知识库问答
一、概念
大语言模型(LLM)
LLM是一类基础模型,经过大量数据训练,使其能够理解和生成自然语言和其他类型的内容,以执行各种任务。如,GPT,qwen,文心一言…知识库
知识库是一个存储和管理知识的系统,它可以帮助我们更有效地检索、组织和利用知识。知识库的构建是一个复杂的过程,涉及到知识的提取、表示、存储和检索等多个方面。知识库问答
通俗来说:提问者提出问题,LLM将问题通过检索、匹配知识库中存储的知识,进行总结,来解答问题。
二、为什么要实现知识库问答
- 传统的LLM问答
利用互联网的公共信息和大模型本身的能力对问题进行解答。
LLMs的问题:
- 问题1:LLMs并不了解你的数据,且无法获取与此相关的最新数据,它们是事先使用来自互联网的公共信息训练好的,因此并不是专有数据库的专家也不会针对该数据库进行更新。
- 问题2:上下文窗口-每个LLM都有一个tokens的最大限制,用于限制用户每次提交的tokens数据(超长上下文的大模型例外),这会导致丢失上下文窗口之外的上下文,进而影响准确性、产生检索问题和幻觉等。幻觉问题:大模型的底层原理是基于概率,在没有答案的情况下经常会胡说八道,提供虚假信息
- 问题3:中间遗失-即使LLMs可以一次性接收所有的数据,但它存在根据信息在文档中的位置来检索信息的问题。研究表明如果相关信息位于文档中间(而非开头或结尾时)时就会导致严重的性能降级。
- 问题4:时效性问题-规模越大(参数越多、tokens 越多),大模型训练的成本越高。类似 ChatGPT3.5,起初训练数据是截止到 2021 年的,对于之后的事情就不知道了。
- 问题5:数据安全-OpenAI 已经遭到过几次隐私数据的投诉,而对于企业来说,如果把自己的经营数据、合同文件等机密文件和数据上传到互联网上的大模型,非常不安全。既要保证安全,又要借助 AI 能力,那么最好的方式就是把数据全部放在本地,企业数据的业务计算全部在本地完成。而在线的大模型仅仅完成一个归纳的功能,甚至,LLM 都可以完全本地化部署。
- 基于LLM和RAG技术的知识库问答
为了解决传统的LLM问答的问题,需要一些方式来改变模型的行为来更好的贴近我们的期望,一般来说有三种方式提示工程、微调和RAG。- 提示工程:通过编写提示词来引导大模型思考回答问题。一般包括:指示(Instructions),上下文(背景信息,Context),例子(Examples),输入(Input),输出(Output)。仍然局限在模型在初始训练期间学到的内容上。
- 微调:指找来一个语言模型并让它学习一些新的或特殊的东西。在微调的情况下,模型需要大量新信息和时间来正确学习各种内容,带来的后果就是需要大量的资源,算力和时间。
- RAG:检索增强生成(RAG)技术,该技术将常见的语言模型与知识库之类的东西混合在一起。当模型需要回答问题时,它首先从知识库中查找并收集相关信息,然后根据该信息回答问题。模型会快速检查信息库,以确保它能给你最好的答案。
通过这种方式能够有效降低大模型问题带来的影响,比如幻觉,数据安全,时效性等问题。
三、知识库问答的实现
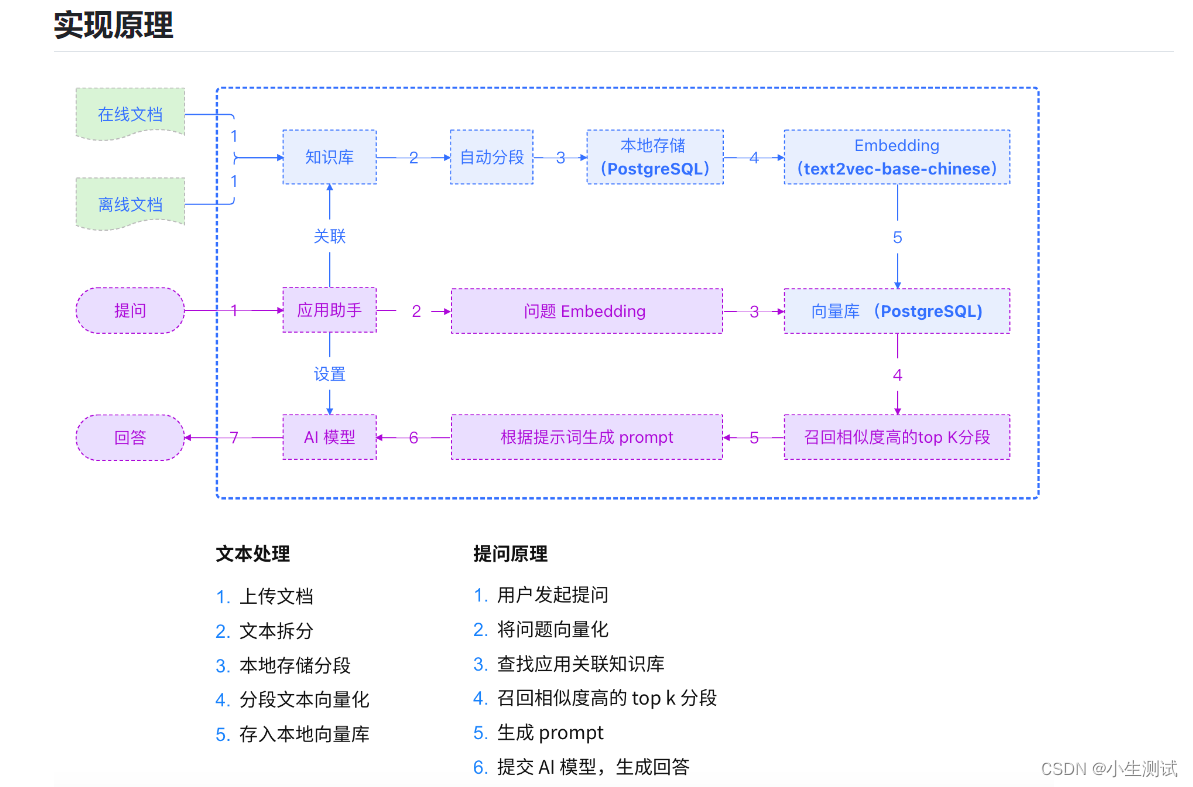
过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。


四、知识库的问答缺陷
1. RAG本身会带来的缺陷
(1)关键文档可能不会出现在系统检索组件返回的最上面的结果中。如果正确的答案被忽略,那么会导致系统无法提供准确的响应。
(2)系统从提供的上下文中提取正确的答案,但是在信息过载的情况下会遗漏关键细节,这会影响回复的质量。
(3)部分结果没有错;但是它们并没有提供所有的细节,尽管这些信息在上下文中是存在的和可访问的。
2 其他问题
(1)用户的问题不够明确,导致查询不到正确结果
(2)机器性能的影响
(3)难以将复杂文档正确识别切分并向量化(例如含有复杂表格的PDF)
(4)大模型无法识别专业性和一些带有特别含义的名词
…
数据库问答
一、什么是数据库问答
与知识库问答类似,但数据库问答不在是去切分文本匹配相似度,而是通过大模型以及text2sql的方式使用sql语句查询数据库中的数据,进行回答。
二、数据库问答的实现
- 用户提出问题
- 根据用户问题使用大模型推理出生成sql所需的数据库和数据表
- 根据推理出的数据库和数据表将表的结构信息查询出来,并组装到提示词里,在利用大模型和提示词推理生成sql语句。
- 查询生成的sql语句
- 将查询的结果再次利用大模型和提示词进行总结,得出答案
三、数据库问答的缺陷
- 受用户问题的影响,大模型不能保证推理出完全正确的数据表。对策:尽力将表格的描述信息写详细,可以让提问者自行选择表格。
- 通常大模型对Text2SQL的表现不佳,生成的sql语句不一定能够执行(如,经常将字段备注当成字段名,没有使用提示词提供的表格信息而是胡编乱造)。对策:优化提示词去限制大模型,引入few_shot_examples(少量样本示例)。
少量样本示例:为LLM提供少量Q&A示例来帮助它理解如何构建请求,通过这种方式可以提升10~15%的准确性。根据示例的质量和使用的模型,添加更多的示例可以获得更高的准确性。在有大量示例的情况下,可以将其保存在向量存储中,然后通过对输入查询进行语义搜索,动态选择其中的一部分。
- 回答速度慢。例如我们的实现方式:推理数据表+生成sql+匹配few_shot+生成echarts+总结,一共使用了五次大模型。

































![[iOS]浅析isa指针](https://i-blog.csdnimg.cn/direct/2ff996c72d304a0aa05c7108fa0f0b40.png)
![BUUCTF逆向wp [HDCTF2019]Maze](https://i-blog.csdnimg.cn/direct/9734bd1b12034828a530d8f8f2ee0745.png)



