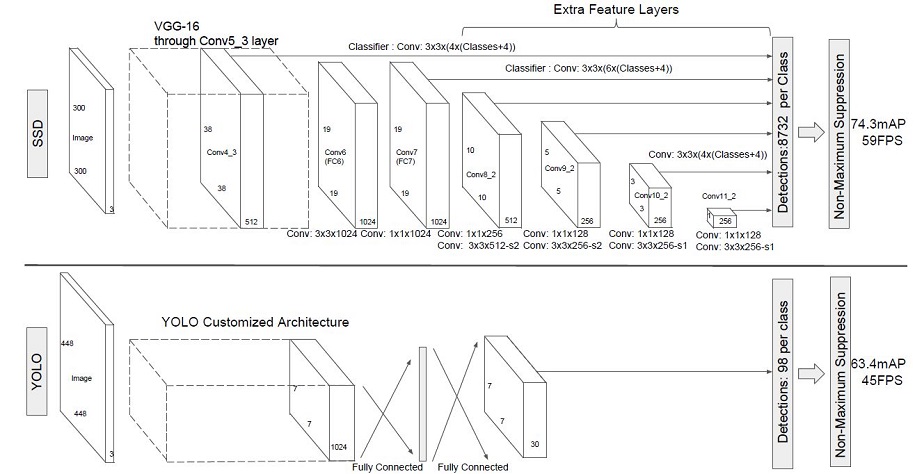
题意:为什么LlamaCPP在推理过程中会冻结
问题背景:
I'm using the following code to try and recieve a response from LlamaCPP, used through the LlamaIndex library. My model is stored locally in a gguf file. I'm trying to do inference on the CPU as my VRAM is limited. My program prints out the initialization code (also pasted below), but then hangs indefinitely and produces no response.
import json
from llama_index.llms.llama_cpp import LlamaCPP
MODEL_URL = "https://huggingface.co/TheBloke/Llama-2-13B-chat-GGUF/resolve/main/llama-2-13b-chat.Q4_0.gguf"
MODEL_PATH = None
with open("./paths.json", "r") as f:
paths = json.load(f)
if "llama-2-13b-chat" in paths:
MODEL_URL = None
MODEL_PATH = paths["llama-2-13b-chat"]
llm = LlamaCPP(
model_url=MODEL_URL,
model_path=MODEL_PATH,
temperature=0.1,
max_new_tokens=256,
context_window=3900,
model_kwargs={"n_gpu_layers": 0}, # Use CPU for inference
verbose=True,
)
response = llm.complete("Hello, how are you?")
print(str(response))Output: Initializes, then hangs indefinitely. My expected output is that it prints out the verbose initialization, then the LLMs response, then terminates.
llama_model_loader: loaded meta data with 19 key-value pairs and 363 tensors from ../models/llama-2-13b-chat.Q4_0.gguf (version GGUF V2)
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = LLaMA v2
llama_model_loader: - kv 2: llama.context_length u32 = 4096
llama_model_loader: - kv 3: llama.embedding_length u32 = 5120
llama_model_loader: - kv 4: llama.block_count u32 = 40
llama_model_loader: - kv 5: llama.feed_forward_length u32 = 13824
llama_model_loader: - kv 6: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 7: llama.attention.head_count u32 = 40
llama_model_loader: - kv 8: llama.attention.head_count_kv u32 = 40
llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 10: general.file_type u32 = 2
llama_model_loader: - kv 11: tokenizer.ggml.model str = llama
llama_model_loader: - kv 12: tokenizer.ggml.tokens arr[str,32000] = ["<unk>", "<s>", "</s>", "<0x00>", "<...
llama_model_loader: - kv 13: tokenizer.ggml.scores arr[f32,32000] = [0.000000, 0.000000, 0.000000, 0.0000...
llama_model_loader: - kv 14: tokenizer.ggml.token_type arr[i32,32000] = [2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, ...
llama_model_loader: - kv 15: tokenizer.ggml.bos_token_id u32 = 1
llama_model_loader: - kv 16: tokenizer.ggml.eos_token_id u32 = 2
llama_model_loader: - kv 17: tokenizer.ggml.unknown_token_id u32 = 0
llama_model_loader: - kv 18: general.quantization_version u32 = 2
llama_model_loader: - type f32: 81 tensors
llama_model_loader: - type q4_0: 281 tensors
llama_model_loader: - type q6_K: 1 tensors
llm_load_vocab: special tokens definition check successful ( 259/32000 ).
llm_load_print_meta: format = GGUF V2
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 32000
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 4096
llm_load_print_meta: n_embd = 5120
llm_load_print_meta: n_head = 40
llm_load_print_meta: n_head_kv = 40My RAM utilization ends up around 9.5GB/16, and my CPU utilization is around 50%. Any insight into why this would be occuring would be greatly appreciated.
问题解决:
try using streaming output. Model is generating the response, but without gpu it is very slow. Overall 13B models are quite large and it's ok if they take more than 10gb of ram.
response_iter = llm.stream_complete("Can you write me a poem about fast cars?")
for response in response_iter:
print(response.delta, end="", flush=True)Also consider using smaller model to speed up outputs:
MODEL_URL = "https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF/resolve/main/llama-2-7b-chat.Q4_K_M.gguf"