k8s集群 安装配置 Prometheus+grafana+alertmanager
k8s环境如下:
k8s集群: k8s的控制节点
ip:192.168.40.110
主机名:k8smaster1
配置:4vCPU/4Gi内存
k8s的工作节点:
ip:192.168.40.111
主机名:k8snode1
配置:4vCPU/4Gi内存
k8s版本1.25
机器规划:
我的实验环境使用的k8s集群是一个master节点和一个node节点
master节点的机器ip是192.168.40.110,主机名是k8smaster1
node节点的机器ip是192.168.40.111,主机名是k8snode1
node-exporter组件安装和配置
node-exporter介绍
node-exporter可以采集机器(物理机、虚拟机、云主机等)的监控指标数据,能够采集到的指标包括CPU, 内存,磁盘,网络,文件数等信息。
安装node-exporter
node-exporter.tar.gz镜像压缩包上传到k8s的各个节点,手动解压:
链接:https://pan.baidu.com/s/1EBsJPfWDO3c1qMeaESe5Ig?pwd=7bbw
提取码:7bbw
kubectl create ns monitor-sa
ctr -n=k8s.io images import node-exporter.tar.gz
docker load -i node-exporter.tar.gz
node-export.yaml
链接:https://pan.baidu.com/s/1wqaDok9afK58AGTR-QlvGg?pwd=fjfr
提取码:fjfr
cat node-export.yaml
kind: DaemonSet #可以保证k8s集群的每个节点都运行完全一样的pod
spec:
hostPID: true
hostIPC: true
hostNetwork: true
# hostNetwork、hostIPC、hostPID都为True时,表示这个Pod里的所有容器
#会直接使用宿主机的网络,直接与宿主机进行IPC(进程间通信)通信,可以看到宿主机里正在运行的所有进程。
#加入了hostNetwork:true会直接将我们的宿主机的9100端口映射出来
#从而不需要创建service 在我们的宿主机上就会有一个9100的端口
cpu: 0.15 #这个容器运行至少需要0.15核cpu
securityContext:
privileged: true #开启特权模式
args:
- --path.procfs #配置挂载宿主机(node节点)的路径
- /host/proc
- --path.sysfs #配置挂载宿主机(node节点)的路径
- '"^/(sys|proc|dev|host|etc)($|/)"'#通过正则表达式忽略某些文件系统挂载点的信息收集
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
#将主机/dev、/proc、/sys这些目录挂在到容器中,这是因为我们采集的很多节点数据都是通过这些文件来获取系统信息的。
通过kubectl apply更新node-exporter.yaml文件
kubectl apply -f node-export.yaml
查看node-exporter是否部署成功
kubectl get pods -n monitor-sa
显示如下,看到pod的状态都是running,说明部署成功

通过node-exporter采集数据
显示192.168.40.180主机cpu的使用情况
curl http://虚拟机ip:9100/metrics
curl http://192.168.40.110:9100/metrics | grep node_cpu_seconds
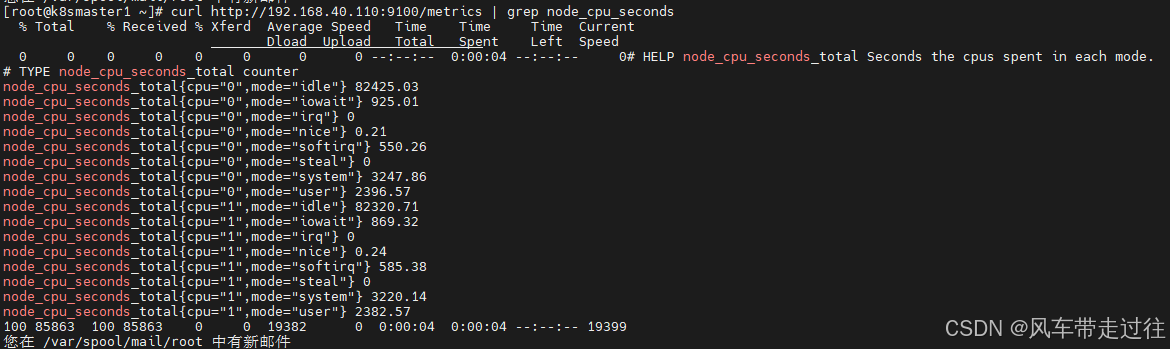
- #HELP:解释当前指标的含义,上面表示在每种模式下node节点的cpu花费的时间,以s为单位
- #TYPE:说明当前指标的数据类型,上面是counter类型
node_cpu_seconds_total{cpu="0",mode="idle"} :
- cpu0上idle进程占用CPU的总时间,CPU占用时间是一个只增不减的度量指标,从类型中也可以看出node_cpu的数据类型是counter(计数器)
- counter计数器:只是采集递增的指标
显示192.168.40.180主机负载使用情况
curl http://192.168.40.180:9100/metrics | grep node_load
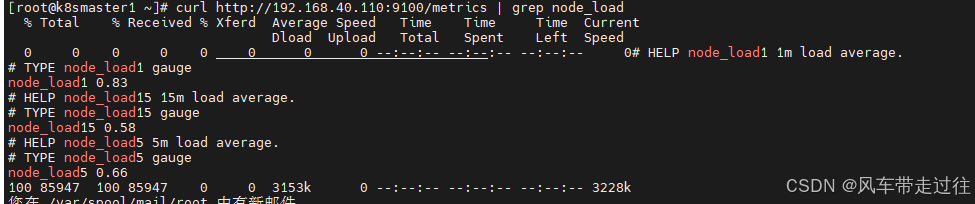
- node_load1该指标反映了当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此node_load1反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指标类型为gauge(标准尺寸)
- gauge标准尺寸:统计的指标可增加可减少
Prometheus server安装和配置
创建sa账号,对sa做rbac授权
创建一个sa账号monitor
kubectl create serviceaccount monitor -n monitor-sa
把sa账号monitor通过clusterrolebing绑定到clusterrole上
kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
注意:行上面授权可能回报错,那就需要下面的授权命令
kubectl create clusterrolebinding monitor-clusterrolebinding-1 -n monitor-sa --clusterrole=cluster-admin --user=system:serviceaccount:monitor:monitor-sa
创建prometheus数据存储目录
在k8s集群的xianchaonode1节点上创建数据存储目录
#在节点创建
mkdir /data
chmod 777 /data/
安装Prometheus server服务
创建一个configmap存储卷,用来存放prometheus配置信息
通过kubectl apply更新configmap
prometheus-cfg.yaml文件上传到k8s控制节点k8smaster1上:
链接:https://pan.baidu.com/s/1lQGQLp7ikDHSanOusSMTWQ?pwd=w6w4
提取码:w6w4
kubectl apply -f prometheus-cfg.yaml
cat prometheus-cfg.yaml
scrape_interval: 15s #采集目标主机监控据的时间间隔
scrape_timeout: 10s # 数据采集超时时间,默认10s
evaluation_interval: 1m #触发告警检测的时间,默认是1m
#我们写了超过80%的告警,结果收到多条告警,但是真实超过80%的只有一个时间点。
#这是另外一个参数影响的
evaluation_interval #这个是触发告警检测的时间,默认为1m。假如我们的指标是5m被拉取一次。
#检测根据evaluation_interval 1m一次,所以在值被更新前,我们一直用的旧值来进行多次判断,造成了1m一次,同一个指标被告警了4次。
scrape_configs:
#scrape_configs:配置数据源,称为target,每个target用job_name命名。又分为静态配置和服务发现
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
#使用的是k8s的服务发现
- role: node
# 使用node角色,它使用默认的kubelet提供的http端口来发现集群中每个node节点。
relabel_configs:
#重新标记
- source_labels: [__address__] #配置的原始标签,匹配地址
regex: '(.*):10250' #匹配带有10250端口的url
replacement: '${1}:9100' #把匹配到的ip:10250的ip保留
target_label: __address__ #新生成的url是${1}获取到的ip:9100
action: replace
- action: labelmap
#匹配到下面正则表达式的标签会被保留,如果不做regex正则的话,默认只是会显示instance标签
regex: __meta_kubernetes_node_label_(.+)
通过deployment部署prometheus
镜像prometheus-2-2-1.tar.gz上传到k8s的工作节点k8snode1上,手动解压
链接:https://pan.baidu.com/s/1arlhVb0q-9tWe9KHZG1Htg?pwd=j6m1
提取码:j6m1
ctr -n=k8s.io images import prometheus-2-2-1.tar.gz
#1.24前用 docker load -i prometheus-2-2-1.tar.gz
prometheus-deploy.yaml 上传至k8smaster1
链接:https://pan.baidu.com/s/11QOcz5udgbMpxGoYD6pP9w?pwd=rkp6
提取码:rkp6
kubectl apply -f prometheus-deploy.yaml
cat prometheus-deploy.yaml
- --storage.tsdb.path=/prometheus #旧数据存储目录
- --storage.tsdb.retention=720h #何时删除旧数据,默认为15天。
- --web.enable-lifecycle #开启热加载
注意:在上面的prometheus-deploy.yaml文件有个nodeName字段,这个就是用来指定创建的这个prometheus的pod调度到哪个节点上,我们这里让nodeName=k8snode1,也即是让pod调度到k8snode1节点上,因为k8snode1节点我们创建了数据目录/data,所以大家记住:你在k8s集群的哪个节点创建/data,就让pod调度到哪个节点,nodeName根据你们自己环境主机去修改即可。
查看prometheus是否部署成功
kubectl get pods -n monitor-sa

给prometheus pod创建一个service
prometheus-svc.yaml文件上传到k8s的控制节点k8smaster1上:
链接:https://pan.baidu.com/s/1j9Nz7trUT6rgZ9kS-ANb7Q?pwd=hgql
提取码:hgql
kubectl apply -f prometheus-svc.yaml
查看service在物理机映射的端口
kubectl get svc -n monitor-sa

通过上面可以看到service在宿主机上映射的端口是31090,这样我们访问k8s集群的master1节点的ip:31090,就可以访问到prometheus的web ui界面了
#访问prometheus web ui界面
火狐浏览器输入如下地址:
http://192.168.40.110:31090/graph
可看到如下页面:
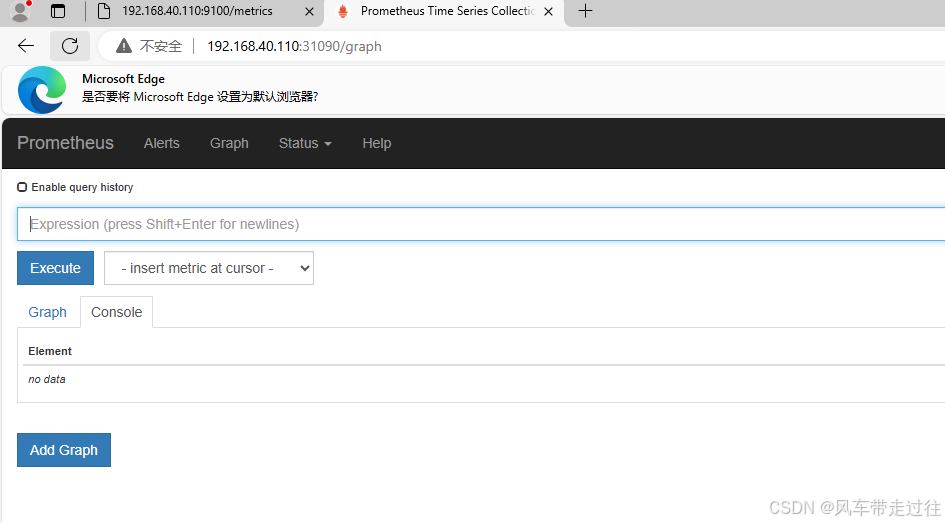
点击页面的Status->Targets,可看到如下,说明我们配置的服务发现可以正常采集数据

Prometheus热加载
为了每次修改配置文件可以热加载prometheus,也就是不停止prometheus,就可以使配置生效,想要使配置生效可用如下热加载命令:
kubectl get pods -n monitor-sa -o wide -l app=prometheus

10.244.249.2是prometheus的pod的ip地址,如何查看prometheus的pod ip
想要使配置生效可用如下命令热加载:
curl -X POST http://10.244.249.2:9090/-/reload
- 热加载速度比较慢,可以暴力重启prometheus,如修改上面的prometheus-cfg.yaml文件之后,可执行如下强制删除:
kubectl delete -f prometheus-cfg.yaml
kubectl delete -f prometheus-deploy.yaml
- 然后再通过apply更新:
kubectl apply -f prometheus-cfg.yaml
kubectl apply -f prometheus-deploy.yaml
注意:线上最好热加载,暴力删除可能造成监控数据的丢失
可视化UI界面Grafana的安装和配置
安装Grafana
镜像heapster-grafana-amd64_v5_0_4.tar.gz上传到k8s的工作节点k8snode1上,手动解压:
链接:https://pan.baidu.com/s/1CMP6Ju-Zi-4dmJy2eSVtew?pwd=fkls
提取码:fkls
ctr -n=k8s.io images import heapster-grafana-amd64_v5_0_4.tar.gz
grafana.yaml文件上传到k8s的控制节点:
kubectl apply -f grafana.yaml
查看grafana是否创建成功:
kubectl get pods -n kube-system -l task=monitoring

Grafana界面接入Prometheus数据源
查看grafana前端的service
kubectl get svc -n kube-system | grep grafana

登陆grafana,在浏览器访问
192.168.40.110:30551
配置grafana界面:
选择Create your first data source
Name: Prometheus
Type: Prometheus
HTTP 处的URL写 如下:
http://prometheus.monitor-sa.svc:9090
配置好的整体页面如下:

点击左下角Save & Test,出现如下Data source is working,说明prometheus数据源成功的被grafana接入了
导入的监控模板,可在如下链接搜索
https://grafana.com/dashboards?dataSource=prometheus&search=kubernetes
上面Save & Test测试没问题之后,就可以返回Grafana主页面
点击左侧+号下面的Import,出现如下界面

可直接导入node_exporter.json监控模板,这个可以把node节点指标显示出来
node_exporter.json
链接:https://pan.baidu.com/s/1lK43XIWKuMYiQoWBAtJJ-Q?pwd=j01k
提取码:j01k


docker_rev1.json,显示容器资源指标的
链接:https://pan.baidu.com/s/1F_9ApBvKCV3lkHvxPLP-OQ?pwd=wkph
提取码:wkph
导入docker_rev1.json监控模板,步骤和上面导入node_exporter.json步骤一样,导入之后显示如下:

如果Grafana导入Prometheusz之后,发现仪表盘没有数据,如何排查?
打开grafana界面,找到仪表盘对应无数据的图标

Edit之后出现如下:
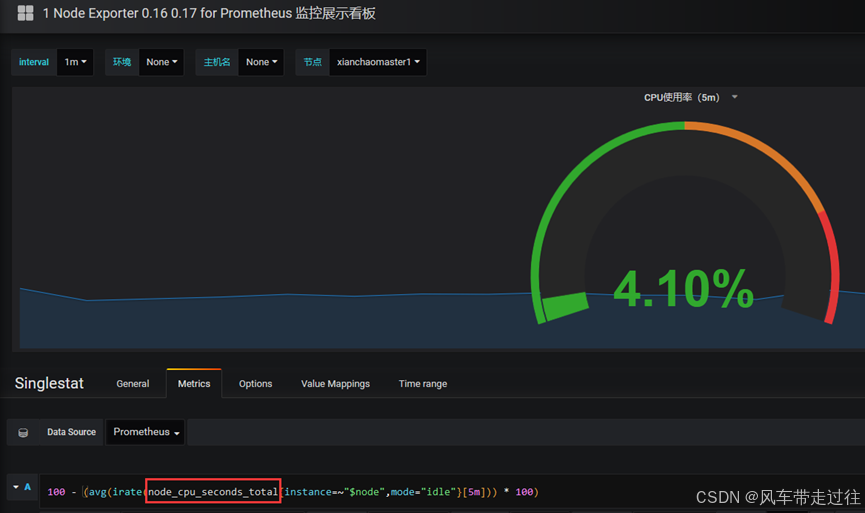
node_cpu_seconds_total 就是grafana上采集的cpu的时间,需要到prometheus ui界面看看采集的指标是否是node_cpu_seconds_total

如果在prometheus ui界面输入node_cpu_seconds_total没有数据,那就看看是不是prometheus采集的数据是node_cpu_seconds_totals,怎么看呢?
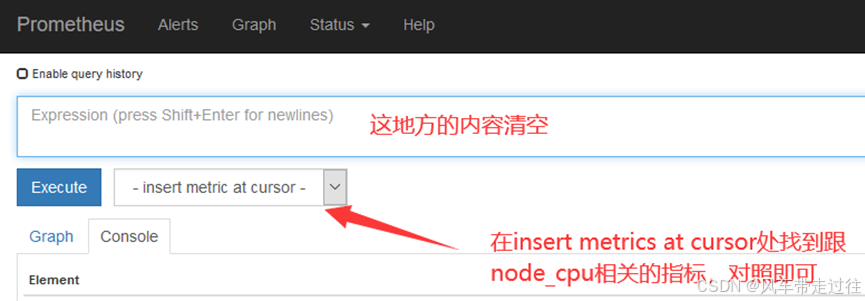
安装kube-state-metrics组件
kube-state-metrics是什么?
- kube-state-metrics通过监听API Server生成有关资源对象的状态指标,比如Node、Pod,需要注意的是kube-state-metrics只是简单的提供一个metrics数据,并不会存储这些指标数据,所以我们可以使用Prometheus来抓取这些数据然后存储,主要关注的是业务相关的一些元数据,
- 比如Pod副本状态等;调度了多少个replicas?现在可用的有几个?多少个Pod是running/stopped/terminated状态?Pod重启了多少次?我有多少job在运行中。
安装kube-state-metrics组件
创建sa,并对sa授权
kube-state-metrics-rbac.yaml文件上传到k8s的控制节点:
链接:https://pan.baidu.com/s/1fNAovsSfabcQMTpX4AknnQ?pwd=m6r0
提取码:m6r0
kubectl apply -f kube-state-metrics-rbac.yaml
安装kube-state-metrics组件
kube-state-metrics_1_9_0.tar.gz组件上传到k8s各个工作节点,手动解压:
链接:https://pan.baidu.com/s/1UufIAWnnQgP1vYSTvushSw?pwd=uunh
提取码:uunh
ctr -n=k8s.io images import kube-state-metrics_1_9_0.tar.gz
kube-state-metrics-deploy.yaml上传到k8smaster1节点
链接:https://pan.baidu.com/s/1GnMeja2VQUwHXj9MPsCHqQ?pwd=n0o9
提取码:n0o9
kubectl apply -f kube-state-metrics-deploy.yaml
查看kube-state-metrics是否部署成功
kubectl get pods -n kube-system -l app=kube-state-metrics

创建service
kube-state-metrics-svc.yaml文件上传到k8s的k8smaster1节点:
链接:https://pan.baidu.com/s/1DjZuLFDcH9mjRXY6CHJNfw?pwd=uo52
提取码:uo52
kubectl apply -f kube-state-metrics-svc.yaml
查看service是否创建成功
kubectl get svc -n kube-system | grep kube-state-metrics

在grafana web界面导入Kubernetes Cluster (Prometheus)-1577674936972.json和Kubernetes cluster monitoring (via Prometheus) (k8s 1.16)-1577691996738.json
导入Kubernetes Cluster (Prometheus)-1577674936972.json文件
链接:https://pan.baidu.com/s/1SpGM2hb0uuEsyJaYnhE_Rw?pwd=u1dz
提取码:u1dz

在grafana web界面导入Kubernetes cluster monitoring (via Prometheus) (k8s 1.16)-1577691996738.json
链接:https://pan.baidu.com/s/1v-zwCmwqC3iRix1M5s_GnA?pwd=2jhl
提取码:2jhl