排序算法
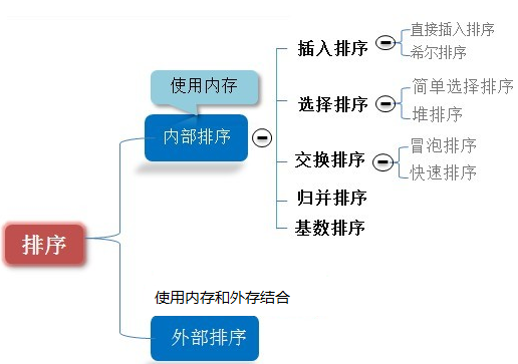
内部排序:指将需要处理的所有数据都加载到内部存储器中进行排序
外部排序:数据量过大,无法全部加载到内存中,需要借助外部存储进行排序
算法的时间复杂度
一个算法花费的时间与算法中语句的执行次数成正比,对算法的时间频度 T ( n ) T(n) T(n) 做如下处理:
- 忽略常数项
- 忽略低次项
- 忽略系数
就得到了算法的时间复杂度 O ( f ( n ) ) O(f(n)) O(f(n)),比如 T ( n ) = 3 n 2 + 7 n + 6 = > O ( n 2 ) T(n)=3n^2 + 7n + 6 => O(n^2) T(n)=3n2+7n+6=>O(n2)
常见的算法时间复杂度由小到大依次为: O ( 1 ) < O ( log 2 n ) < O ( n ) < O ( n log 2 n ) < O ( n 2 ) < O ( n 3 ) < O ( n k ) < O ( 2 n ) O(1)<O(\log_2n)<O(n)<O(n\log_2n)<O(n^2)<O(n^3)<O(n^k)<O(2^n) O(1)<O(log2n)<O(n)<O(nlog2n)<O(n2)<O(n3)<O(nk)<O(2n)
常见的时间复杂度
一个小技巧是记住下面的典型代码结构,就可以快速判断一段代码的时间复杂度。
1.常数阶 O ( 1 ) O(1) O(1)
i = 1
j = 2
i += 1
j += 2
m = i+j
2.对数阶 O ( l o g 2 n ) O(log_2n) O(log2n)
i = 1
n = 10
while(i<n):
i = i*2
3.线性阶 O ( n ) O(n) O(n)
n = 10
for i in range(n):
j = i
j += 1
4.线性对数阶 O ( n l o g N ) O(nlogN) O(nlogN)
n = 10
for i in range(n):
j = 1
while(j<n):
j = j*2
5.平方阶 O ( n 2 ) O(n^2) O(n2)
n = 10
for i in range(n):
for j in range(n):
m = i+j
稳定算法
在排序算法中,如果排序前后两个相等的数的相对位置不变,则算法稳定;如若发生变化,则算法不稳定。
冒泡排序
冒泡排序是稳定算法,其时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
Python 实现
"""
思路:设想有个指针按位滑动,两两交换
代码实现要点:两个for循环,外层循环控制排序的趟数,内层循环控制比较的次数。每趟过后,比较的次数都应该要减1
如果一趟比较下来没有进行过交换,就说明序列有序,因此要在排序过程中设置一个标志flag判断元素是否进行过交换,从而减少不必要的比较
"""
import random
random.seed(42)
random_numbers = [random.randint(1, 100) for i in range(20)]
print(random_numbers)
for i in range(len(random_numbers)-1):
flag = False
for j in range(len(random_numbers)-i-1):
if random_numbers[j] > random_numbers[j+1]:
flag = True
random_numbers[j], random_numbers[j+1] = random_numbers[j+1], random_numbers[j]
if flag is False:
break
print(random_numbers)
---------
[82, 15, 4, 95, 36, 32, 29, 18, 95, 14, 87, 95, 70, 12, 76, 55, 5, 4, 12, 28]
[4, 4, 5, 12, 12, 14, 15, 18, 28, 29, 32, 36, 55, 70, 76, 82, 87, 95, 95, 95]
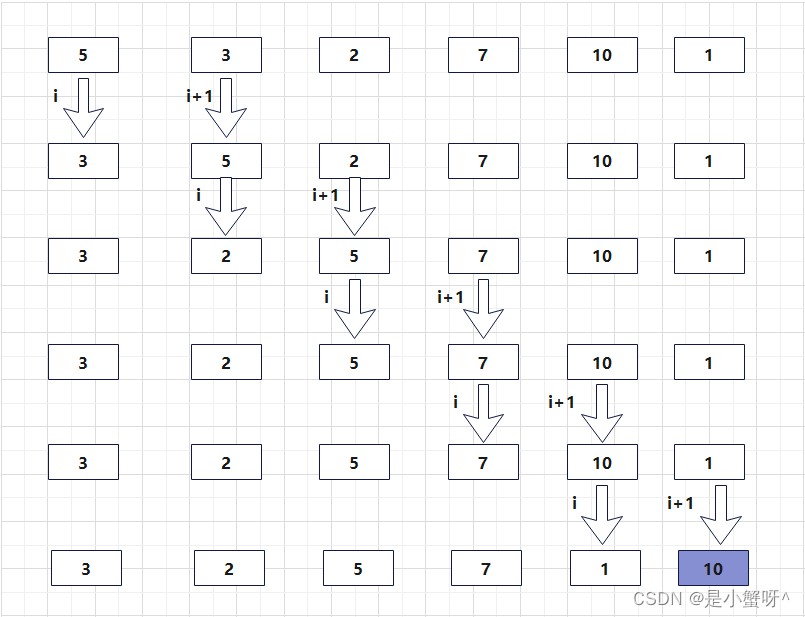
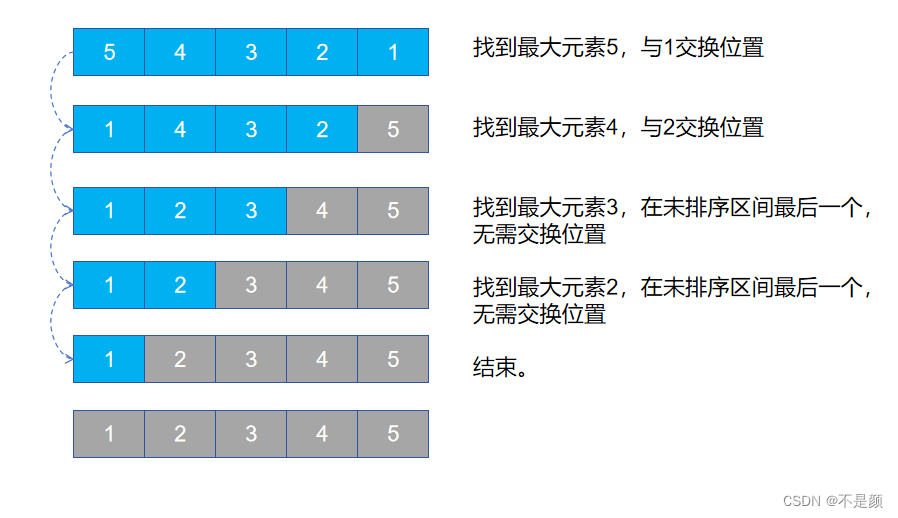
选择排序
选择排序是不稳定算法,其时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
Python 实现
"""
思路:找到数组中最小的元素,与数组第一位元素交换。当只剩一个数时,则不需要选择了,因此需要n-1趟排序
代码实现要点:两个for循环,外层循环控制排序的趟数,内层循环找到当前趟数的最小值,随后与当前趟数组的第一位元素交换
"""
import random
random.seed(42)
random_numbers = [random.randint(1, 100) for i in range(20)]
print(random_numbers)
for i in range(len(random_numbers)-1):
min_idx = i
for j in range(i+1, len(random_numbers)):
if random_numbers[min_idx] > random_numbers[j]:
min_idx = j
random_numbers[i], random_numbers[min_idx] = random_numbers[min_idx], random_numbers[i]
print(random_numbers)
---------
[82, 15, 4, 95, 36, 32, 29, 18, 95, 14, 87, 95, 70, 12, 76, 55, 5, 4, 12, 28]
[4, 4, 5, 12, 12, 14, 15, 18, 28, 29, 32, 36, 55, 70, 76, 82, 87, 95, 95, 95]
插入排序
插入排序是稳定算法,其时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
Python 实现
"""
思路:把n个待排序的元素看成为一个有序表和一个无序表,开始时有序表中只包含一个元素,无序表中包含有n-1个元素,排序过程中每次从无序表中取出第一个元素,把它的排序码依次与有序表元素的排序码进行比较,将它插入到有序表中的适当位置,使之成为新的有序表
"""
import random
random.seed(42)
random_numbers = [random.randint(1, 100) for i in range(20)]
print(random_numbers)
for i in range(1, len(random_numbers)):
key = random_numbers[i]
j = i-1
while j >= 0 and key < random_numbers[j]:
random_numbers[j+1] = random_numbers[j]
j -= 1
random_numbers[j+1] = key
print(random_numbers)
---------
[82, 15, 4, 95, 36, 32, 29, 18, 95, 14, 87, 95, 70, 12, 76, 55, 5, 4, 12, 28]
[4, 4, 5, 12, 12, 14, 15, 18, 28, 29, 32, 36, 55, 70, 76, 82, 87, 95, 95, 95]
希尔排序
希尔排序是不稳定算法,其时间复杂度为 O ( n 1.3 ) − O ( n 2 ) O(n^{1.3})-O(n^2) O(n1.3)−O(n2),视增量大小而定。
Python 实现
"""
希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本
思路:把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止
代码特点:希尔排序会定义一个独特的步长变量gap
"""
import random
random.seed(42)
random_numbers = [random.randint(1, 100) for i in range(20)]
print(random_numbers)
n = len(random_numbers)
gap = int(n/2)
while gap > 0:
for i in range(gap, n):
temp = random_numbers[i]
j = i
while j >= gap and random_numbers[j-gap] > temp:
random_numbers[j] = random_numbers[j-gap]
j -= gap
random_numbers[j] = temp
gap = int(gap/2)
print(random_numbers)
---------
[82, 15, 4, 95, 36, 32, 29, 18, 95, 14, 87, 95, 70, 12, 76, 55, 5, 4, 12, 28]
[4, 4, 5, 12, 12, 14, 15, 18, 28, 29, 32, 36, 55, 70, 76, 82, 87, 95, 95, 95]
快速排序
快速排序是不稳定算法,其时间复杂度为 O ( n log n ) O(n\log n) O(nlogn)。
Python 实现
"""
快速排序是对冒泡排序的一种改进
思路:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列
代码特点:快速排序会定义一个分割数据的轴pivot,使用了分治+递归的思想
"""
import random
random.seed(42)
random_numbers = [random.randint(1, 100) for i in range(20)]
print(random_numbers)
def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)
random_numbers = quicksort(random_numbers)
print(random_numbers)
---------
[82, 15, 4, 95, 36, 32, 29, 18, 95, 14, 87, 95, 70, 12, 76, 55, 5, 4, 12, 28]
[4, 4, 5, 12, 12, 14, 15, 18, 28, 29, 32, 36, 55, 70, 76, 82, 87, 95, 95, 95]
归并排序
归并排序是稳定算法,其时间复杂度为 O ( n log n ) O(n\log n) O(nlogn)。
Python 实现
"""
思路:归并排序采用经典的分治策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之)
代码特点:归并排序会创建临时数组,占用额外空间
"""
import random
random.seed(42)
random_numbers = [random.randint(1, 100) for i in range(20)]
print(random_numbers)
def merge(arr, left_idx, middle_idx, right_idx):
n1 = middle_idx - left_idx + 1
n2 = right_idx - middle_idx
left_temp_arr = [0] * n1
right_temp_arr = [0] * n2
for i in range(0, n1):
left_temp_arr[i] = arr[left_idx + i]
for j in range(0, n2):
right_temp_arr[j] = arr[middle_idx + 1 + j]
i = 0
j = 0
k = left_idx
while i < n1 and j < n2:
if left_temp_arr[i] <= right_temp_arr[j]:
arr[k] = left_temp_arr[i]
i += 1
else:
arr[k] = right_temp_arr[j]
j += 1
k += 1
while i < n1:
arr[k] = left_temp_arr[i]
i += 1
k += 1
while j < n2:
arr[k] = right_temp_arr[j]
j += 1
k += 1
def mergesort(arr, left_idx, right_idx):
if left_idx < right_idx:
middle_idx = int((left_idx + (right_idx - 1)) / 2)
mergesort(arr, left_idx, middle_idx)
mergesort(arr, middle_idx + 1, right_idx)
merge(arr, left_idx, middle_idx, right_idx)
mergesort(random_numbers, 0, len(random_numbers)-1)
print(random_numbers)
---------
[82, 15, 4, 95, 36, 32, 29, 18, 95, 14, 87, 95, 70, 12, 76, 55, 5, 4, 12, 28]
[4, 4, 5, 12, 12, 14, 15, 18, 28, 29, 32, 36, 55, 70, 76, 82, 87, 95, 95, 95]
基数排序
基数排序是稳定算法,其时间复杂度为 O ( d ( r + n ) ) O(d(r+n)) O(d(r+n)),d 代表长度,r 代表关键字的基数,n 代表关键字个数。
Python 实现
"""
基数排序是对传统桶排序的扩展,速度很快
基数排序是经典的空间换时间的方式,占用内存很大, 当对海量数据排序时,容易造成OutOfMemoryError
有负数的数组,不用基数排序来进行排序
"""
import random
random.seed(42)
random_numbers = [random.randint(1, 100) for i in range(20)]
print(random_numbers)
max_num = max(random_numbers)
n = 1
while max_num >= 10 ** n:
n += 1
i = 0
while i < n:
bucket = {}
for x in range(10):
bucket.setdefault(x, [])
for x in random_numbers:
radix = int(x / (10 ** i)) % 10
bucket[radix].append(x)
j = 0
for k in range(10):
if len(bucket[k]) != 0:
for y in bucket[k]:
random_numbers[j] = y
j += 1
i += 1
print(random_numbers)
---------
[82, 15, 4, 95, 36, 32, 29, 18, 95, 14, 87, 95, 70, 12, 76, 55, 5, 4, 12, 28]
[4, 4, 5, 12, 12, 14, 15, 18, 28, 29, 32, 36, 55, 70, 76, 82, 87, 95, 95, 95]
堆排序
堆排序是不稳定算法,其时间复杂度为 O ( n log n ) O(n\log n) O(nlogn)。
Python 实现
"""
堆有大顶堆、小顶堆之分,大顶堆每一次取出来的值都是最大的,在堆排序中用于升序排列;而小顶堆每一次取出来的值都是最小的,在堆排序中用于降序排列
"""
import random
random.seed(42)
random_numbers = [random.randint(1, 100) for i in range(20)]
print(random_numbers)
def heapify(arr, n, i):
largest = i
left = 2 * i + 1
right = 2 * i + 2
if left < n and arr[largest] < arr[left]:
largest = left
if right < n and arr[largest] < arr[right]:
largest = right
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i]
heapify(arr, n, largest)
n = len(random_numbers)
for i in range(n - 1, -1, -1):
heapify(random_numbers, n, i)
for i in range(n - 1, 0, -1):
random_numbers[i], random_numbers[0] = random_numbers[0], random_numbers[i]
heapify(random_numbers, i, 0)
print(random_numbers)
---------
[82, 15, 4, 95, 36, 32, 29, 18, 95, 14, 87, 95, 70, 12, 76, 55, 5, 4, 12, 28]
[4, 4, 5, 12, 12, 14, 15, 18, 28, 29, 32, 36, 55, 70, 76, 82, 87, 95, 95, 95]
总结
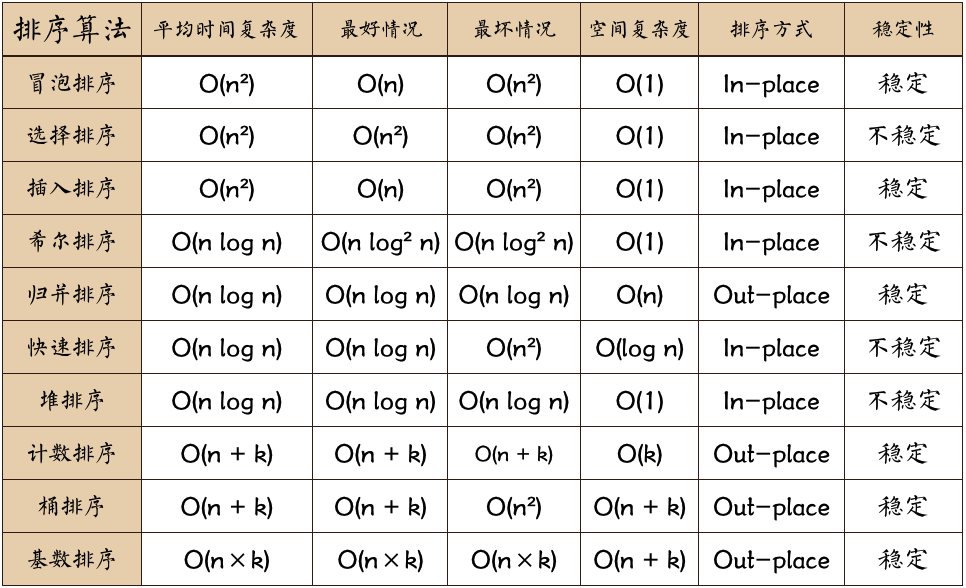
- 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面
- 不稳定:如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面
- 内排序:所有排序操作都在内存中完成
- 外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行
- 时间复杂度:一个算法执行所耗费的时间
- 空间复杂度:运行完一个程序所需内存的大小
- n:数据规模
- k:“桶”的个数
- In-place:不占用额外内存
- Out-place:占用额外内存