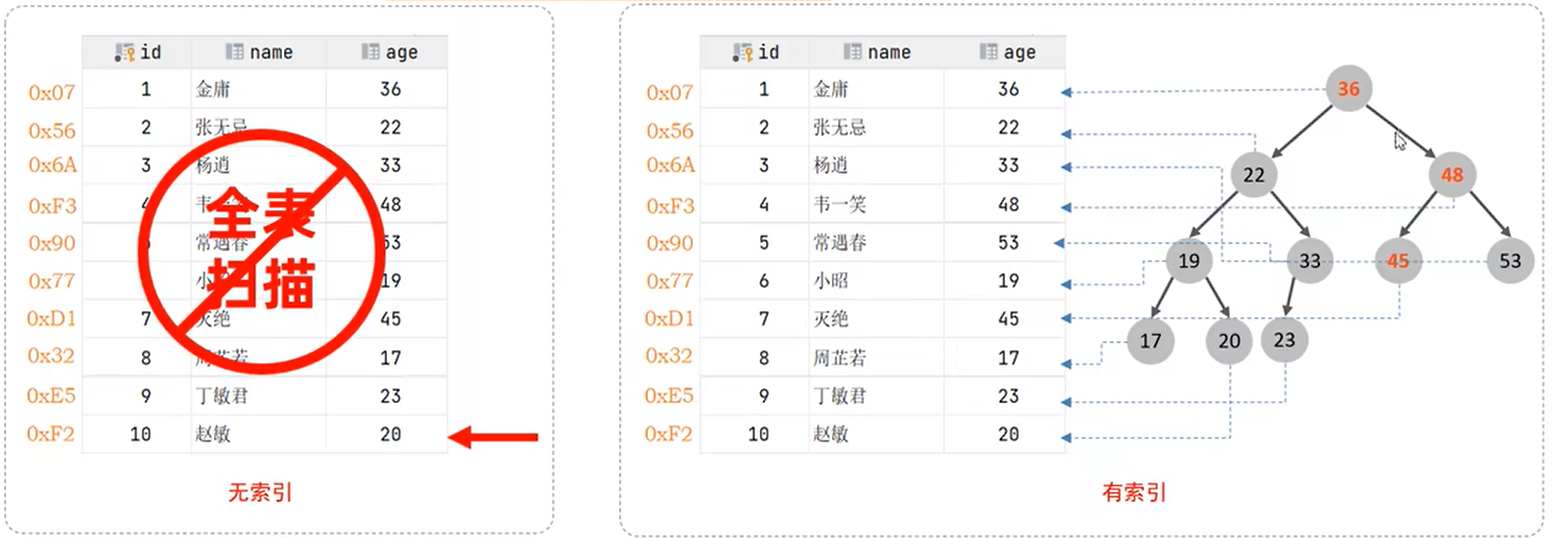
索引是什么? 索引是帮助MySQL高效获取数据排好序的数据结构。 索引为什么使用? 不走索引,会发生全表扫描产生无用的IO。 索引分类 索引的逻辑结构分类 normal普通索引、unique唯一索引、fulltext全文索引、spatial空间索引 1.普通索引:索引允许重复值和空值 2.唯一索引:索引列不允许重复值,但允许空值 3.主键索引:是一种特殊的唯一索引,不允许有空值 4.全文索引:用于查找文本中的关键字,全文索引列必须创建索引 5.空间索引:索引MySQL中存储的地理空间数据 6.位图索引:索引MySQL中存储的位序列数据 7.单列索引:对表中的某列创建索引 8.组合索引:对表中的多个列创建索引 空间索引只能在存储引擎为MyISAM的表中创建。 索引的物理结构分类 聚簇索引、非聚簇索引 1.聚簇索引:索引和数据存放在一起。(MyISAM) 2.非聚簇索引:索引和数据分开存放。(InnoDB) 索引的数据结构 Hash索引、B+树索引 1.Hash索引:键储存列,值储存行。在等值查询效率很高(O1)。但是在范围查询要全表扫描 2.B+树索引:叶子节点储存键值,非叶子节点储存键值范围。在范围查询效率很高(OlogN),叶子节点储存索引字段和数据,索引递增排序,通过双向指针连接(提高区间的访问能力) 索引的使用场景 1.在经常条件查询、排序、分组、联合查询的字段上建立索引 2.在多字段组合查询优先使用复合索引 3.在不重复的字段优先使用唯一索引 4.添加id主键 索引的失效场景 1.在索引列上使用运算符或者函数操作 2.在索引列上使用类型转换 3.在索引列上使用like以%开头 4.在索引列上使用is null或者is not null或者!=,全表扫描比走索引快 9.在复合索引上未使用最左前缀原则 索引的性能分析 使用explain分析sql使用的索引和优化了多少行数据
SQL查询一次可以使用几个索引?
一次支持使用一个索引,可以通过创建复合索引包含多个列。
主键索引和唯一索引的区别?
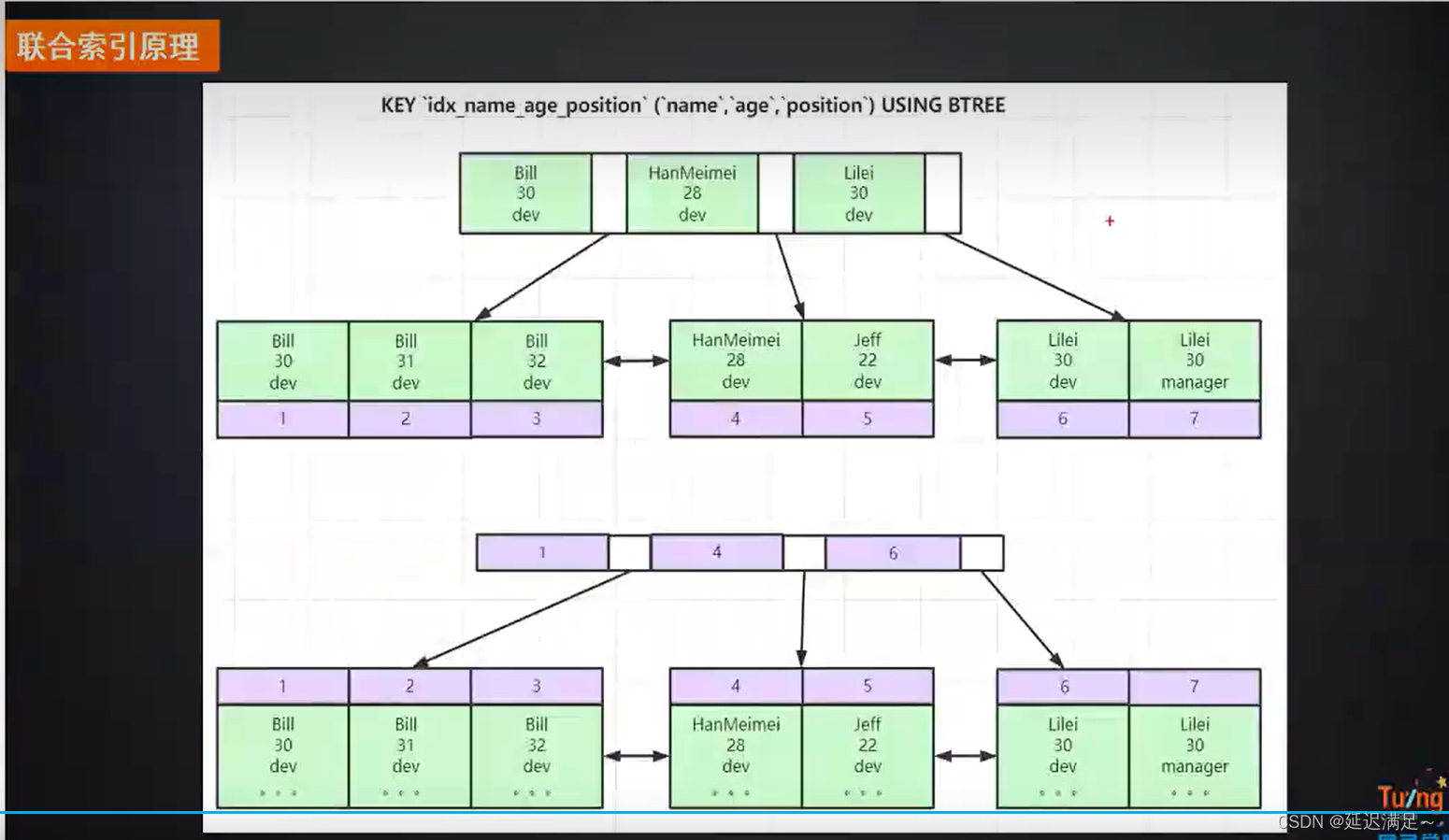
主键索引只能有一个,包括唯一索引并且不能为NULL。为什么联合索引有最左前缀法则?
因为构建的B+索引树导致的,从联合索引的第一列开始,第一列一致的排在一起,然后依次
为什么MySQL索引不使用二叉树?
打个比方如果列是ID递增列,二叉树会一直在增加右边节点,变成了链表。
为什么MySQL索引不使用红黑树?
如果数据量特别多的话,树构造的高度不可控也会导致查找数据很满。
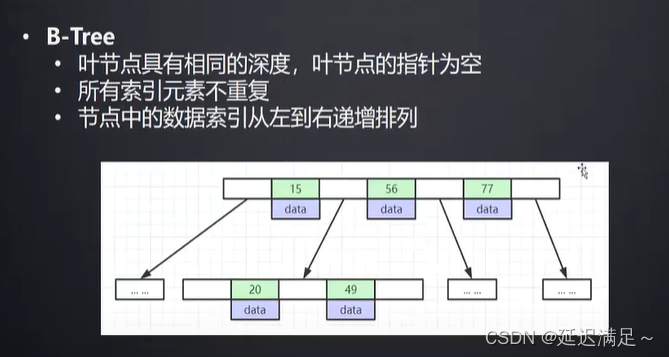
为什么MySQL索引使用B+树?
B+树对比其他索引结构更好的支持范围查询。
因为B+树数据结构非叶子节点不储存数据,在叶子节点储存数据,并且是递增,通过双向链表连接,提高的区间的访问效率。
为什么B+树默认使用三层,不用四层?
B+树查找数据快的原因,是非叶子上的索引大部分加载到内存了,如果是四层的话,上层索引加载到加内存需要的空间特别大。
MyISAM 和 InnoDB 实现 B+ 树索引方式的区别是什么?
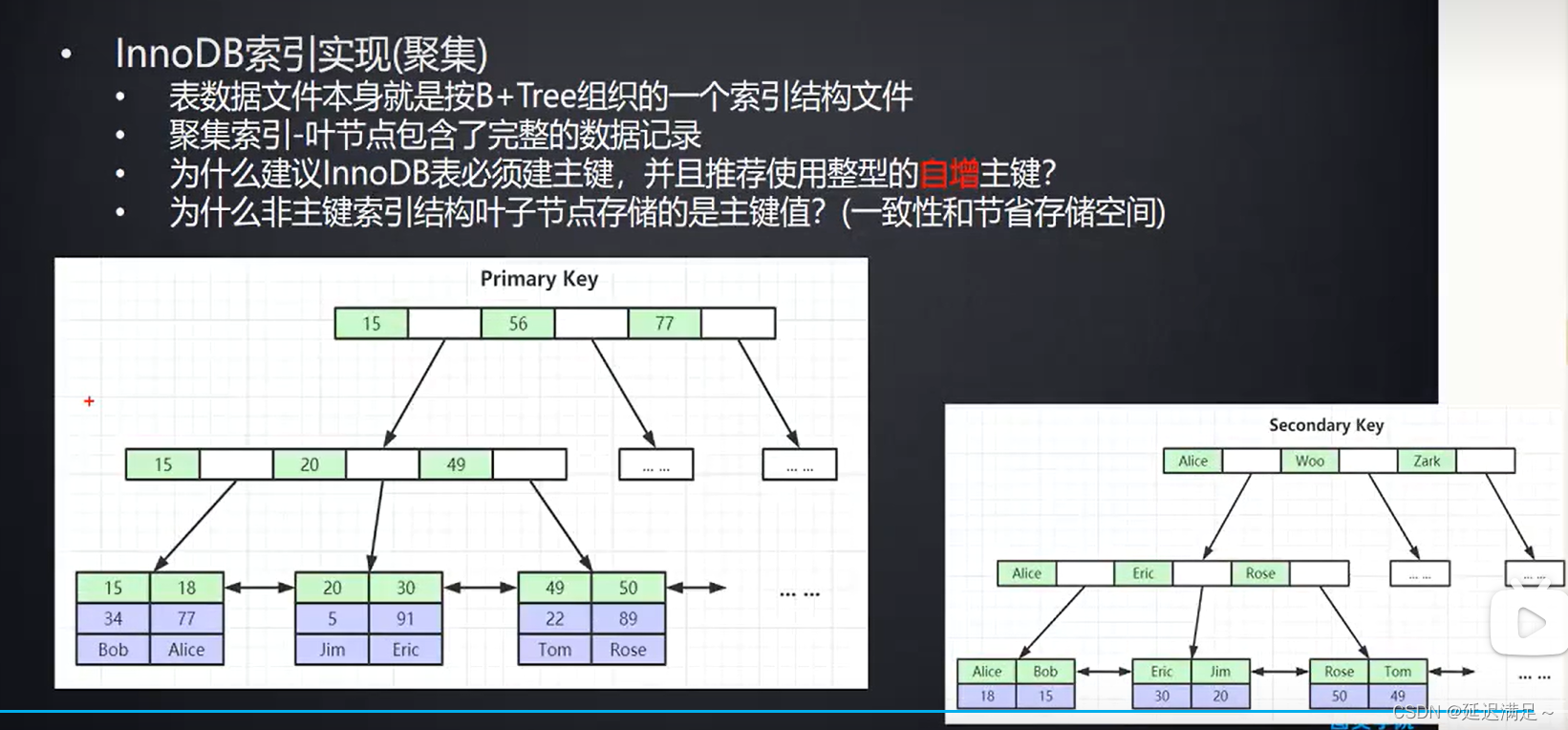
InnoDB:B+树索引叶子节点保存数据本身,数据本身就保存索引文件
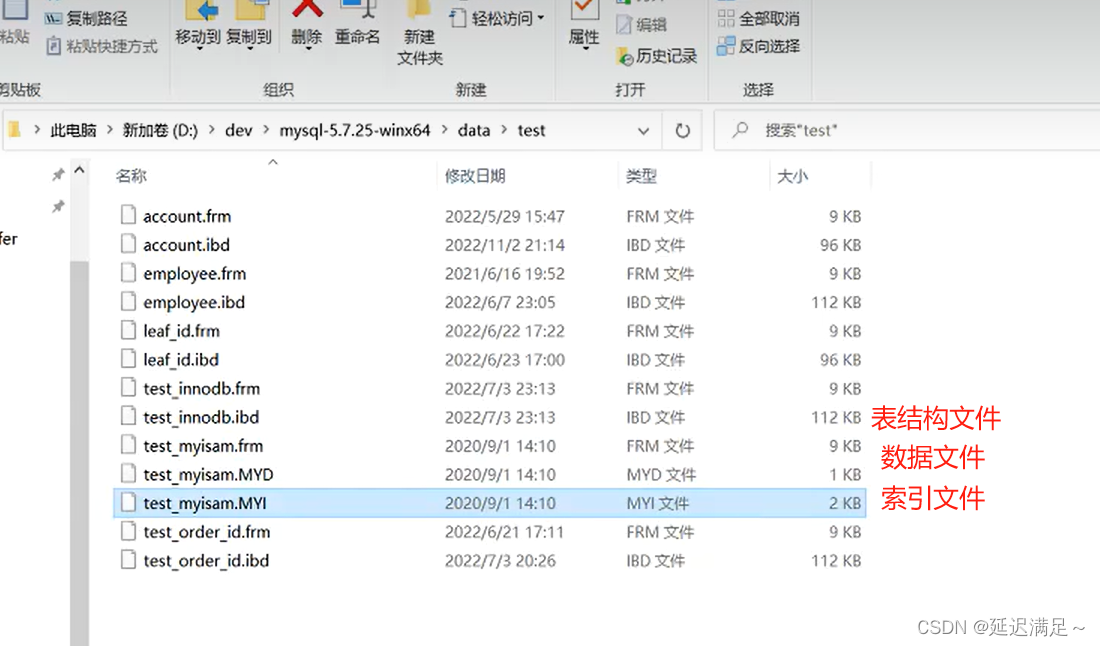
MyISAM :B+树索引叶节点的 data 域存放的是数据记录的地址,索引文件和数据文件是分离的。
为什么InnoDB尽量使用主键?
因为InnoDB是聚簇索引,储存就一个ibd文件,默认需要一个主键索引构造B+树。
如果没有主键索引组织B+树,会隐藏生成一个主键rowid组织B+树。
为什么InnoDB尽量使用自增主键?
以为叶子节点是递增排序好的,自增主键永远会在右边添加新的节点。
如果不是自增主键,之前的的叶子节点会分裂造成性能消耗。
索引的失效场景
在索引列上使用运算符或者函数操作。


在索引列上使用like以%开头

在索引列上使用类型转换
比如:int类型的height字段添加了引号条件、varchar类型的字段查询sql时候没加引号、
用户表的id字段是数字类型,用户账户表关联用户字段的类型是字符串类型。
SELECT * FROM `user` WHERE height= 175; height为varchar类型导致索引失效,尤其多张表时注意
在索引列上使用is null或者is not null或者!=,全表扫描比走索引快
is null 、is not null、!=这些到底会不会使用二级索引还是得具体情况具体分析,主要取决于查询优化器对于使用二级索引+回表 和 全表扫描 两种方式的成本计算和比较,哪个成本低就会用哪个

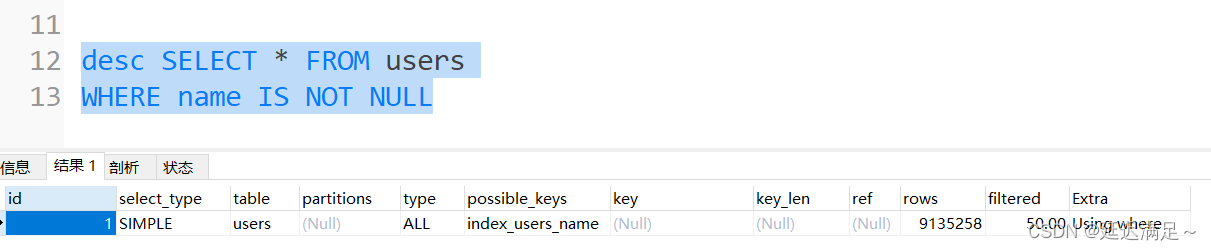

复合索引未使用最左前缀导致索引失效。
索引的优化场景
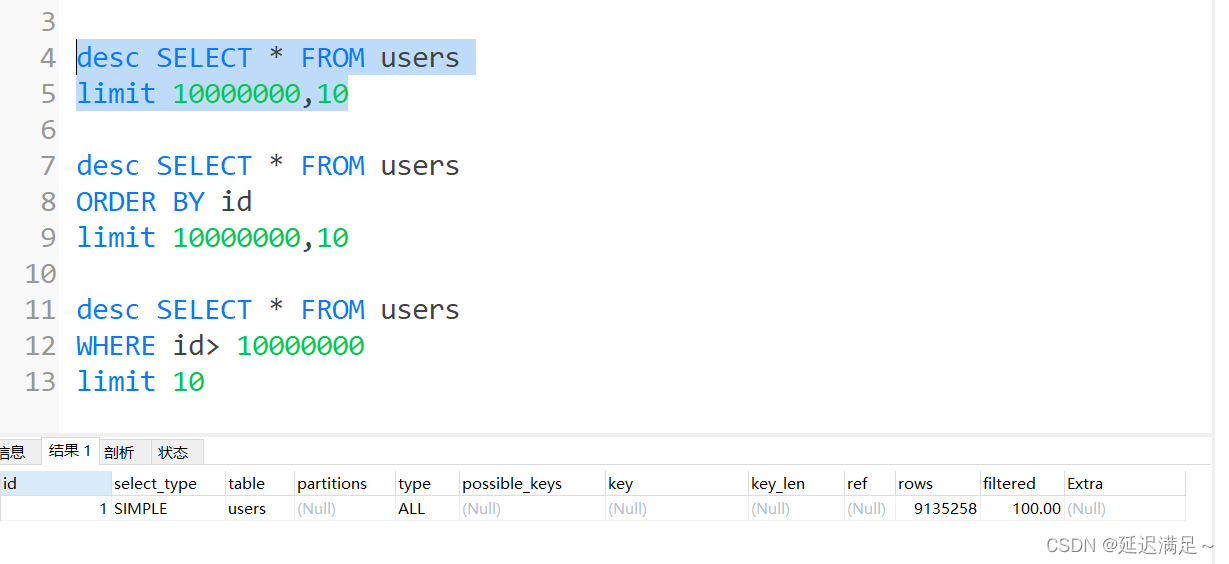
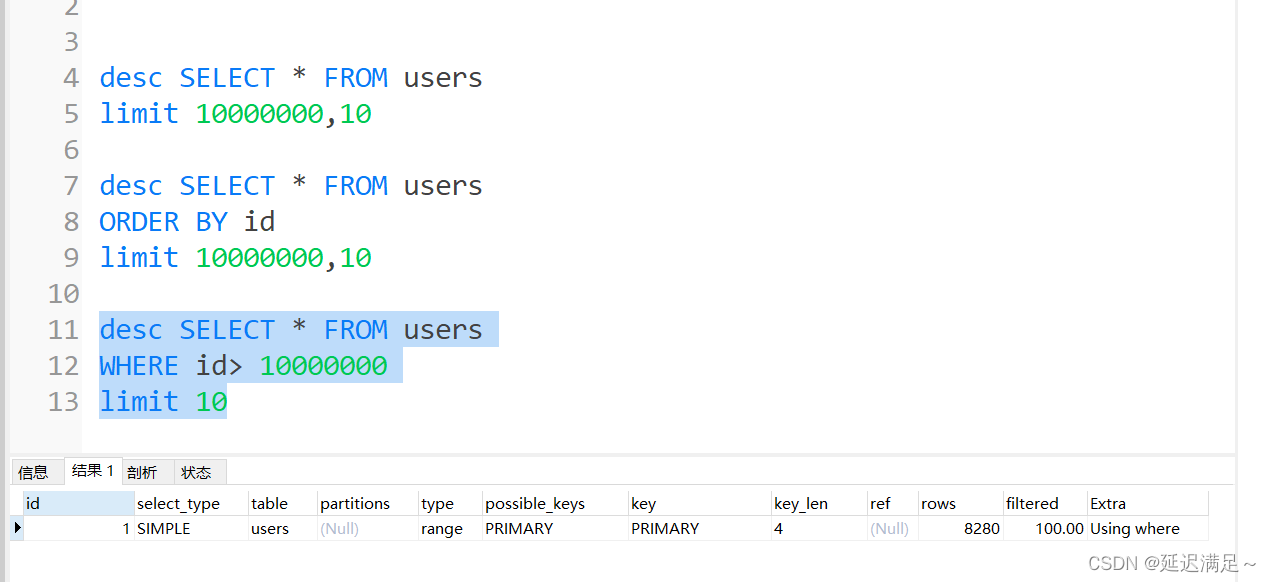
深分页问题
当表的数据量特别大的时候,分页查询后面的数据,需要跳过大量的数据才能到目标数据。
解决
使用where条件利用索引找到开始位置。

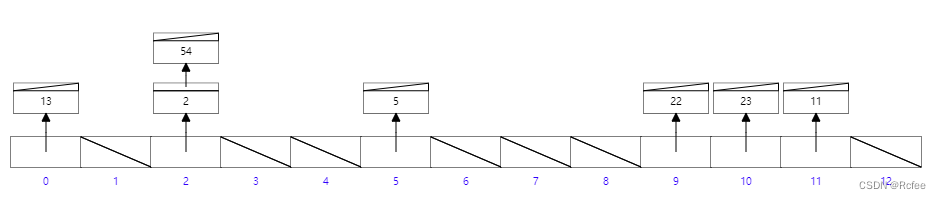
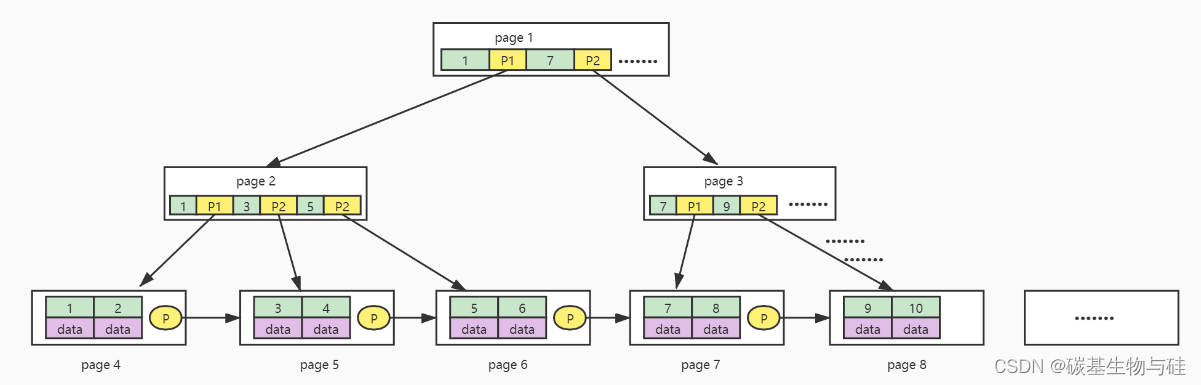
B+树索引的原理
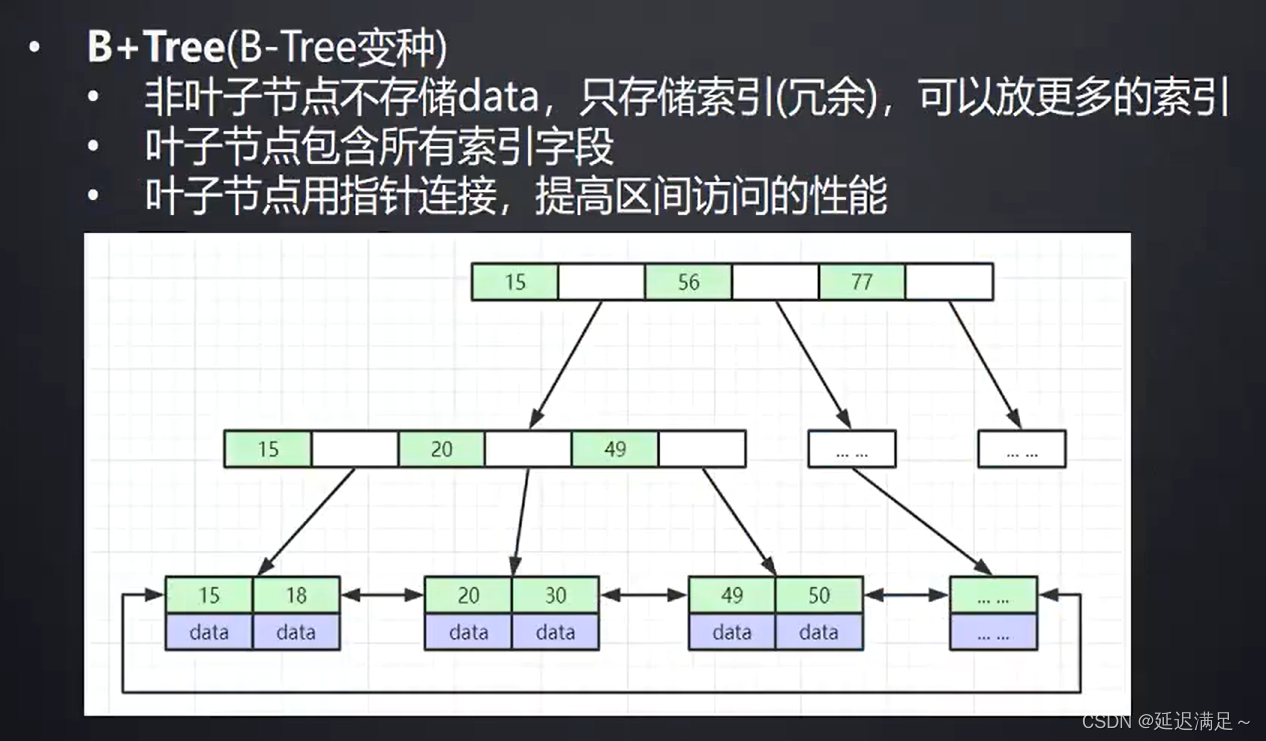
B+树能储存多少索引?
一个节点储存:(16384b/1024=16kb)数据量
非叶节点储存:16384/(8+6)=1170索引数
叶子节点储存:16索引
如果树的高度是三次:1170*1170*16=两千多万索引
16384/(索引类型bigint的大小8b)+(记录磁盘地址的节点大小6b)=1170 索引数
16kb/1kb(默认储存数据大小)=16索引
(第一层索引数1170)*(第二层索引数1170)*(第三层索引数16)=两千多万索引

B+树索引为什么这么快?
默认非子节点都加载加载到内存了,查询数据只需要比对。
联合索引的原理
InnoDB索引的原理
MyISAm索引的原理

MyISAM文件储存
-- 创建表
CREATE TABLE my_table (
id INT AUTO_INCREMENT PRIMARY KEY,
column1 VARCHAR(255),
column2 VARCHAR(255)
);
-- 创建索引
CREATE INDEX idx_column1_column2 ON my_table (column1, column2);
CREATE INDEX idx_column1 ON my_table(column1);
CREATE INDEX idx_column2 ON my_table(column2);
DROP INDEX idx_column2 ON my_table;
DROP INDEX idx_column1_column2 ON my_table;
-- 插入数据
INSERT INTO my_table (column1, column2) VALUES
('apple', 'red'),
('banana', 'yellow'),
('grape', 'purple'),
('apple', 'green'),
('banana', 'green'),
('grape', 'red'),
('apple', 'yellow'),
('banana', 'purple'),
('grape', 'green'),
('apple', 'purple');
DESC
SELECT * FROM my_table
WHERE column1 = 'apple'
OR column2 = 'green'
Using union(idx_column1,idx_column2); Using where
DESC
SELECT * FROM my_table
WHERE column1 = 'apple'
UNION
SELECT * FROM my_table
WHERE column2 = 'green';
DESC
SELECT * FROM my_table
WHERE column1 = 'apple'
OR column2 = 'green'
ORDER BY column1,column2;
Using union(idx_column1,idx_column2); Using where; Using filesort