目录
selenium是一个很流行的自动化测试的库,主要用于模拟浏览器的运行,是web应用测试的工具。
在使用selenium时,需要具备以下软件:
python3,pycharm(可有可无),浏览器驱动(取决于你要模拟哪个浏览器),selenium库
具体如何安装及配置,这不是我要写的重点,网上有很多全面且详细的教程,可以参考
具备以上这些条件以后,我们打开pycharm,New一个新项目,在.venu文件夹下创建一个文件test.py
首先导入selenium库
from selenium import webdriver注:可能有一部分用户安装好selenium库后,导入后运行时,会出现selenium库无法找到的情况,这个时候,依次点击File->Settings->Project:*->python interpreter,点击右上角的Add interpreter,进去后选择system interpreter,选择New,Location选择你安装的的python.exe的位置,点击OK即可
初始化浏览器并打开网页
此时我们可以创建初始化浏览器了,我这里以Edge浏览器为例
driver = webdriver.Edge();此时我们运行代码,为了方便,我加了5秒的停留,不然刚运行就结束了

运行后,自动帮我打开了网页,也可以看到提示edge正由自动测试软件控制
我们如果想访问某个网址,此时需要向网址发送请求,请求方法有很多,我们这里使用get进行请求百度官网
driver.get("http://baidu.com")运行后,它会自动帮我打开百度网页,注意,webdriver会等待页面完全加载,才会把控制权交给测试或脚本
定位网页元素
那我们想在百度搜索框中搜索想要的内容,该如何做呢?
这时候需要进行定位了,我们首先需要定位到搜索框,然后向搜索框中发送消息,输入好后,点击发送。这是流程
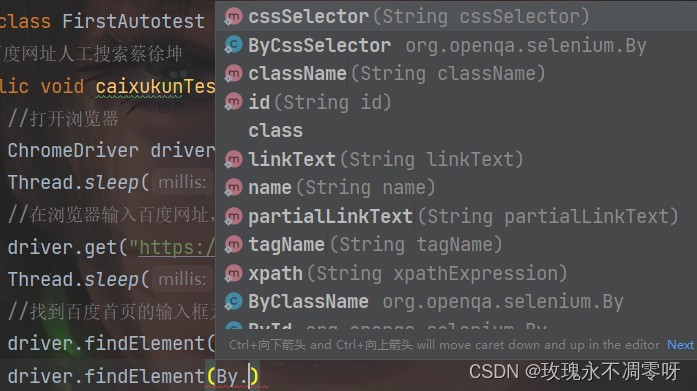
既然需要定位,那我们必须要知道,我们目标位置的属性,比如搜索框,我们需要知道它的id,class或name才可以进行定位,而这些需要我们按f12打开开发者工具进行查找

找到以后我们发现,搜索框的id是kw,因此我们可以根据id进行定位,当然也可以根据类或其他的进行定位,这里有一些方法:
定位的方法
既然使用id定位,那我们直接使用第一行的函数:
| 属性 | 函数 |
| ID | find_element(By.ID,"") |
| CLASS | find_element(By.CLASS,"") |
| CSS | find_element(By.CSS,"") |
| XPATH | find_element(By.XPATH,"") |
| LINK_TEXT | find_element(By.LINK_TEXT,"") |
| PARTIAL_LINK_TEXT | find_element(By.PARTIAL_LINK_TEXT,"") |
| TAG | find_element(By.TAG,"") |
#需要导入
from selenium.webdriver.common.by import By
input = driver.find_element(By.ID,"kw")
或者通过class定位也可以
input = driver.find_element(By.CLASS,"s_ipt")模拟键盘操作
然后定位好以后,我们需要模拟键盘向搜索框input中写入数据,假设我想搜索“python”
这里我们需要使用send_keys进行发送:
input.send_keys("python")此时我们只是输入了,但并没有搜索,所以我们可以模拟键盘输入回车键
//需要导入包
from selenium.webdriver.common.keys import Keys
input.send_keys(Keys.RETURN)同样键盘可以其他快捷键,如下:

这样便成功控制浏览器自动打开百度,并搜索Python了

模拟鼠标操作
同样的,对于搜索这一步,我们也可以使用模拟鼠标的方式来进行。先定位到搜索按钮,然后再使用click 方法进行点击,效果是一样的
driver.find_element(By.ID,"su").click()对于网页元素的操作,可以有如下几种:

但是selenium为我们提供了一个强大的类ActionChains,它允许用户以编程方式执行复杂的鼠标和键盘操作
from selenium.webdriver.common.keys import Keys
#perform() 方法是必须的。它的作用是执行之前链式操作中定义的所有动作。
#click这些事件只有在执行到perform时才会被执行
search = driver.find_element(By.ID,"su")
ActionChains(driver).click(search).perform()除了单击操作,还有下面的操作

至此我们已经完成了一个打开百度,并搜索python的自动化代码了
代码如下:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import ActionChains
#初始化浏览器
driver = webdriver.Edge()
#get请求访问百度网址
driver.get("http://baidu.com")
#定位搜索框
input = driver.find_element(By.ID,"kw")
#driver.find_element(By.CLASS,"s_ipt")
#向搜索框中输入数据
input.send_keys("python")
#input.send_keys(Keys.ENTER)
#点击搜索按钮
#perform() 方法是必须的。它的作用是执行之前链式操作中定义的所有动作。
#click这些事件只有在执行到perform时才会被执行
search = driver.find_element(By.ID,"su")
ActionChains(driver).click(search).perform()
time.sleep(5)
driver.close();xpath方法
XPath 是一种 XML 路径,用于浏览页面的 HTML 结构。它是一种语法或者语言用来查找使用 XML 路径表达的网页中的任意元素
而html就是一种特殊的xml,所以可以利用xpath来查找html中元素
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。如:
/html/body/div[1]/div[2]/div[1]/input
和我们平时看到的文件路径相似
C:/Users/h/AppData
xpath结点
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及根节点
为了解释,我拿一段代码作为示例
<html xmlns:namespace="http://www.example.com">
<head>
<meta charset="utf-8">
<title>xpath教程</title>
</head>
<body>
<!-- 测试 HTML -->
<h1 name="header">我的第一个标题</h1>
<p>我的第一个段落。</p>
</body>
</html>对于上面的代码:
- <html> 就是根节点
- 每个标签都是一个元素,比如:<h1>我的第一个标题</h1>
- <h1 name="header">中的name=“header”就是一个属性
- <p>我的第一个段落。</p> 中的“我的第一个段落。”就是文本
- <html xmlns:namespace="http://www.example.com">中的namespace就是命名空间
- <!-- 测试 HTML -->就是一个注释
节点之间的关系有,父子,同胞等
路径表达式

(图片来源网络,侵删)
和我们平时看到的路径类似,只不过一个是结点,一个是文件夹
问题://div/span 和 //div//span 有什么区别?
//div/span:选择div元素的子节点中的span
//div//span:选择div元素中的所有span的结点
比如对于下面的html,使用“//div/span”只能选中一个span,但是使用"//div//span"可以选中两个span
<div>
<span>Hello<span>
<ul>
<span>World</span>
</ul>
<div>节点和元素的区别
以 * 和 node()为例:
//*:选中了5个元素:(5) [html, head, title, body, div.box]
//node():选中了8个节点:(8) [<!DOCTYPE html>, html, head, title, text, body, div.box, text]
<!DOCTYPE html>
<html>
<head>
<title>题目</title>
</head>
<body>
<div class="box">Hello</div>
</body>
</html>轴
轴相当于是利用节点之间的关系定位节点
语法规则:轴名称::节点测试[谓语]

看完下面的例子就对这个轴的使用理解深刻了
 注:图片来源博主:兰亭序咖啡
注:图片来源博主:兰亭序咖啡
总结的规律:
所有的child::XXX 都可以直接写XXX
比如://a//child::text() --> //a//text()
//div//child::input --> //div//input
到这里关于自动化测试简单的示例就结束了,如果有任何疑问的,欢迎私信或评论区留言~