目录
在数据科学的浩瀚海洋中,聚类算法是探索未知数据模式的罗盘。近期,我深入研究了一篇发表在《软件学报》上的论文——《聚类算法研究》,由孙吉贵、刘杰和赵连宇三位学者合著。这篇论文不仅系统地回顾了聚类算法的研究进展,还对算法的发展趋势和应用前景进行了深入探讨。以下是我对这篇论文的深度解析,结合互联网上的相关信息,以期为读者提供更为专业的视角。
聚类算法的核心地位
聚类算法在数据挖掘中占据核心地位,它们帮助我们从大量无标签的数据中发现潜在的模式和结构。这些算法广泛应用于图像分析、生物信息学、社交网络分析等多个领域。聚类算法的关键在于它们能够在没有明确指导的情况下,自动识别数据中的群组。
研究现状与算法概览
论文首先对聚类算法的研究现状进行了全面的梳理,包括算法的设计思想、关键技术以及各自的优缺点。作者详细分析了以下几类主要的聚类算法:
- 层次聚类算法:通过构建一个多层次的聚类树来进行数据的聚合或分裂。
- 划分聚类算法:如经典的K-means算法,通过迭代优化来最小化聚类误差。
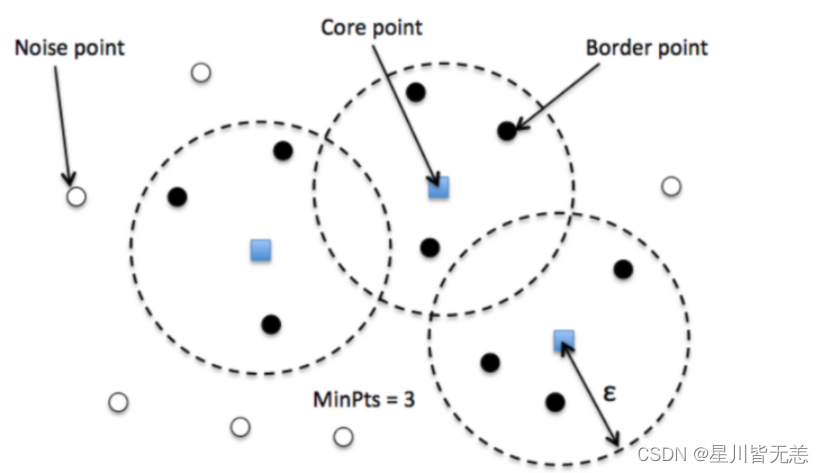
- 基于密度的聚类算法:如DBSCAN,根据数据点的密度分布来识别聚类,对噪声具有较好的鲁棒性。
- 基于网格的聚类算法:通过将数据空间划分为有限的网格单元,实现高效的聚类。
模拟实验与性能评估
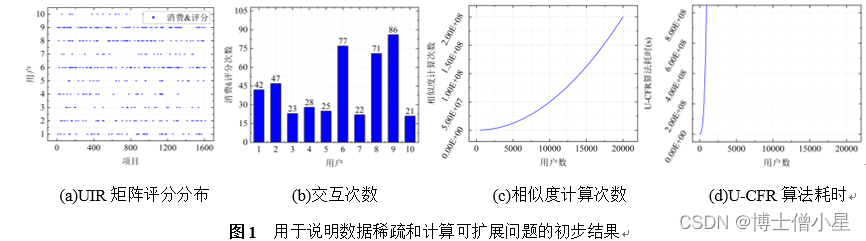
作者通过模拟实验对选定的聚类算法进行了性能评估。实验使用了多个公开的数据集,并从正确率和运行效率两个维度对算法进行了综合评价。这些实验不仅验证了不同算法的有效性,也揭示了算法选择对聚类结果的重要影响。
聚类算法的新进展与挑战
论文进一步探讨了聚类算法的新进展,包括:
- Binary-Positive方法:一种新颖的层次聚合算法,通过二进制形式存储和处理数据,提高了聚类的准确率和鲁棒性。
- RCOSD算法:针对连续数据的粗聚类算法,有效挖掘数据并描述类簇特性,适用于Web数据挖掘。
- K-modes算法:一种针对分类属性数据的聚类算法,能够提供类特性的描述,适用于大规模数据集。
尽管取得了显著的进展,聚类算法仍面临着诸如参数选择、全局最优解的寻找以及对大规模数据集的处理等挑战。
结论与未来趋势
论文最后总结了聚类算法的研究成果,并对未来的研究方向提出了展望。作者强调了开展聚类算法评价标准和数据集特性描述方法研究的重要性,并建议对不同数据集进行聚类算法预测分类数能力的研究。
个人思考与互联网视角
在阅读这篇论文的过程中,我深感聚类算法的复杂性和多样性。互联网上的丰富资源,如Kaggle竞赛、GitHub上的开源项目以及学术论文库,为聚类算法的研究提供了大量的实验平台和案例分析。通过这些平台,我们可以观察到聚类算法在实际应用中的性能表现和局限性,进而推动算法的改进和创新。
结语
《聚类算法研究》这篇论文为我们提供了宝贵的知识和见解,帮助我们更好地理解和应用聚类算法。在数据科学领域,随着技术的不断进步,聚类算法将继续发展,以应对日益增长的数据量和复杂性。如果你对数据挖掘或机器学习感兴趣,我强烈推荐你阅读这篇论文,并探索互联网上的相关内容。
本文旨在为专业读者提供对《聚类算法研究》论文的深度解析,并结合互联网上的相关信息,以期为读者带来更为全面和深入的理解。如果你有任何问题或想要进一步讨论,欢迎在评论区留言交流。


![[机器学习系列]<span style='color:red;'>深入</span><span style='color:red;'>解析</span>K-Means<span style='color:red;'>聚</span><span style='color:red;'>类</span><span style='color:red;'>算法</span>:理论、实践与优化](https://img-blog.csdnimg.cn/direct/376e457bc92a4f21a5c8bf128b7a5f8e.png)