引入一个单独的协调线程,会增加额外开销。MySQL 的解决方案是把处于同一个子阶段的事务线程分为两种角色:
leader 线程,第 1 个进入某个子阶段的事务线程,就是该子阶段当前分组的 leader 线程;
follower 线程,第 2 个及以后进入某个子阶段的事务线程,都是该子阶段当前分组的 follower 线程。事务线程指的是事务所在的那个线程,我们可以把事务线程看成事务的容器,一个线程执行一个事务。leader 线程管事的方式,并不是指挥 follower 线程干活,而是自己帮 follower 线程把活都干了。
commit 细分为 3 个子阶段之后,每个子阶段会有一个
队列用于记录哪些事务线程处于该子阶段。为了保证先进入 flush 子阶段的事务线程一定先进入 sync 子阶段,先进入 sync 子阶段的事务线程一定先进入 commit 子阶段,每个子阶段都会持有一把互斥锁。
这里可以提出一个问题,如何判断是否可以加入队列?
同时进入 prepare 阶段的多个事务必然没有锁冲突,因此不需要判断是否可以加入 flush 阶段,其他阶段入队顺序相同,因此同样没有冲突。
redo log
MySQL 5.7 针对 redo log 引入组提交功能,同时修改 prepare 阶段与 commit 阶段。
5.6 中 redo log 的刷盘操作在 prepare 阶段完成,因此每个事务的 redo log fsync 操作成为性能瓶颈;
5.7 中将 prepare 阶段中每个线程各自执行 redo log fsync 操作推迟到组提交的 flush 阶段之中,binlog fsync 阶段之前。
显然,通过推迟 redo log fsync 的时间,一次组提交中的成员更多,节省 IOPS 的效果更好。
总结
不同版本中两阶段提交过程中 redo log 与 binlog 的写入与刷盘时间对比见下图。
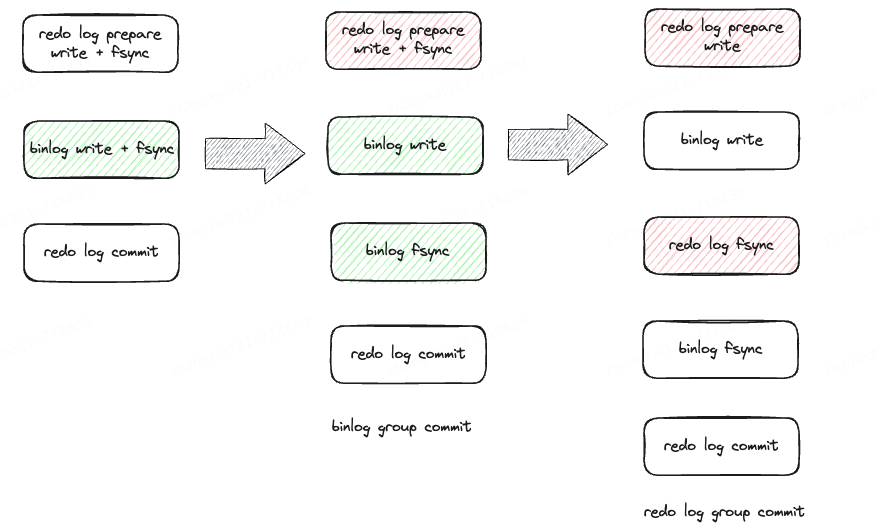
其中:
redo log 与 binlog 中都分开执行 write 与 fsync;
redo log fsync 推迟到 binlog write 之后。
然后,整理下 5.7 中两阶段提交中每个阶段中主要做的事情:
prepare
将 redo log 写入 redo log buffer;
获取上一个事务最大的 sequence number 时间戳;
将事务状态设置为 prepare,具体是将 trx_state_t 从
TRX_STATE_ACTIVE修改为TRX_STATE_PREPARED;将 undo log segment 的状态 TRX_UNDO_STATE 从
TRX_UNDO_ACTIVE修改为TRX_UNDO_PREPARED;将 XID 写入 undo log,然后生成并将 XID_EVENT 写入 binlog cache;
针对 RC 事务隔离级别,释放 gap lock。
commit
redo log write + fsync
binlog write + fsync
存储引擎层事务提交
其中 commit 阶段基于组提交拆分为三个阶段:
flush
redo log write + fsync,针对 prepare 状态的 redo log;
binlog write;
生成 GTID、sequence_number、last_committed,然后生成并将 GTID_EVENT 写入 binlog 文件;
如果 sync_binlog != 1,更新 binlog 位点,唤醒 DUMP 线程给从库发送 EVENT,与主从复制有关。
sync
binlog fsync;
如果 sync_binlog == 1,更新 binlog 位点,唤醒 DUMP 线程给从库发送 EVENT,与主从复制有关;
调用 after_sync,与半同步复制有关。
commit
关闭 MVCC Read view
持久化 GTID
释放 insert undo log
释放锁
生成 gtid event;
将事务状态更新为 TRX_STATE_COMMITTED_IN_MEMORY,表示事务已经完成了二阶段提交的 2 个阶段,还剩一些收尾工作没做,这种状态的事务修改的数据已经可以被其它事务看见了;
存储引擎层事务提交;
调用 after_commit,与半同步复制有关。
其中除了日志写入外,还主要包括主从复制与并行复制。
其中可以明确看到整个过程主要分为三个阶段,包括 flush、sync、commit。
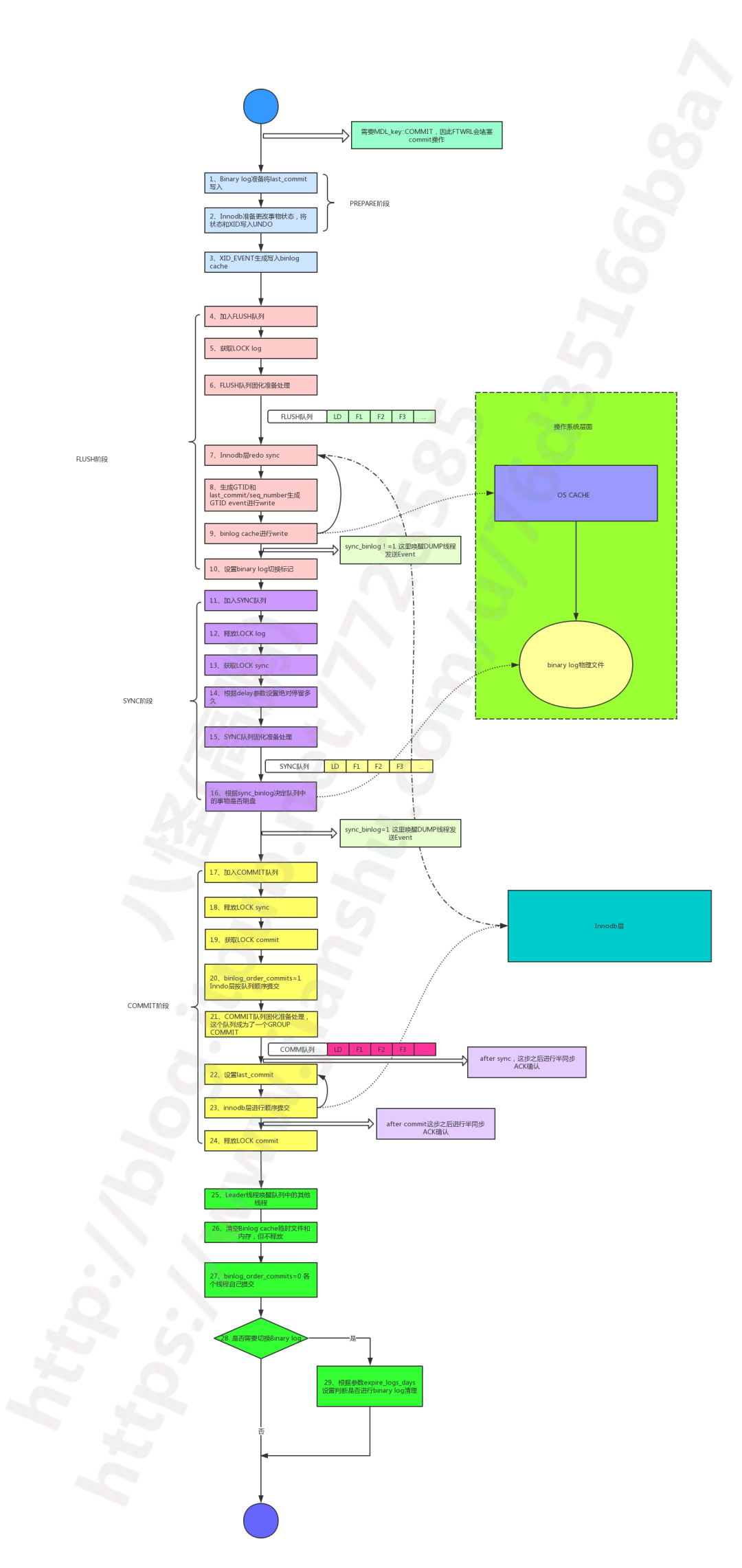
最后,是组提交的具体实现。
前面提到,commit 细分为 3 个子阶段之后,每个子阶段会有一个队列用于记录哪些事务线程处于该子阶段,如下图所示。
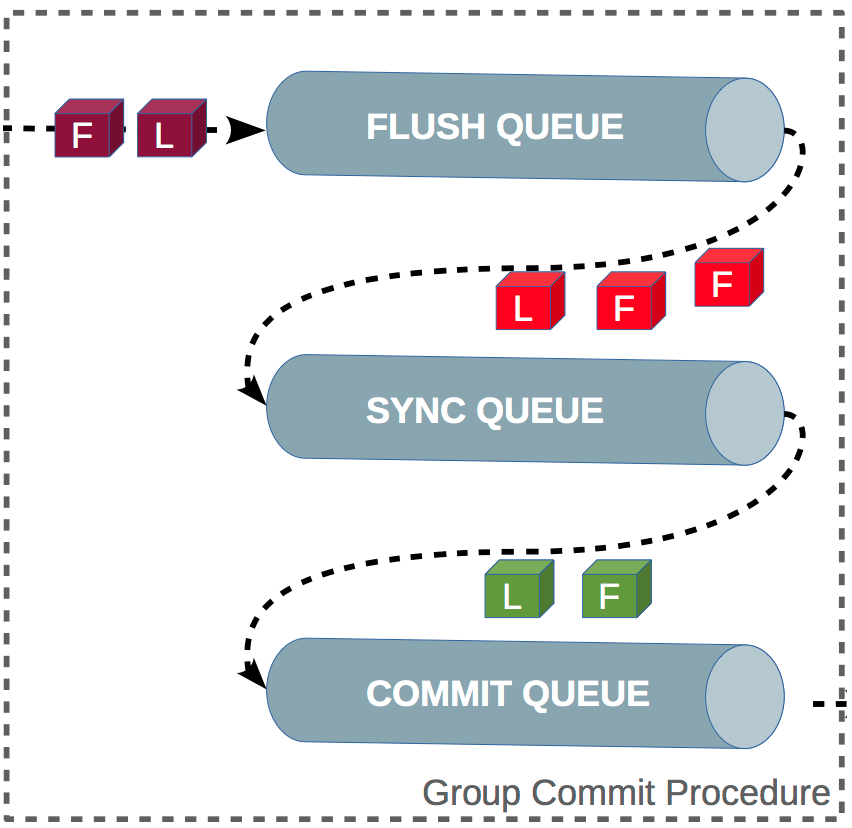
其中:
组提交的原理是将 commit 阶段细分为多个子阶段,其中每个子阶段对应一个队列 + 锁;
队列的作用是通过将多个事务分批,从而实现日志的批量写入与刷盘;
锁的作用是通过给每个队列加锁,因此同一时间每种队列最多只有一个,从而保证多批事务的顺序执行;
每个队列中事务的数量可能不一样,但是事务的顺序一样,保持事务加入到队列的顺序。
下面结合源码分析组提交的实现,其中主要讲解流程,具体源码实现详见参考教程。
实现
trans_commit
事务提交的入口函数是 trans_commit,其中调用 ha_commit_trans 函数。
ha_commit_trans 函数中主要判断是否需要写入 GTID 信息,并开始两阶段提交。
int ha_commit_trans(THD *thd, bool all, bool ignore_global_read_lock)
{
/*
Save transaction owned gtid into table before transaction prepare
if binlog is disabled, or binlog is enabled and log_slave_updates
is disabled with slave SQL thread or slave worker thread.
*/
// 判断是否需要写入 GTID 信息
error= commit_owned_gtids(thd, all, &need_clear_owned_gtid);
...
// prepare 阶段
if (!trn_ctx->no_2pc(trx_scope) && (trn_ctx->rw_ha_count(trx_scope) > 1))
error= tc_log->prepare(thd, all);
// commit 阶段
if (error || (error= tc_log->commit(thd, all)))
{
ha_rollback_trans(thd, all);
error= 1;
goto end;
}
...
}
其中:
注释显示如果关闭 binlog,或者开启 binlog,但是关闭 log_slave_updates 将 GTID 写入 mysql.gtid_executed 表和 @@GLOBAL.GTID_EXECUTED 变量中,就像开启 binlog 一样;
MYSQL_BIN_LOG::commit 函数中调用 MYSQL_BIN_LOG::ordered_commit 函数实现组提交。其中:
分为三个阶段(stage),分别对应组提交中 flush、sync、commit 阶段;
每个阶段的进入都要调用 MYSQL_BIN_LOG::change_stage 函数进行阶段转换。
prepare
MYSQL_BIN_LOG::prepare 函数中调用 MYSQL_BIN_LOG::ha_prepare_low 函数,其中调用 ht->prepare 函数。
prepare 接口由存储引擎层实现,InnoDB 存储引擎初始化注册的函数原型显示 prepare 接口对应 innobase_xa_prepare 函数。
static int innodb_init(void *p) {
...
innobase_hton->commit = innobase_commit;
innobase_hton->rollback = innobase_rollback;
innobase_hton->prepare = innobase_xa_prepare;
innobase_hton->flush_logs = innobase_flush_logs;
...
}
实际上,prepare 阶段又可以分为两步,包括:
binlog prepare,对应 binlog_prepare 函数,其中将上一次 commit 队列中中最大的 sequence number 写入本次事务的 last commit。
InnoDB prepare,对应 innobase_xa_prepare 函数,其中更改事务的状态,并将事务的状态和 XID 写入 undo log。
innobase_xa_prepare 函数中调用 trx_prepare 函数,该函数主体代码如下所示。
// prepare 阶段的主体函数
lsn = trx_prepare_low(trx, &trx->rsegs.m_redo, false);
// 将事务状态设置为 prepare,具体是将 trx_state_t 从 `TRX_STATE_ACTIVE` 修改为 `TRX_STATE_PREPARED`
trx->state = TRX_STATE_PREPARED;
// 事务系统中处于 xa prepared 状态的事务的数量
trx_sys->n_prepared_trx++;
/* Release read locks after PREPARE for READ COMMITTED
and lower isolation. */
// 针对 RC 事务隔离级别,释放 gap lock
if (trx->isolation_level <= TRX_ISO_READ_COMMITTED) {
/* Stop inheriting GAP locks. */
trx->skip_lock_inheritance = true;
/* Release only GAP locks for now. */
lock_trx_release_read_locks(trx, true);
}
其中:
调用 trx_prepare_low 函数,该函数是 prepare 操作的主体函数;
修改事务的状态,并更新事务系统中处于 xa prepared 状态的事务的数量;
针对 RC 事务隔离级别,释放 gap lock。
trx_prepare_low 函数中主要调用以下两个函数:
调用 trx_undo_set_state_at_prepare 函数,其中修改 undo 的状态并将 XID 写入 undo log;
// 1. 将 undo log segment 的状态从 TRX_UNDO_ACTIVE 修改为 TRX_UNDO_PREPARED
undo->state = TRX_UNDO_PREPARED;
// 2. undo log 写入事务 XID
undo->xid = *trx->xid;
/*------------------------------*/
trx_undo_write_xid(undo_header, &undo->xid, mtr);
调用 mtr_commit 函数,其中将 mtr 中的 redo log 拷贝到 log buffer 中,m_log 链表是由一个一个 block 组成的链表。
// 拷贝redo日志到redo buffer空间
m_impl->m_log.for_each_block(write_log);
显然,prepare 阶段中将 redo log 写入缓冲区,而 binlog 是在事务执行过程中而不是提交时写入缓冲区。
prepare 阶段完成过后,进入两阶段提交的 commit 阶段,根据组提交机制,其中又细分为多个阶段。
change_stage
阶段转换主要用于实现队列,对应 MYSQL_BIN_LOG::change_stage 函数。
其中将处于同一个子阶段的事务线程分为两种角色,包括 leader 与 follower。
主要流程为:
线程入队,具体是链表操作,其中:
leader 线程会获取一把互斥锁,保证同一时间特定子阶段只有一个 leader 线程;
leader 负责提交整组事务,提交完成后,发送 m_stage_cond_binlog 信号变量唤醒挂起的 follower;
进入队列的第一个线程会作为整组事务的 leader,其中:
后续进入队列的线程会作为整组事务的 follower,follower 线程挂起等待 m_stage_cond_binlog 信号变量唤醒。
释放上一阶段的互斥锁
申请下一阶段的互斥锁
注意其中线程先入队,再释放上一阶段的 lock,最后申请下一阶段的 lock。
因此在指定 stage 线程入队完成之前没有其他线程可以入队,这样保证了每个时刻,每个 stage 都只有一个线程在执行,从而保证了线程的顺序性。反之,如果先释放上一个 stage lock,再申请入队,后面的线程就可能赶上来,同时申请入队,从而无法保证顺序性。
flush stage
flush stage 对应 MYSQL_BIN_LOG::process_flush_stage_queue 函数。
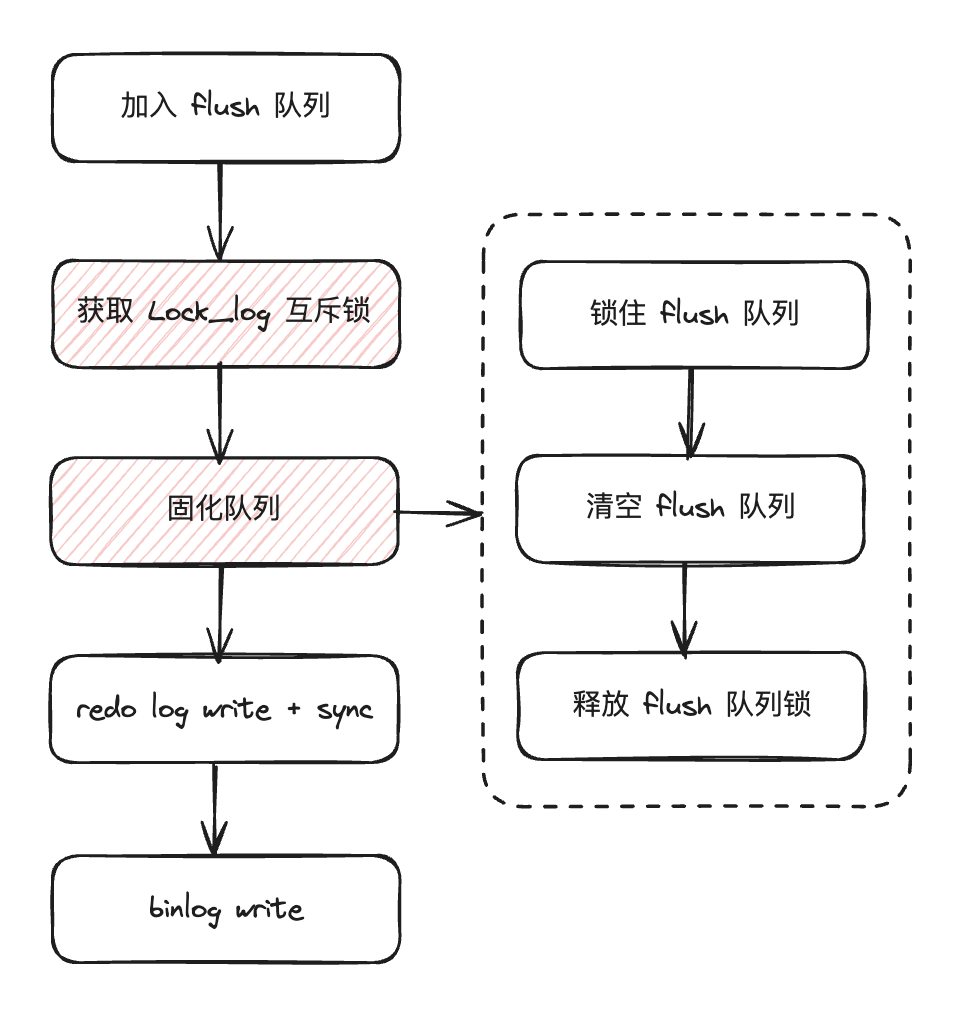
flush 阶段 leader 线程的主要流程见下图。
其中:
加入 flush 队列,分为 leader 与 follower;
获取 Lock_log 互斥锁;
固化队列,对应 fetch_queue_for 函数,锁住 flush 队列用于将在此之前进入 flush 队列的所有事务线程作为一组,其中:
清空 flush 队列;
队列清空后通过线程对象 thd 的 next_to_commit 属性指向下一个加入 flush 队列的线程;
队列清空后进入 flush 队列的事务线程属于下一组,其中第一个是下一组的 leader 线程,但需要等待前一组释放锁。
释放 flush 队列锁,注意当前组的 leader 线程持有的 Lock_log 锁要等到 sync 阶段才会释放;
redo log 刷盘(sync),对应 innobase_flush_logs 函数 ,根据
innodb_flush_log_at_trx_commit参数判断是否刷盘。其中:0,组提交时 redo log 不刷盘,由后台线程刷盘;
1,组提交时 redo log 刷盘;
2,执行 FLUSH LOG 命令时 redo log 刷盘,否则由操作系统刷盘,比如 xtrabackup 备份中使用该命令。
binlog 写入日志文件(write),对应 flush_thread_caches 函数,将一组事务线程的 binlog 从临时存放点(binlog cache,trx_cache)拷贝到日志文件。
注意:
binlog_max_flush_queue_time 参数用于控制 flush 阶段 leader 的等待时间,因此一组中可以加入更多 follower。不过该参数在 5.6 版本引入,从 5.7.9 版本开始弃用;
源码显示 flush 阶段先进行 redo log sync,然后进行 binlog write,与前面组提交概念部分介绍的流程不同。
sync stage
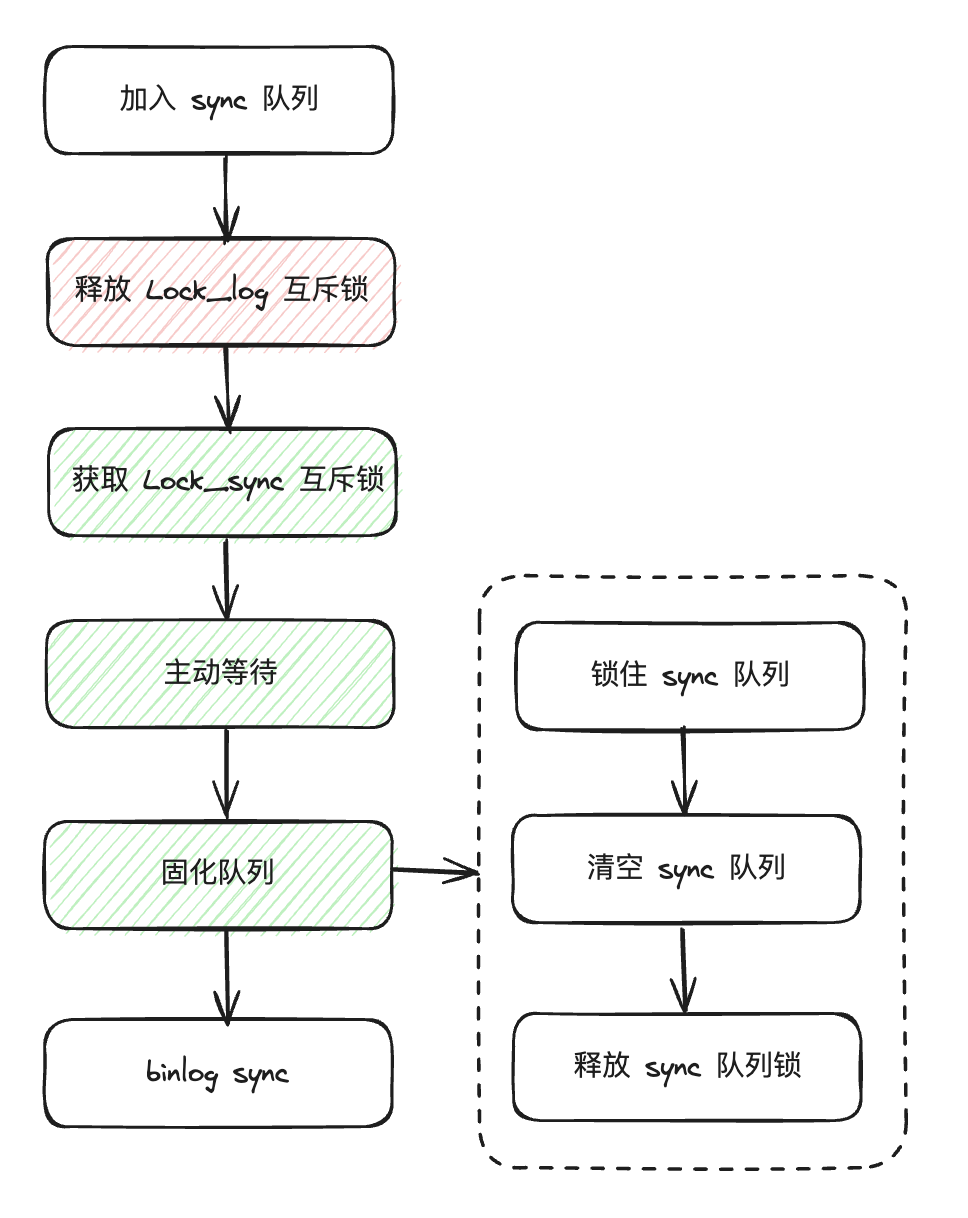
sync 阶段 leader 线程的主要流程见下图。
其中:
将 flush 队列从 flush 阶段转换成 sync 阶段;
释放 Lock_log 互斥锁;
获取 Lock_sync 互斥锁;
等待更多事务线程进入 sync 阶段,目的是一组中可以加入更多 follower,这也是 sync 阶段的主要流程;
等待完成后固化队列;
binlog 刷盘。
通常 binlog 的 write 和 sync 之间的间隙时间短,组提交的效果不如 redo log,因此引入等待机制用于提升 binlog 组提交的效果。
具体通过 leader 线程等待使更多事务线程进入 sync 阶段,分为以下两步:
判断是否刷盘,根据 sync_binlog 参数判断:
sync_binlog = 1 时每个 leader 线程都会刷盘;
sync_binlog = N 时每 N 个 leader 线程刷盘一次,并将 sync_counter 重置为 0。
不满足 sync_counter + 1 >= sync_binlog 条件时 leader 线程等待,且 sync_counter + 1,表示一个 leader 线程没有刷盘。因此:
满足条件时该 leader 线程刷盘,并将 sync_counter 变量的值清零,重新开始计数;
判断刷盘前的等待时间,根据以下两个参数判断,满足其中一个条件就会调用 fsync 刷盘:
binlog_group_commit_sync_delay,表示延迟多少微秒后才调用 fsync,默认 0,表示跳过等待;
binlog_group_commit_sync_no_delay_count,表示累积多少次以后才调用 fsync,默认 0,表示跳过等待。
commit stage
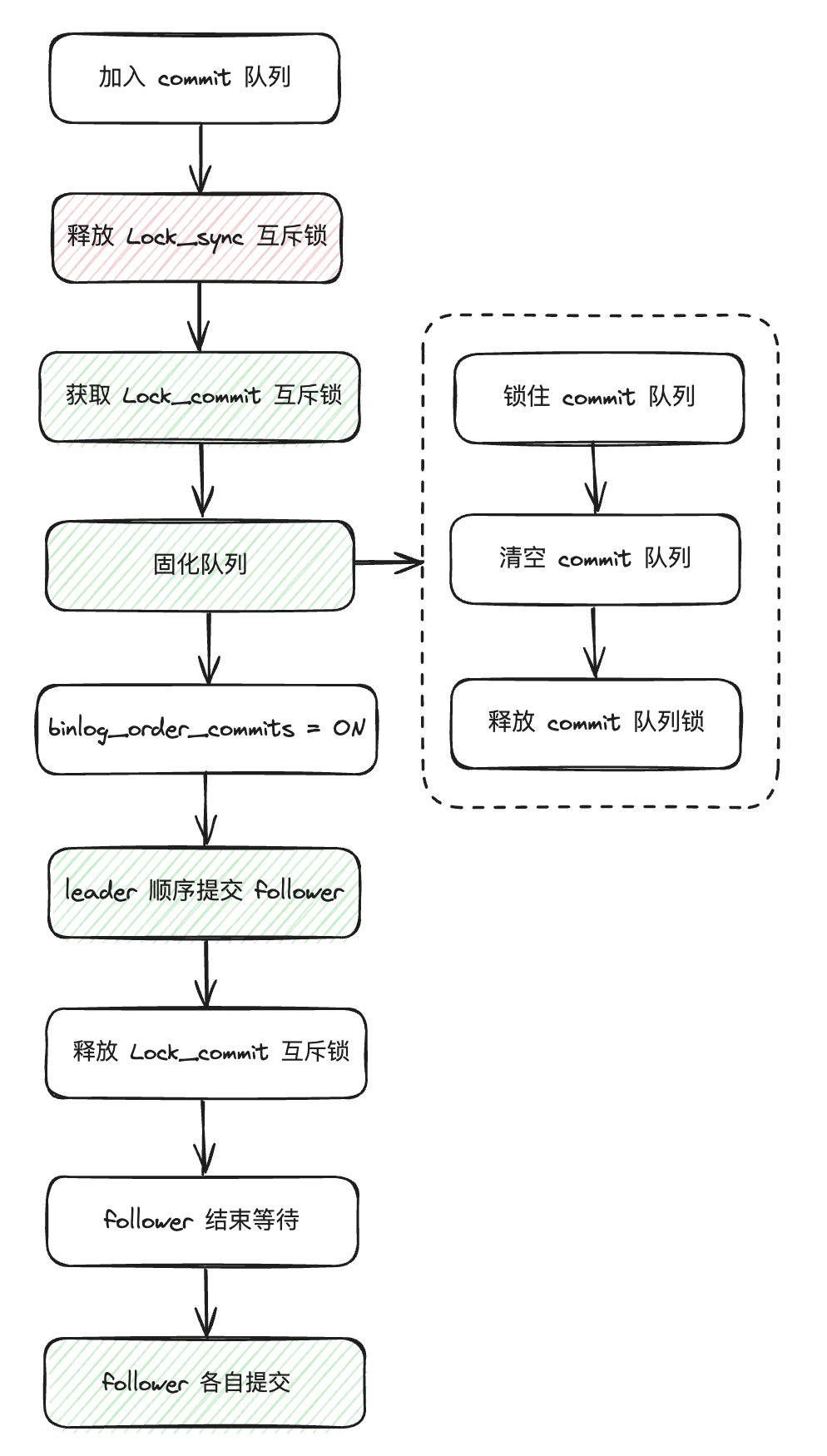
leader 阶段 leader 线程的主要流程见下图。
其中:
将 sync 队列从 sync 阶段转换成 commit 阶段;
释放 Lock_sync 互斥锁;
获取 Lock_commit 互斥锁;
固化队列;
事务提交,binlog_order_commits 参数控制 leader 线程除了提交自己的事务,是否提交 follower 线程的事务,默认 ON,表示是;
如果 binlog_order_commits = ON,leader 线程提交 follower,对应 process_commit_stage_queue 函数,内部调用 trx_commit_low 函数,按照队列顺序提交事务;
释放 Lock_commit 互斥锁;
提交完成后通知 follower 线程结束等待;
如果 binlog_order_commits = OFF,follower 线程自行提交,对应 finish_commit 函数,多线程分别提交事务,不保证 commit 的顺序。
storage engine commit
存储引擎层的事务提交主要对应 innobase_commit 函数,其中主要流程包括:
这里说的事务提及包括提交与回滚,原因是回滚与正常事务提交一样,也需要释放事务所持有的资源。这些资源包括:undo 段、锁、read view。同时为了满足事务持久性的要求,需要刷新重做日志文件,确保事务的重做日志都已经写入外存。因此,事务提交时具体所做的操作包括:
如果事务含有 insert_undo log,将 undo 段段状态设置为 TRX_UNDO_TO_FREE(函数 trx_undo_set_state_at_finish);
如果事务含有 update_undo log,将 undo 段段状态设置为 TRX_UNDO_TO_PURGE 或 TRX_UNDO_TO_CACHED(函数 tax_undo_set_state_at_finish);
如果 MySQL 上层开启二进制日志。更新 InnoDB 存储引擎的事务系统段,写入上层的二进制日志信息(函数 trx_sys_update_mysql_binlog_offset);
如果事务 read view 对象非空,清理 read view 对象(函数 read_view_close),并释放对应的内存(函数 mem_heap_empty);
如果参数 innodb_flush_log_at_trx_commit 设置为 1,刷新重做日志,确保重做日志都已经写入外存(函数 log_finish_up_to);
最后将事务对象从事务链表中删除。
innobase_commit 函数中最终调用 trx_commit_in_memory 函数完成内存中的事务提交,该函数主体代码如下所示。
// 释放锁并修改事务的状态
lock_trx_release_locks(trx);
// 关闭 mvcc read view
trx_sys->mvcc->view_close(
trx->read_view, false);
// 释放insert undo log
trx_undo_insert_cleanup(&trx->rsegs.m_redo, false);
其中调用 lock_trx_release_locks 函数释放锁并修改事务的状态。
/* The following assignment makes the transaction committed in memory
and makes its changes to data visible to other transactions.
NOTE that there is a small discrepancy from the strict formal
visibility rules here: a human user of the database can see
modifications made by another transaction T even before the necessary
log segment has been flushed to the disk. If the database happens to
crash before the flush, the user has seen modifications from T which
will never be a committed transaction. However, any transaction T2
which sees the modifications of the committing transaction T, and
which also itself makes modifications to the database, will get an lsn
larger than the committing transaction T. In the case where the log
flush fails, and T never gets committed, also T2 will never get
committed. */
// 事务组提交 commit 阶段中将事务状态更新为TRX_STATE_COMMITTED_IN_MEMORY, 到这里事务提交就完成了
/*--------------------------------------*/
trx->state = TRX_STATE_COMMITTED_IN_MEMORY;
/*--------------------------------------*/
// 释放所有行锁
lock_release(trx);
trx->lock.n_rec_locks = 0;
trx->lock.table_locks.clear();
其中:
将内存中事务状态更新为 TRX_STATE_COMMITTED_IN_MEMORY,在此之后,事务的更新对其他事务可见;
注释显示假设事务 T2 在看到事务 T 的更新后又更新了数据,将获得一个大于提交中事务 T 的 LSN,如果在事务 T 的日志刷盘之前数据库崩溃,T 会提交失败,T2 也会提交失败。
知识点
互斥锁
组提交中为了避免每个子阶段中出现多个 leader,每个阶段中引入一个锁。每种锁的定义如下所示,显示类型都是 mysql_mutex_t,表明是互斥量。
mysql_mutex_t LOCK_log;
mysql_mutex_t LOCK_commit;
mysql_mutex_t LOCK_sync;
最底层锁的类型是 __darwin_pthread_mutex_t。
typedef __darwin_pthread_mutex_t pthread_mutex_t;
__darwin_pthread_mutex_t 的定义参考 chatgpt。
__darwin_pthread_mutex_t是在 Darwin 操作系统中定义的一个数据结构,用于表示 POSIX 线程(pthread)的互斥锁(mutex)。Darwin 是 Apple Inc. 开发的一个开源操作系统,它是 macOS、iOS、iPadOS、tvOS 和 watchOS 的核心。这个数据结构是在 Darwin(以及基于它的操作系统,如 macOS)系统级别的 C 语言库中定义的,用于实现线程间的同步。互斥锁是一种同步机制,用于防止多个线程同时访问同一资源或代码块。当一个线程锁定(或获取)一个互斥锁时,其他任何尝试锁定同一个互斥锁的线程都会被阻塞,直到拥有锁的线程释放(或解锁)该互斥锁。
__darwin_pthread_mutex_t的具体实现细节对于应用程序开发者来说是透明的,因为它们通常使用更高级别的同步原语,如pthread_mutex_lock、pthread_mutex_unlock等 POSIX 线程库提供的函数来操作互斥锁。
EVENT
事务提交阶段中自动生成两个 EVENT,包括:
XID_EVENT,两阶段提交中 prepare 阶段生成,写入 binlog cache;
GTID_EVENT,组提交中 flush 阶段生成,直接写入 binlog 文件,不写入 binlog cache,因此是事务的第一个 event。
注意这两个事务提交阶段生成的 event 是 commit 命令发起的时间,其他 event 是 DML / DDL 命令发起的时间。
总结
两阶段提交中存在以下两个问题:
多个小 IO 的写入效率
binlog 与 redo log 顺序的一致性
为了解决这些问题,针对两阶段提交,引入组提交机制。
其中:
将 commit 阶段拆分为三个阶段,其中每个子阶段对应一个队列 + 锁;
队列的作用是通过将多个事务分批,从而实现日志的批量写入与刷盘;
锁的作用是通过给每个队列加锁,因此同一时间每种队列最多只有一个,从而保证多批事务的顺序执行;
每个队列中事务的数量可能不一样,但是事务的顺序一样,保持事务加入到队列的顺序。
两阶段提交的 prepare 阶段中主要做的事情包括:
binlog prepare
InnoDB prepare,将 redo log 写入缓冲区,而 binlog 是在事务执行过程中而不是提交时写入缓冲区。
组提交的三个阶段分别主要做的事情包括:
flush,redo log write + sync,binlog write;
sync,binlog sync,其中为了提高 binlog 组提交的性能,引入等待机制,通过参数控制;
commit,存储引擎层事务提交,提交后事务可见。
其中:
组提交的优点是可以提高写入性能,缺点是可能导致单个事务响应变慢。
组提交相关参数包括:
binlog_group_commit_sync_delay,表示延迟多少微秒后才调用 fsync,默认 0,表示跳过等待;
binlog_group_commit_sync_no_delay_count,表示累积多少次以后才调用 fsync,默认 0,表示跳过等待;
binlog_order_commits,控制存储引擎层的事务提交顺序,默认 ON 表示事务提交顺序与 binlog 写入顺序相同,设置为 OFF 时可能导致主从数据不一致。
因此,如果需要提高组提交的性能,可以调整以上参数。
MySQL8.0发生的大变更
3.1、移除查询缓存(Query Cache)
Query Cahce查询缓存的设计初衷很好,也就是利用热点探测技术,对于一些频繁执行的查询SQL,直接将结果缓存在内存中,之后再次来查询相同数据时,就无需走磁盘,而是直接从查询缓存中获取数据并返回。
select * from zz_users where user_id=1;
select * from zz_users where user_id = 1;比如上述这两条SQL语句,都是在查询ID=1的用户数据,MySQL的查询缓存会把它当做两条不同的SQL,也就是假如上面的第一条SQL,其查询结果被放入到了缓存中,第二条SQL依旧无法命中这个缓存,会继续走表查询的形式获取数据,Why?
因为
MySQL查询缓存是以SQL的哈希值来作为Key的,上面两条SQL虽然一样,但是后面的查询条件有细微差别:user_id=1、user_id = 1,也就是一条SQL有空格,一条没有。
由于这一点点细微差异,会导致两条SQL计算出的哈希值完全不同,因此无法命中缓存。还有多种情况:user_id =1、user_id= 1,空格处于的前后位置不同,也会导致缓存失效。
查询缓存在
MySQL8.0中被完全舍弃了,即移除掉了查询缓存区,各方面原因如下:
①缓存命中率低:几乎大部分
SQL都无法从查询缓存中获得数据。②占用内存高:将大量查询结果放入到内存中,会占用至少几百
MB的内存。③增加查询步骤:查询表之前会先查一次缓存,查询后会将结果放入缓存,额外多几步开销。
④缓存维护成本不小,需要
LRU算法淘汰缓存,同时每次更新、插入、删除数据时,都要清空缓存中对应的数据。⑤查询缓存是专门为
MyISAM引擎设计的,而InnoDB构建的缓冲区完全具备查询缓存的作用。
因为上述一系列原因,再加上项目中一般都会使用Redis先做业务缓存,因此能来到MySQL的查询语句,几乎都是要从表中读数据的,所以查询缓存的地位就显得更加突兀,所以在8.0版本中就直接去掉了,毕竟弊大于利,带来的收益达不到设计时的预期。
3.2、锁机制优化
在MySQL8.0中的锁机制主要出现了两点优化,一方面对获取共享锁的写法进行了优化,如下:
-- MySQL8.0之前的版本
SELECT ... LOCK IN SHARE MODE;
-- MySQL8.0及后续的版本
SELECT ... FOR SHARE;第二方面则支持非阻塞式获取锁机制,可以在获取锁的写法上加上NOWAIT、SKIP LOCKED关键字,这样在未获取到锁时不会阻塞等待,使用SKIP LOCKED未获取到锁时会直接返回空,使用NOWAIT会直接返回并向客户端返回异常。用法如下:
select ... for update nowait;
select ... for update skip locked;3.3、在线修改的系统参数支持持久化
在之前的版本中,通过set、set global的形式修改某个系统变量时,这种方式设置的参数值都是一次性的,也就是修改过的参数并不会被同步到本地,当MySQL重启时,这些调整过的参数又会回归默认值,如果想要让调整过的参数生效,就必须要手动停止MySQL,然后去修改my.ini/my.conf文件,修改完成后再重启数据库服务,这时才能让参数永久生效。
在做数据库线上调优时,修改参数后重启又会失效,有时重启忘记再次调整参数,最终导致数据库服务出现问题,这种体验令人很糟心。
而在MySQL8.0中则彻底优化了这个问题,推出了在线修改参数后,支持持久化到本地文件的机制,也就是通过SET PERSIST命令来完成,如下:
-- 调整事务的隔离级别(针对于当前连接有效)
set transaction isolation level read uncommitted;
-- 调整事务的隔离级别(针对于全局有效,重启后会丢失)
set global tx_isolation = "read-committed";
-- 调整事务的隔离级别(针对于全局有效,并且会持久化到本地,重启后不会丢失)
set persist global.tx_isolation = "repeatable-read";通过set persist命令持久化的参数,可以通过下述命令来查看:
select * from performance_schema.persisted_variables;这条命令的本质其实是:基于MySQL自带的performance_schema监控库查询持久化过的参数。
其实参数持久化的原理也非常简单,当执行
set persist命令时,会将改变过的参数写入到本地的mysqld-auto.cnf文件中,MySQL每次启动时都会读取这个文件中的值,如果该文件中存在参数,则会直接将其加载,从而实现了一次修改,永久有效。
但当你想要参数不再持久化到本地时,可以选择删除安装目录下的mysqld-auto.cnf文件,或执行reset persist命令来清除,但这两种方式都只对下次重启时生效,毕竟本次参数已经被载入内存了,所以只能通过再次手动修改的方式复原。
3.4、增强多表连接查询
在之前的MySQL版本中,仅支持交叉连接、内连接、左外连接、右外连接四种连接类型,这四种连接都会采用默认的连接算法,而在8.0版本中提供了哈希连接、反连接两种连接优化的支持。
3.1.1、哈希连接(Hash Join)
所谓的哈希连接其实并非一种新的连表方式,而是一种连表查询的算法,在关系型数据库中多表连查一般有三种算法:Hash-Join哈希散列连接、Sort-Merge-Join排序合并连接、Nest-Loop-Join嵌套循环连接,这三种连表算法在Oracle数据库中都支持,但MySQL之前的版本中,所有的连表方式都仅支持Nest-Loop-Join嵌套循环连接。
而到了
MySQL8.0.18版本发布后,MySQL对内连接的方式支持了哈希连接算法,那究竟啥叫哈希连接算法呢?和之前传统的循环连接算法又有啥区别呢?
哈希连接算法和循环连接算法的区别
先来看看传统的循环连接算法的连表查询过程是怎么样的呢?如下:
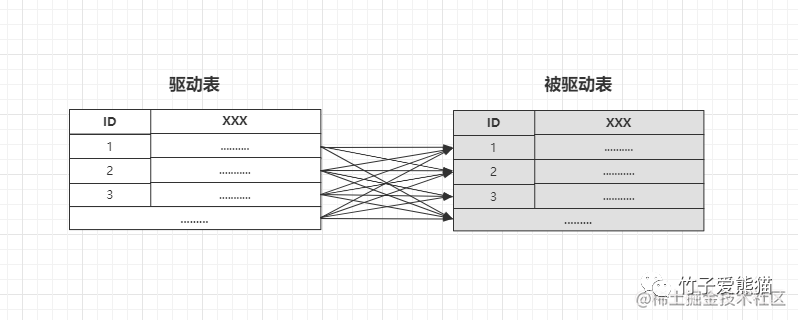
循环连接
在循环连接算法中,会首先选择一张小表作为驱动表,然后依次将驱动表中每一条数据作为条件,去被驱动表中做遍历,最终得到符合连接条件的所有数据,也就是会形成一个下述的伪逻辑:
for(数据 x : 驱动表){
for(数据 y : 被驱动表){
if (x == y){
// 如果符合连接条件,则记录到连接查询的结果集中.....
}
}
}这种循环连接的算法中,显然会造成巨大的开销,因为驱动表每条数据都需要和被驱动表的完整数据做一次遍历。也正是为了解决这个问题,因为MySQL8.0中引入了哈希连接算法,过程如下:
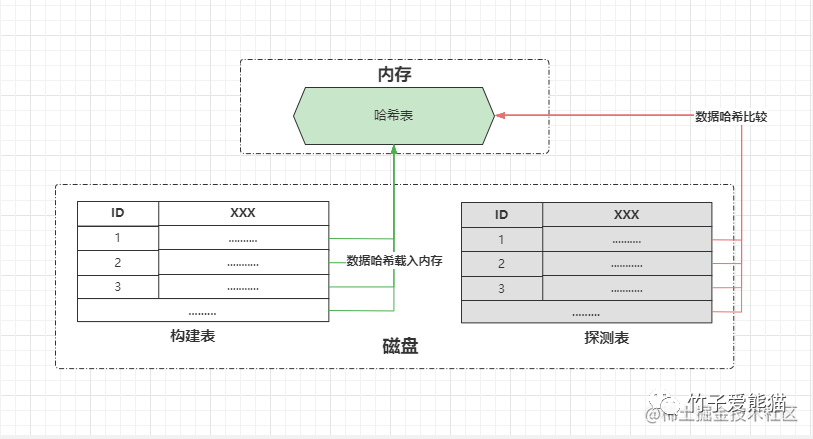
哈希连接
在哈希连接算法中会分为两个阶段:
构建阶段:选择一张小表作为构建表,接着会基于连接字段做哈希处理,生成哈希值放入内存中构建出一张哈希表。
探测阶段:遍历大表的每一行数据,然后对连接字段做哈希处理,通过生成的哈希值与内存哈希表做比较,符合条件则放入结果集中。
对比之前的循环连接算法,这种哈希连接算法带来的性能提升直线提升N倍,因为在循环连接算法中,需要遍历count(驱动表)次,即驱动表中有多少条数据就要遍历多少次。而在这种算法中,只需要将大表遍历一次,伪逻辑代码如下:
// 构建阶段:将小表的每行数据,根据哈希值放入内存哈希表中
MaphashTable=newHashMap();
for(数据 x :构建表){
hashTable.put(x);
}
// 探测阶段:遍历大表的每行数据与内存哈希表做连接匹配
for(数据 y :探测表){
if(hashTable.get(y)!=null){
// 如果哈希处理后能够在内存哈希表中存在,
// 则表示这条数据符合连接条件,则记录到连接查询的结果集中.....
}
}哈希连接对比循环连接算法而言,主要在两方面可以得到性能提升:
①哈希连接算法中,只需要将大表遍历一次,但循环连接算法需要遍历
N次。②哈希连接探测阶段,做连接判断时只需要先对数据做一次哈希处理,然后在内存中查找即可,复杂度仅为
O(1),但循环连接算法的复杂度为O(n)。
哈希连接算法的致命问题
但虽然哈希连接算法能够带来卓越的性能提升,但也存在一个致命问题,就是内存中join_buffer_size的容量无法完全载入构建表的哈希数据时怎么办呢?这里就有两种解决方案:
①分批处理,将构建表的数据拆分为几部分,每次载入一部分到内存,但这样会导致大表的遍历次数,随着分批次数变大而增多。
②利用磁盘完成,也就是首先将构建表的所有数据做哈希处理,放不下时将一部分处理好的哈希数据放入磁盘,在探测阶段遍历大表时,每次对大表数据生成哈希值后,做判断时从磁盘依次读取处理好的哈希值做判断。
而MySQL中选择的是第二种,也就是当内存无法完全放下构建表的哈希数据时,会采用磁盘+内存混合的模式执行哈希连接。
MySQL什么情况下会选用哈希连接?
首先并不是多表连接的情况下都会使用哈希连接算法,该算法有几个硬性限制:
①目前哈希连接算法仅支持内连接的多表连查方式。
②哈希连接算法必须要求存在等值连接条件,即
a.id=b.id才行,a.id>b.id是不行的。③如果连接字段可以走索引查询的情况下,默认依旧会采用循环连接算法。
第二点的原因在于:哈希连接算法生成的哈希值是无序的,所以必须要用等值连接才行。
第三点的原因在于:连接查询时走索引的效率并不低,哈希连接需要生成哈希表,因此需要时间,因此在能够走索引连表的情况下,哈希连接算法的效率反而比不上循环连接。
也就是说,当连表时存在等值连接条件,并且未命中索引的情况下,
MySQL默认会采用哈希连接算法来完成连表查询,不过还有一种情况也会使用,就是笛卡尔积情况,即不指定连接条件的情况下也会使用哈希连接,此时MySQL会直接对整条数据生成哈希表。
对于哈希连接算法,MySQL是默认开启的,咱们可通过set optimizer_switch="hash_join=off";的形式来手动控制开关。
3.1.2、反连接(Anti Join)
反连接是MySQL8.0对于一些反范围查询操作的优化,主要针对于下述几种情况会做优化:
NOT IN (SELECT … FROM …)NOT EXISTS (SELECT … FROM …)IN (SELECT … FROM …) IS NOT TRUEEXISTS (SELECT … FROM …) IS NOT TRUEIN (SELECT … FROM …) IS FALSEEXISTS (SELECT … FROM …) IS FALSE
在MySQL早些版本中,使用NOT EXISTS、NOT IN、IS NOT...这类操作时有可能会导致索引失效,而且也会让查询效率变低,因此MySQL8.0版本中会对上述几类语句进行优化,当你的SQL语句使用了上述语法检索数据时,在MySQL内部会将其转变为反连接类型的查询语句。
也就是会将右边的子查询结果集,变为一张物理临时表,然后基于条件字段做连接查询,官方号称在某些场景下,能够让上述几类语句的查询性能提升
20%。
3.5、增强索引机制
在8.0中官方再一次对索引机制动刀,首先对联合索引提供了一种跳跃扫描机制的支持,也就意味着使用联合索引时,就算未遵循最左前缀匹配原则,也可以使用联合索引来检索数据。除此之外,还有另外三种新的索引特性:隐藏索引、降序索引以及函数索引。
3.5.1、索引跳跃式扫描机制(Index Skip Scan)
最左前缀匹配原则,就是SQL的查询条件中必须要包含联合索引的第一个字段,这样才能命中联合索引查询,但实际上这条规则也并不是100%遵循的。因为在MySQL8.0版本中加入了一个新的优化机制,也就是索引跳跃式扫描,这种机制使得即使查询条件中,没有使用联合索引的第一个字段,也依旧可以使用联合索引,看起来就像跳过了联合索引中的第一个字段一样,这也是跳跃扫描的名称由来。
但跳跃扫描究竟是怎么实现的呢?
比如此时通过(A、B、C)三个列建立了一个联合索引,此时有如下一条SQL:
SELECT * FROM `tb_xx` WHERE B = `xxx` AND C = `xxx`;按理来说,这条SQL既不符合最左前缀原则,也不具备使用索引覆盖的条件,因此绝对是不会走联合索引查询的,但思考一个问题,这条SQL中都已经使用了联合索引中的两个字段,结果还不能使用索引,这似乎有点亏。因此MySQL8.x推出了跳跃扫描机制,但跳跃扫描并不是真正的“跳过了”第一个字段,而是优化器为你重构了SQL,比如上述这条SQL则会重构成如下情况:
SELECT *FROM`tb_xx`WHERE B =`xxx`AND C =`xxx`
UNIONALL
SELECT*FROM`tb_xx`WHERE B =`xxx`AND C =`xxx`AND A ="yyy"
......
SELECT*FROM`tb_xx`WHERE B =`xxx`AND C =`xxx`AND A ="zzz";其实也就是MySQL优化器会自动对联合索引中的第一个字段的值去重,然后基于去重后的值全部拼接起来查一遍,一句话来概述就是:虽然你没用第一个字段,但我给你加上去,今天这个联合索引你就得用,不用也得给我用。
跳跃扫描机制在
Oracle中早就有了,但为什么MySQL8.0版本才推出这个机制呢?MySQL几经转手后,最终归到了Oracle旗下,因此跳跃扫描机制仅是Oracle公司:从Oracle搬到了“自己的MySQL”上而已。
但是跳跃扫描机制也有很多限制,比如多表联查时无法触发、SQL条件中有分组操作也无法触发、SQL中用了DISTINCT去重也无法触发等。
其实这个跳跃性扫描机制,只有在唯一性较差的情况下,才能发挥出不错的效果,如果你联合索引的第一个字段,是一个值具备唯一性的字段,那去重一次再拼接,几乎就等价于走一次全表。
对于索引跳跃扫描机制,可以通过set @@optimizer_switch = 'skip_scan=off|on';命令来选择开启或关闭跳跃式扫描机制。
3.5.2、隐藏索引
隐藏索引并不是一种新的索引类型,而是一种对索引的骚操作,可以理解为对每个索引新增了一个开关按键,主要用于测试环境和灰度场景,在MySQL8.0版本中,可以通过INVISIBLE、VISIBLE来控制索引的开关:
当对一个索引使用
INVISIBLE后,会关闭这个索引,优化器在执行SQL时无法发现和使用它。当对一个索引使用
VISIBLE后,会将索引从隐藏状态恢复到正常状态。
所谓的隐藏索引,就是指将一个已经创建的索引“藏起来”,被藏起来的索引是无法被优化器探测到的,因此执行SQL语句时,就算语句中显式使用了索引字段,优化器也不会选择走这条索引。
这个特性主要是针对于调优、测试场景而研发的,如果隐藏一个索引后,在压测场景下不会对业务产生影响,如果经过反复测试后依旧不影响
SQL性能,那这条索引则可以被判定为无用索引,可以将其删除,隐藏索引的用法如下:
-- 隐藏某张表上已存在的一个索引
alter table 表名 alter index 索引名 invisible;
-- 恢复某张表上已存在的一个索引
alter table 表名 alter index 索引名 visible;3.5.3、降序索引
Descending index降序索引是一种索引的特性,不知大家是否还记得之前定义索引的语句呢,如下:
ALTER TABLE tableName ADD INDEX indexName(columnName(length) [ASC|DESC]);在创建索引时,可以通过ASC、DESC来定义一个索引是按升序还是降序存储索引键,但本质上这种语法,在MySQL8.0之前,就算你手动写明了DESC降序,在创建时依旧会默认忽略,也就是本质上还是按升序存储索引键的,当你要对某个倒序索引的字段做倒序时,依旧会发生filesort排序的动作。
到了
MySQL8.0官方正式支持降序索引,也就是当对一个字段建立降序索引后,做降序查询时不需要再次排序,可直接根据索引进行取值。
下面来基于MySQL5.1、MySQL8.0举个简单的例子感受一下:
-- 分别在 MySQL5.1、MySQL8.0 中创建一张 zz_table 表
create table zz_table (
id1 int,
id2 int,
index idx1 (id1 ASC, id2 ASC),
index idx2 (id1 ASC, id2 DESC),
index idx3 (id1 DESC, id2 ASC),
index idx4 (id1 DESC, id2 DESC)
);
insert into zz_table values(1,2);上述创建了一张索引的测试表zz_table,其中对于两个字段建立四个索引:全升序、全降序、前降后升、前升后降,然后随便插入了一条数据,接着来看看SQL执行情况:
-- MySQL5.1版本中的测试
explain select*from zz_table orderby id1 asc, id2 desc;
+----+-------------+----------+------+-----------------------------+
| id | select_type |table|....|Extra|
+----+-------------+----------+------+-----------------------------+
|1| SIMPLE | zz_table |....|Using index;Using filesort |
+----+-------------+----------+------+-----------------------------+
-- MySQL8.0版本中的测试
explain select*from zz_table orderby id1 asc, id2 desc;
+----+-------------+----------+------------+-------+----------------------------------+
| id | select_type |table| partitions |.....|Extra|
+----+-------------+----------+------------+-------+----------------------------------+
|1| SIMPLE | zz_table |NULL|.....|Backward index scan;Using index |
+----+-------------+----------+------------+-------+----------------------------------+重点观察最后一个Extra字段,在MySQL8.0之前的版本中,虽然对id2建立了倒序索引,但实际做倒序查询时依旧会发生Using filesort排序动作,而MySQL8.0中则直接是Backward index scan反向索引扫描,并未触发排序动作。
3.5.4、函数索引
在MySQL8.0中真正的支持了函数索引,也就是基于函数去创建索引,如下:
alter table 表名 add index 索引名(函数(列名));
-- 比如:创建一个将字段值全部转为大写后的索引
alter table t1 add index fuc_upper(upper(c1));基于某个字段创建一个函数索引后,之后基于该字段使用函数作为查询条件时,依旧可以走索引,如下:
select * from t1 where upper(c1) = 'ABC';上述这条SQL语句,理论上这条语句由于在=前面使用了函数,显然会导致索引失效,但在MySQL8.0中可创建函数索引,可以支持条件查询时,在=号之前使用函数。
不过有一点需要牢记:使用什么函数创建的索引,也仅支持相应函数走索引,比如上面通过了
upper()函数创建了一个索引,因此upper(c1) = 'ABC'这种情况可以走索引,但使用其他函数时依旧会导致索引失效,如:lower(c1) = 'abc'。
3.6、CTE通用表表达式(Common Table Expression)
CTE通用表表达式究竟是用来干什么事情的呢?CTE是一个具备变量名的临时结果集,也就是可以将一条查询语句的结果保存到一个变量里面,后续在其他语句中允许直接通过变量名来使用该结果集,语法如下:
with CTE名称
as (查询语句/子查询语句)
select 语句;上述的语法是一个普通的CTE用法,同时还有另一种递归的CTE用法,先举个简单的例子来认识一下最基本的用法:
-- MySQL8.0版本之前的子查询语句
select * from t1 where xx in (select xx from t2 where yy = "zzz");
-- MySQL8.0中使用CTE表达式来代替
with cte_query as
(select xx from t2 where yy = "zzz")
select * from t1 join cte_query on t1.xx = cte_query.xx;观察上述例子,原本语句中需要使用in来对子查询的多个结果集做匹配,使用CTE后可以将子查询的结果集保存在cte_query变量中,后续的语句中可以将其当作成一张表,然后来做连接查询。
其实看到这里,
CTE表达式是不是有些类似于临时表的概念?但它会比临时表更轻,查询更快。
除开最基本的表达式外,还有一种名为递归CTE表达式的概念,它是一种递归算法的实现,可以反复执行一段SQL,比如当你要查询标签表中,某个顶级标签下所有的子标签时,它的下级可能也存在其它字标签.....,可能一个顶级标签下面有十八层子标签,这时通过传统的查询语句就无法很好实现,而使用递归的CTE表达式就很简单啦。
递归CTE表达式只需要使用with recursive关键字即可。
CTE表达式除开可以与select语句嵌套外,还可以与其它类型的语句嵌套,例如:with delete、with update、with recursive、with with、insert with等。
3.7、窗口函数(Window Function)
窗口函数可谓是MySQL8.0中最大的亮点之一,但在尝试去学习时会发现很难理解,先来看看窗口函数的定义。
窗口函数是一种分析型的OLAP函数,因此也被称之为分析函数,它可以理解成是数据的集合,类似于group by分组的功能,但之前的MySQL版本基于某个字段分组后,会将数据压缩到一行显示,如下:
select *from`zz_users`;
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
|1|熊猫|女|6666|2022-08-1415:22:01|
|2|竹子|男|1234|2022-09-1416:17:44|
|3|子竹|男|4321|2022-09-1607:42:21|
|4|猫熊|女|8888|2022-09-1723:48:29|
+---------+-----------+----------+----------+---------------------+
select user_id from zz_users groupby user_sex;
+-----------+
| user_id |
+-----------+
|1,4|
|2,3|
+-----------+而窗口函数则不会将数据压缩成一行,也就是表中数据原本是多少行,分组完成后依旧是多少行,窗口函数的语法如下:
[window 窗口函数名as(window_spec)[,窗口函数名AS(window_spec)]...]
窗口函数名(窗口名/表达式)
over(
[partition_defintion]
[order_definition]
[frame_definition]
)其实这个语法看起来不是特别能让人理解,所以结合具体的场景来举例,语法如下:
窗口函数 over([partitionby字段名orderby字段名asc|desc])
窗口函数over窗口名...window窗口名
as([partitionby字段名orderby字段名asc|desc])MySQL8.0中提供了哪些窗口函数呢?如下:
序号函数:
row_number():按序排列,相同的值序号会往后推,如88、88、89排序为1、2、3。rank():并列排序,相同的值序号会跳过,如88、88、89排序为1、1、3。dense_rank():并列排序,相同的值序号不会跳过,如88、88、89排序为1、1、2。
分布函数:
percent_rank():计算当前行数据的某个字段值占窗口内某个字段所有值的百分比。cume_dist(): 小于等于当前字段值的行数与整个分组内所有行数据的占比。
前后函数:
lag(expr,n):返回分组中的前n条符合expr条件的数据。lead(expr,n):返回分组中的后n条符合expr条件的数据。
首尾函数:
first_value(expr):返回分组中的第一条符合expr条件的数据。last_value(expr):返回分组中的最后一条符合expr条件的数据。
其它函数:
nth_value(expr,n):返回分组中的第n条符合expr条件的数据。ntile(n):将一个分组中的数据再分成n个小组,并记录每个小组编号。
需求如下:
按性别分组,并按照
ID值从大到小对各分组中的数据进行排序,最后输出。
这需求一听就知道一条SQL绝对搞不定,在之前版本中需要创建临时表来实现,借助临时表来拆成多步完成,而在MySQL8.0中则可以借助窗口函数轻松实现,如下:
select
-- 使用 row_number() 序号窗口函数
row_number()over(
-- 基于性别做分组,然后基于 ID 做倒序
partitionby user_sex orderby user_id desc
)as serial_num,
user_id, user_name, user_sex, password, register_time
from
zz_users;
+------------+---------+-----------+----------+----------+---------------------+
| serial_num | user_id | user_name | user_sex | password | register_time |
+------------+---------+-----------+----------+----------+---------------------+
|1|4|猫熊|女|8888|2022-09-1723:48:29|
|2|1|熊猫|女|6666|2022-08-1415:22:01|
|1|3|子竹|男|4321|2022-09-1607:42:21|
|2|2|竹子|男|1234|2022-09-1416:17:44|
+------------+---------+-----------+----------+----------+---------------------+上述这条SQL就是基于序号窗口函数的实现,其实发现会尤为简单,观察执行结果也会发现,使用窗口函数分组后,并不会将数据压缩到一行,而是将同一分组的数据在结果集中相邻显示。
3.8、MySQL8.0中的其他特性
在前面的内容中,就已经将MySQL8.0中较为重要的变更和特性做了详细阐述,但MySQL8.0整体的改变也比较大,因此这里再列出一些其它方面的特性,如下:
将默认的
UTF-8编码格式从latin替换成了utf8mb4,后者包含了所有emoji表情包字符。增强
NoSQL存储功能,优化了5.6版本引入的NoSQL技术,并完善了对JSON的支持性。InnoDB引擎再次增强,对自增、索引、加密、死锁、共享锁等方面做了大量改进与优化。支持定义原子
DDL语句,即当需要对库表结构发生变更时,变更操作可定义为原子性操作。支持正则检索,新增
REGEXP_LIKE()、EGEXP_INSTR()、REGEXP_REPLACE()、REGEXP_SUBSTR()等函数提供支持。优化临时表,临时表默认引擎从
Memory替换为TempTable引擎,资源开销少,性能更强。锁机制增强,除开前面聊到的锁特性变更外,新引入了一种备份锁,获取/释放锁语法如下:
获取锁:
LOCK INSTANCE FOR BACKUP、释放锁:UNLOCK INSTANCE
Bin-log日志增强,过期时间精确到秒,利用zstd算法增强了日志事务的压缩功能。安全性提高,认证加密插件更新、密码策略改进、新增角色功能、日志文件支持加密等。
引入资源组的概念,支持按业务优先级来控制工作线程的
CPU资源抢占几率。


























![[极客大挑战 2019]FinalSQL](https://i-blog.csdnimg.cn/direct/d694996aa8174708ae971035a20cc5d8.png)