OCR 模型
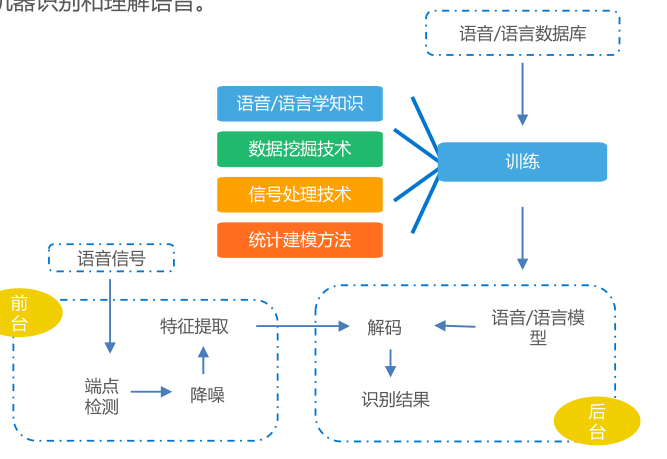
文字识别(Optical Character Recognition,OCR)模型是一种用来从图像中提取文本的技术。OCR模型在计算机视觉和自然语言处理中的应用非常广泛,例如将扫描的文档转换为可编辑的文本文件,自动读取车牌号码,处理手写文本等。
目前,常用的OCR模型和技术包括:
- Tesseract OCR:
- 开源OCR引擎,由Google维护。
- 支持多种语言和字体。
- 可通过训练数据来增强特定领域的识别能力。
- 使用方便,广泛应用于各种项目。
- EasyOCR:
- 开源的OCR库,基于深度学习,支持超过80种语言。
- 由PyTorch实现,容易集成到Python项目中。
- 相比Tesseract,EasyOCR在处理复杂背景和手写体方面有较好的表现。
- Google Cloud Vision OCR:
- 商业OCR服务,提供高精度的文本识别能力。
- 支持大规模并发处理,适用于企业级应用。
- 提供丰富的API接口,方便与其他Google云服务集成。
- Microsoft Azure Computer Vision OCR:
- 另一种商业OCR服务,提供强大的文本识别功能。
- 支持手写和印刷文本的识别。
- 集成方便,可与Azure的其他服务无缝连接。
- Amazon Textract:
- Amazon Web Services (AWS) 提供的OCR服务,特别擅长于从文档中提取结构化数据。
- 除了识别文本,还能识别表格和表单中的数据。
- PaddleOCR:
- 由百度PaddlePaddle团队开发的开源OCR工具。
- 支持中英文及多种其他语言的识别,具备较高的准确性。
- 提供轻量级模型,适合在移动设备上运行。
OCR 模型的基本原理
OCR模型的工作流程通常包括以下几个步骤:
- 图像预处理:
- 去噪声、二值化、旋转校正等操作,以提高图像的质量和文本的可读性。
- 文本检测:
- 从图像中检测出包含文本的区域。这一步通常使用卷积神经网络(CNN)来实现。
- 文本识别:
- 将检测到的文本区域中的图像转换为可编辑的文本。可以使用递归神经网络(RNN)、长短时记忆网络(LSTM)等技术。
- 后处理:
- 拼写检查、格式修正等操作,以提高最终输出文本的准确性。
实际应用
根据具体的应用场景和需求,可以选择适合的OCR模型。例如:
- 对于需要处理大量文档的企业,可以选择Google Cloud Vision OCR或Microsoft Azure Computer Vision OCR等商业服务。
- 对于个人或小型项目,Tesseract OCR或EasyOCR是不错的选择,前者稳定成熟,后者在深度学习方面有较好表现。
- 对于需要在移动设备上运行的应用,PaddleOCR的轻量级模型是一个好的选择。
在Python中使用OCR技术,可以通过一些开源库实现,如Tesseract和EasyOCR。下面将详细介绍如何使用这两个库来进行OCR操作。
使用Tesseract进行OCR
Tesseract是一个广泛使用的开源OCR引擎。它支持多种语言,并且可以通过训练数据来增强特定领域的识别能力。
安装Tesseract
首先,需要安装Tesseract引擎和Python绑定库pytesseract。
安装Tesseract引擎:
Windows:可以从Tesseract官方GitHub页面下载Windows安装包。
macOS:使用Homebrew安装:
brew install tesseractLinux:使用包管理器安装(如Ubuntu):
sudo apt-get install tesseract-ocr
安装Python绑定库
pytesseract:pip install pytesseract
使用Tesseract进行OCR
下面是一个简单的示例代码,用于从图像中提取文本:
import pytesseract
from PIL import Image
# 确保Tesseract引擎的路径正确
pytesseract.pytesseract.tesseract_cmd = r'路径到你的tesseract可执行文件' # 例如:C:\Program Files\Tesseract-OCR\tesseract.exe
# 打开图像文件
image = Image.open('path_to_your_image_file.jpg')
# 使用Tesseract进行OCR
text = pytesseract.image_to_string(image)
# 输出识别的文本
print(text)
使用EasyOCR进行OCR
EasyOCR是一个基于PyTorch的OCR库,支持超过80种语言,尤其擅长处理复杂背景和手写体。
安装EasyOCR
使用pip安装EasyOCR:
pip install easyocr
使用EasyOCR进行OCR
下面是一个简单的示例代码,用于从图像中提取文本:
import easyocr
# 创建一个EasyOCR的Reader对象,指定需要识别的语言
reader = easyocr.Reader(['en'])
# 读取图像并进行OCR
result = reader.readtext('path_to_your_image_file.jpg')
# 输出识别的文本
for (bbox, text, prob) in result:
print(f'Text: {text}, Probability: {prob}')
处理手写文本
如果需要处理手写文本,EasyOCR在这方面表现较好。具体的代码与上面的示例类似,只需将输入的图像换为包含手写文本的图像即可。
图像预处理
在进行OCR之前,适当的图像预处理可以显著提高识别的准确性。常见的预处理操作包括灰度化、二值化、去噪声、旋转校正等。下面是一个示例代码,展示如何使用OpenCV进行图像预处理:
import cv2
import numpy as np
# 读取图像
image = cv2.imread('path_to_your_image_file.jpg')
# 转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 128, 255, cv2.THRESH_BINARY_INV)
# 去噪声
denoised = cv2.fastNlMeansDenoising(binary, h=30)
# 显示预处理后的图像
cv2.imshow('Processed Image', denoised)
cv2.waitKey(0)
cv2.destroyAllWindows()
结合Tesseract或EasyOCR进行OCR:
import pytesseract
from PIL import Image
import cv2
# 图像预处理
image = cv2.imread('path_to_your_image_file.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(gray, 128, 255, cv2.THRESH_BINARY_INV)
denoised = cv2.fastNlMeansDenoising(binary, h=30)
# 将OpenCV图像转换为PIL图像
pil_image = Image.fromarray(denoised)
# 使用Tesseract进行OCR
text = pytesseract.image_to_string(pil_image)
print(text)
通过这些示例代码,可以在Python中轻松实现OCR功能,并根据具体需求进行调整和优化。