一、选择排序——时间复杂度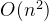
定义:第一趟排序,从整个序列中找到最小的数,把它放到序列的第一个位置上,第二趟排序,再从无序区找到最小的数,把它放到序列的第二个位置上,以此类推。
也就是说,首先从序列中找到最小的元素,放到有序区的第一个位置上,然后再从剩下的无序区中,继续找最小的元素,放到有序区的末尾。
1、容易想到的方法——不推荐
新建一个空列表,然后每遍历一次老列表时候,就把一个最小值,放到新列表里,同时再把这个值从老列表里删除掉。
但这种方法有两个缺点:
(1)额外占内存。因为新建了一个空列表 l1,所以就会多占用一个内存空间。
(2)时间复杂度高,排序效率慢。
列表的增加和删除方法,时间复杂度都是O(n)。
原因:把最小值加到新列表里,首先要先找到最小值,而找最小值的过程,其实就是把所有值都遍历一遍,所以,增加的操作,时间复杂度式O(n)。
同理,对于删除操作也一样,你要删掉最小值,首先得找到,而找最小值的过程就是要把列表全部遍历一遍,时间复杂度也是O(n)。
所以,法1中,增加和删除操作,它俩时间复杂度其实也就是O(n)+O(n),因为他俩是并行运行的,不是嵌套运行,所以结果还是O(n)。外面还有一个for循环,所以法1代码,复杂度就是。
# 法1
def select_sort_simple(li):
l1 = []
for i in range(len(li)): # 时间复杂度o(n)
l1.append(min(li))
li.remove(min(li))
return l1
result = select_sort_simple([5, 3, 7, 2, 4])
print(result)
# 结果:
[2, 3, 4, 5, 7] 或许你会说,把最小值,赋值给一个变量,比如,a=min(li),然后每次增加删除这个值,结果还一样吗?答案是肯定一样的,因为,你即使把它赋值给一个变量,但前提,你也得先找到这个最小值,而找最小值的过程就是把列表所有值都遍历一遍,此时它的复杂度就已经是了,再加上外面的for循环,代码整体复杂度还是
。
# 法2 最小值,赋值给一个变量
def select_sort_simple(li):
l1 = []
for i in range(len(li)): # 时间复杂度 O(n)
a=min(li) # 时间复杂度 O(n)
l1.append(a)
li.remove(a)
return l1
result = select_sort_simple([5, 3, 7, 2, 4])
print(result)
# 结果同上2、使用切片的方式控制无序区——推荐
使用切片的方式控制无序区,每一趟排序后,都将无序区中的最小值,放到无序区的第一个位置,也就是说,把无序区的最小值跟无序区的第一个元素进行交换,此时,这个最小值也就自然放到了有序区的末尾。
跟上面方法相比,虽然时间复杂度一样,但是不用新建空列表。
# 推荐!!!
def select_sort(li):
for i in range(len(li) - 1): # 总共要排n-1趟
min_val = min(li[i:]) # !!! 每遍历一次,无序区就会少一个数
a = li.index(min_val) # 找到最小值的下标
li[i], li[a] = li[a], li[i] # 每趟遍历,就把最小值与这趟对应位置上的数进行交换
# 或者说,就是把无序区的最小值与无序区第一个数进行交换
return li
result = select_sort([5, 1, 2, 4])
print(result)
# 结果:
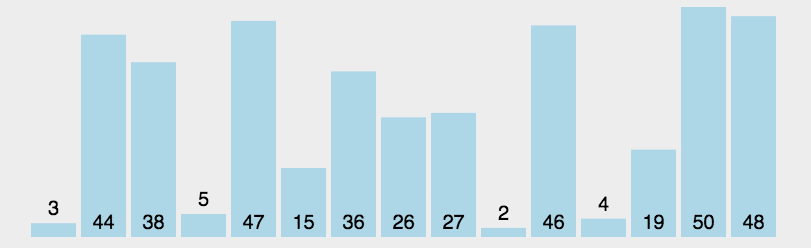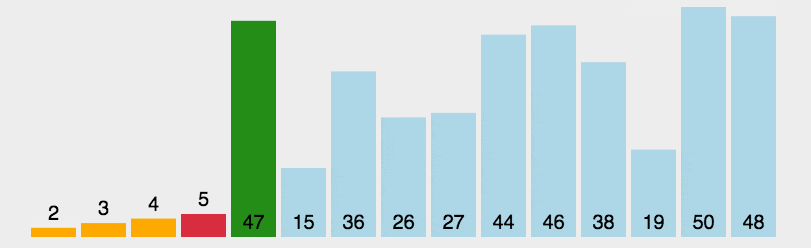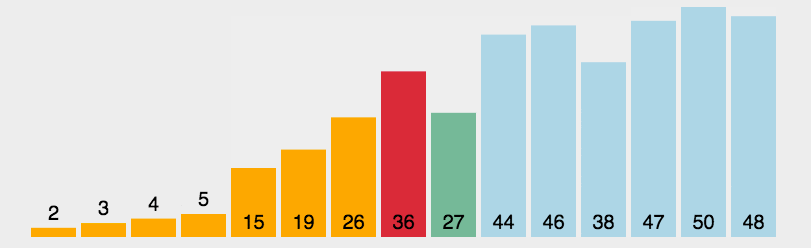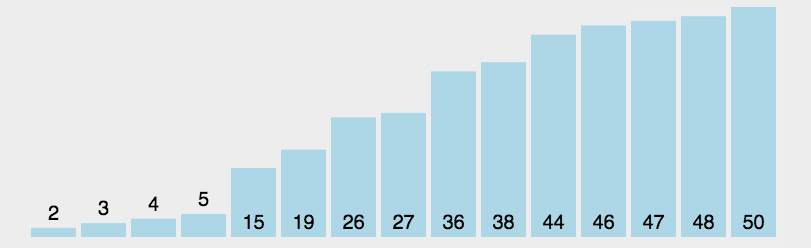
[1, 2, 4, 5]效果图:

当然也可以输出每趟排序的结果,结果跟上图也是一样的:
def select_sort(li):
for i in range(len(li) - 1): # 总共要排n-1趟
min_val = min(li[i:])
a = li.index(min_val) # 找到最小值的下标
li[i], li[a] = li[a], li[i]
print(li) # !!每趟排序后的结果
return li
result = select_sort([5, 1, 2, 4])
print("最终排序结果", result)
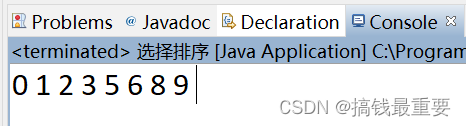
# 结果:
[1, 5, 2, 4]
[1, 2, 5, 4]
[1, 2, 4, 5]
最终排序结果 [1, 2, 4, 5]上面方法中,使用的是切片来控制无序区的大小,(或者叫范围),然后再从这个范围里找最小值,这里呢,我们也可以使用 for 循环的形式来控制无序区的范围。代码如下:
这个跟上面方法类似,但利用切片方式控制无序区范围,相比for循环会更加简洁明了,所以推荐切片的方法。
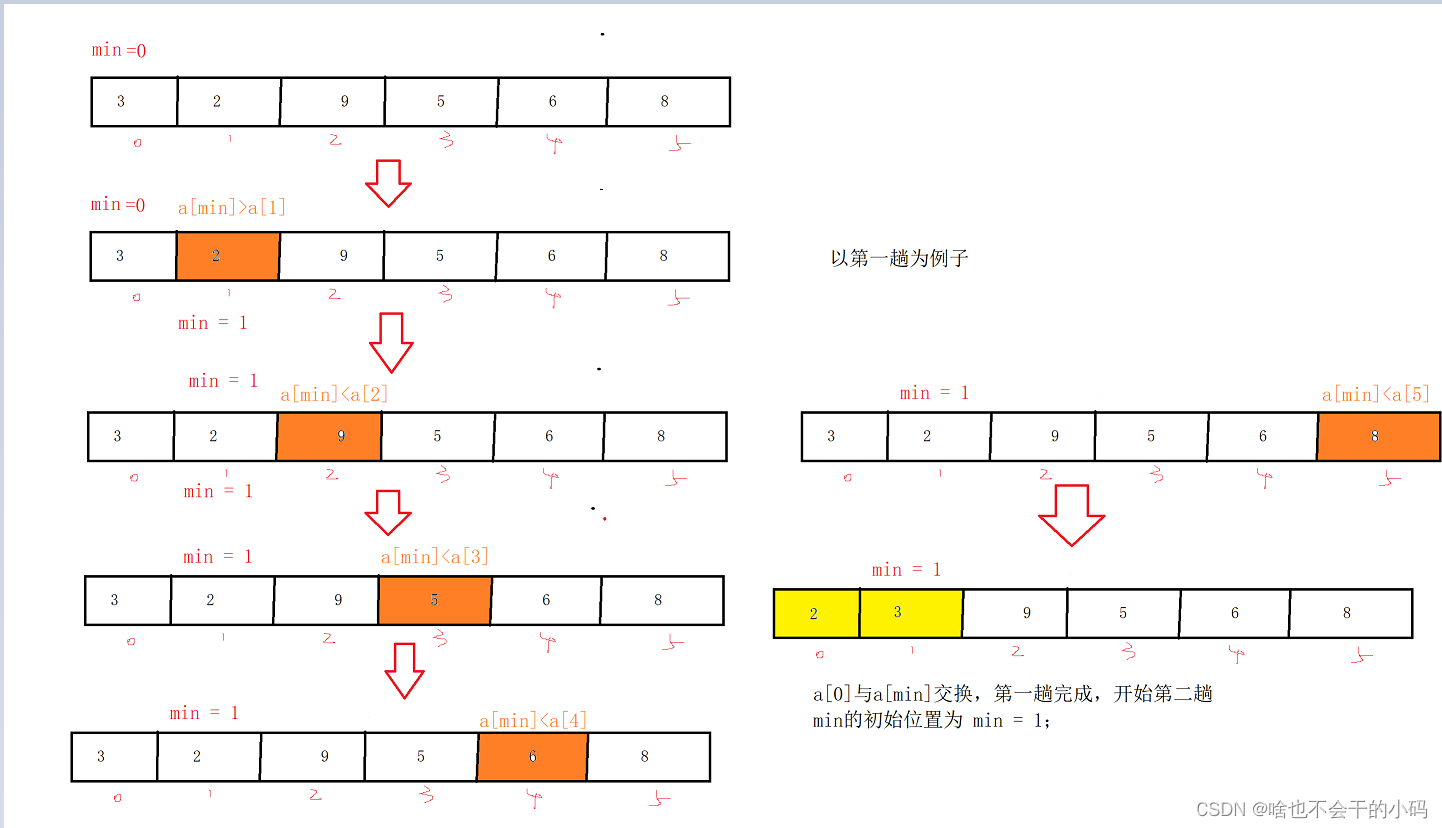
def select_sort(li):
for i in range(len(li) - 1): # 总共要排n-1趟
min_loc = i # 假设无序区的第一个数是最小数
for j in range(i+1, len(li)): # 遍历无序区
if li[j] < li[min_loc]: # 如果无序区中,有个数比无序区第一个数小
min_loc = j # 改变最小值的下标
li[i], li[min_loc] = li[min_loc], li[i] # 将无序区第一个数与最小数进行交换
print(li) # 每趟排序后的结果
return li
# result = select_sort([3, 4, 2, 1, 5, 6, 8, 7, 9])
result = select_sort([5, 1, 2, 4])
print("最终排序结果", result)
# 结果:
[1, 5, 2, 4]
[1, 2, 5, 4]
[1, 2, 4, 5]
最终排序结果 [1, 2, 4, 5]