消息队列是什么?
在我们的很多编程的时候都会听到mq,这个东西也在很多地方体现出来了作用?先来总体看一下消息队列是什么?
消息队列是一种用于进程间通信的技术,能够解耦发送和接收消息的组件,提供异步消息传递、负载均衡和弹性伸缩等功能。
它的基本原理是将消息存储在一个队列中,由消息生产者(producer)将消息发送到队列,消息消费者(consumer)从队列中取出消息进行处理。生产者和消费者可以是同一个系统的不同部分,也可以是完全独立的系统。
以下是消息队列的一些关键特性和优点:
- 解耦:生产者和消费者不需要直接交互,生产者只需将消息发送到队列,消费者只需从队列获取消息。这种松耦合使得系统更具弹性和可维护性。
- 异步处理:生产者可以立即将消息发送到队列并继续处理其他任务,而消费者可以在稍后时间处理这些消息。这有助于提高系统的响应速度和吞吐量。
- 负载均衡:当有多个消费者时,消息队列可以均匀地分配消息,防止某些消费者过载,而其他消费者闲置。
- 弹性伸缩:在高峰期,可以增加消费者的数量来处理大量消息,而在低峰期可以减少消费者的数量,以节省资源。
- 持久化:很多消息队列实现支持持久化存储,确保消息在系统崩溃或重启后不会丢失。
常见的消息队列系统有 RabbitMQ、Apache Kafka、ActiveMQ 和 Amazon SQS 等,每种系统有不同的特点和适用场景。选择合适的消息队列系统,需要根据具体应用场景的需求,如消息吞吐量、延迟、持久化需求、分布式特性等进行评估。
通过上面的总结,可以很清楚的看到,mq的功能,这些功能在很多时候会有作用,尤其对于异步进行消息处理,还有服务之间的解耦,都会大大提升编写程序的整体性能。
实现mq要具备哪些要素呢?
1. 持久化(Durability)
确保消息在存储中不会丢失,特别是在系统崩溃或重启的情况下。可以使用日志或数据库来持久化消息。
这个是很必要的条件,当生产者将数据存放到消费队列之后,消费者还没有来得及进行消息,如果出现问题,那这些数据是要进行落盘的,这让我想到了之前和别人讨论go中channel是否可以实现,如果学过这门语言,可以清楚的了解到确实可以通过管道来进行异步通信,但是,管道需要进行开辟空间进行存储,这样的话,当使用管道作为mq的时候,就需要去维护大量数据进行落盘的问题,还有就是宕机之后需要处理的事情。
2. 高可用性(High Availability)
系统应具备容错能力,确保在部分节点故障时仍能正常工作。这可以通过多节点集群和主从复制来实现。
使用mq的时候,大部分都是高并发,这个时候会有多个大量数据进行涌入,需要做好万全的准备,保证能够不出现问题,或者出现问题之后,能够很快时间就进行恢复。多节点可以帮助提高容错率。
3. 消息保证(Message Guarantees)
- At-most-once delivery: 每条消息最多被处理一次,可能会丢失。
- At-least-once delivery: 每条消息至少被处理一次,可能会重复处理。
- Exactly-once delivery: 每条消息被精确处理一次,要求更复杂的实现。
要保证幂等性,当同一个客户进行多次请求的时候,只需要进行一次消费。并且当数据到达消费的时候,要保证消费。不能出现没有对数据进行消费的问题。
4. 顺序保证(Ordering Guarantees)
确保消息按照发送的顺序被处理,这在某些应用场景中非常重要。可以使用分区(Partitioning)技术来保证同一分区内的消息顺序。
mq是一个队列,学过数据结构的都知道先进先出这个问题,所以mq里面的数据需要保证顺序。
5. 扩展性(Scalability)
系统应能够处理不断增长的消息量和消费者数量。这可以通过水平扩展(添加更多节点)来实现。
当数据量提升的时候,可以通过增加节点的方式来实现水平拓展,也就是主从多节点的问题。
6. 可靠性(Reliability)
系统应能在网络故障、节点崩溃等情况下保证消息不丢失或重复处理。
在分布式的系统中,很多问题的出现就是因为复杂多变的文罗环境,导致信息延迟之类的问题,当使用mq的时候,需要保证就算出现了这些问题,中间的消息也不会丢失,数据处理的幂等性的问题也不会出现。
7. 性能(Performance)
优化消息的吞吐量和延迟,确保系统能高效处理大量消息。可以采用批处理(Batch Processing)和异步I/O等技术。
高并发的情况下,对于性能是必不可少的,所以需要保证整提性能。
8. 安全性(Security)
确保消息在传输和存储中的安全,防止未经授权的访问。可以使用加密和访问控制机制。
9. 消息格式(Message Format)
定义统一的消息格式,确保生产者和消费者能够正确解析和处理消息。常用的格式有 JSON、XML、Protobuf 等。
对于mq需要消息统一,这样可以方便前后进行序列化,反序列化。
10. 管理和监控(Management and Monitoring)
提供监控和管理工具,帮助运维人员查看系统状态、性能指标、错误日志等。可以集成Prometheus、Grafana等监控工具。
需要保证持久化
在实现消息队列的整个过程中,需要清楚的就是要保证整个数据的不丢失,那什么时候可能会数据丢失呢?又有什么策略呢?那肯定就是三个部分了,生产者,消费者,以及队列之中。
生产者(Producer)保证数据不丢失
- 消息确认(Acknowledgment)
- 生产者发送消息后需要等待队列的确认,只有在收到确认后,才认为消息已经成功发送。
- 采用重试机制,如果在一定时间内没有收到确认,则重新发送消息。
- 持久化存储(Persistent Storage)
- 在发送消息之前,将消息持久化存储在本地数据库或文件系统中,确保在系统崩溃或重启时消息不会丢失。
- 发送成功后,可以删除本地持久化的消息。
队列(Queue)保证数据不丢失
- 持久化(Durability)
- 消息在队列中应持久化存储,可以使用磁盘存储或数据库来保存消息数据。
- 常见的持久化实现有日志文件、WAL(Write-Ahead Logging)等。
- 复制(Replication)
- 使用多节点集群或主从复制,确保在某个节点故障时,其他节点能够继续提供服务。
- 常见的复制策略有同步复制和异步复制。
- 事务(Transactions)
- 使用事务机制,确保消息的写入和读取操作具有原子性。
- 可以使用分布式事务或两阶段提交(2PC)来确保消息一致性。
消费者(Consumer)保证数据不丢失
- 消息确认(Acknowledgment)
- 消费者在成功处理消息后,向队列发送确认,告知消息已经被处理。
- 只有在收到消费者的确认后,队列才会删除该消息。
- 重试机制(Retry Mechanism)
- 消费者在处理消息时,如果发生错误,可以将消息重新放回队列,稍后再进行处理。
- 可以设置重试次数和重试间隔,避免消息无限制地重试。
- 持久化处理结果(Persistent Processing Results)
- 在处理消息时,将中间结果和最终结果持久化存储,确保即使在系统崩溃或重启时,处理过程和结果不会丢失。
- 可以使用数据库或分布式存储系统来存储处理结果。
监控和报警(Monitoring and Alerting)
- 监控
- 实时监控消息队列的状态,包括消息堆积数量、消息处理速度、系统资源使用情况等。
- 使用监控工具如Prometheus、Grafana等进行可视化监控。
- 报警
- 设置报警规则,当出现异常情况(如消息堆积过多、处理速度过慢、节点故障等)时,及时发送报警通知。
- 可以通过邮件、短信、即时通讯工具等方式发送报警。
redis中有哪些数据结构可以进行消费队列的编写?
对于redis就不进行过多的讲解,主要来看看其中的数据结构用来实现消费队列的优缺点
适用场景
- 简单的消息队列,FIFO(先进先出)顺序处理消息。
实现方法
- 生产者使用
RPUSH将消息添加到队列末尾。 - 消费者使用
LPOP从队列头部取出消息。可以使用BRPOP进行阻塞等待。
优点
- 实现简单,使用 Redis 原生命令。
- 支持阻塞操作,消费者可以等待新消息到达。
缺点
- 对于非常大的消息量,性能可能下降。
- 不支持消息优先级或延迟处理。
适用场景
- 需要按优先级或时间顺序处理消息的场景。
实现方法
- 使用
ZADD将消息添加到有序集合,分数可以是时间戳或优先级。 - 使用
ZRANGE或ZRANGEBYSCORE取出消息,并使用ZREM删除已处理的消息。
优点
- 支持按分数排序,可以实现优先级队列。
- 支持范围查询,灵活性高。
缺点
- 相对复杂,消息处理涉及多个命令。
- 对于大量消息的频繁操作,性能可能受到影响。
适用场景
- 实时消息传递和广播通知。
实现方法
- 生产者使用
PUBLISH将消息发布到频道。 - 消费者使用
SUBSCRIBE订阅频道并接收消息。
优点
- 支持实时消息传递,适合广播场景。
- 消费者无需轮询,可以立即收到消息。
缺点
- 不支持消息积压,消费者离线期间的消息会丢失。
- 不保证消息顺序和持久性。
适用场景
- 需要存储复杂消息结构和元数据的场景。
实现方法
- 使用
HSET将消息存储为哈希表中的字段。 - 使用
HGET或HSCAN获取消息。
优点
- 支持复杂消息结构,方便存储和查询元数据。
- 操作时间复杂度为 O(1),查找速度快。
缺点
- 需要额外的序列化和反序列化操作。
- 不适合简单的 FIFO 队列实现。
适用场景
- 需要强大的消息队列功能,如持久化、消息消费跟踪和分区等。
实现方法
- 生产者使用
XADD将消息添加到流。 - 消费者使用
XREAD或XREADGROUP读取消息,并使用XACK确认处理。
优点
- 支持持久化和消息积压,确保数据不丢失。
- 支持消费组(Consumer Group),便于负载均衡和并行处理。
- 提供丰富的消息跟踪和管理功能。
缺点
- 实现较为复杂,需要了解更多 Redis 命令和机制。
- 对于小规模和简单的消息队列场景,可能过于复杂。
通过上面的了解,就会发现在redis中有很多的可以用来实现mq,那么接下来主要是通过stream实现mq。
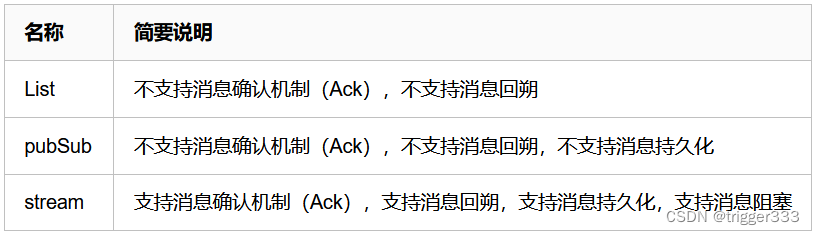
对比总结


使用stream
具体的redis指令就不做过多的分析,接下来就要是通过小徐先生的几张图,来了解里面的具体流程,让大家先清楚一个大概过程,然后再进行深究具体问题。
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
下面这个是别人公众号上面的图,利用这个图,可以很清楚的看到客生产者使用redis的命令将数据放到redis的streams里面之中,然后消费者通过获取信息进行消费,如果消费成功的话,就是要给redis回应一个ack,这样就完美的保证了数据被消费。
消费消息
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
通过上面的这个流程图,好好的缕一下整个的流程
消费者整体流程
- Consumer.run:
- 消费者开始运行,进入消息处理循环。
- receive msg:
- 消费者从消息队列中接收消息。
- handle success?:
- 检查消息处理是否成功:
- 如果成功,继续下一步。
- 如果失败,增加失败计数(
failCnt++)。
- 检查消息处理是否成功:
- 成功处理(handle success):
- ack:
- 消费者向消息队列确认消息已成功处理(acknowledge)。
- start next round:
- 进入下一轮消息接收和处理。
- ack:
- 失败处理(failCnt++):
- failCnt++:
- 处理失败时,增加失败计数(failCnt)。
- failCnt++:
- failCnt over threshold:
- 检查失败计数是否超过阈值:
- 如果超过,进入“dead letter”处理。
- 如果未超过,继续处理挂起的消息。
- 检查失败计数是否超过阈值:
- deliver to dead letter:
- 如果失败计数超过阈值,将消息发送到死信队列(dead letter queue)。
- receive pending msg:
- 接收挂起的消息。
- handle success?:
- 检查消息处理是否成功:
- 如果成功,继续下一步。
- 如果失败,增加失败计数(
failCnt++)。
- 检查消息处理是否成功:
- ack:
- 如果挂起的消息处理成功,向消息队列确认消息已成功处理(acknowledge)。
- 循环:
- 整个过程是一个循环,消费者持续从队列中接收、处理消息,并根据处理结果进行相应操作。
关键步骤解释
- ack**(acknowledge)**:
- 消费者确认消息已成功处理,通知消息队列可以删除该消息。
- failCnt++:
- 消息处理失败时,增加失败计数,用于判断是否将消息移入死信队列。
- deliver to dead letter:
- 消息处理失败次数超过阈值,将消息移入死信队列,用于后续处理或人工干预。
- start next round:
- 成功处理消息后,消费者开始下一轮消息处理。
优点
- 可靠性:
- 通过失败计数和死信队列机制,确保即使消息处理失败,也不会丢失消息。
- 可监控性:
- 失败计数和死信队列提供了监控和管理消息处理失败的手段。
- 弹性:
- 消费者能够自动处理挂起的消息,具有一定的弹性和容错能力。
从以上的内容,可以很清楚的了解到这个的整体过程,所以接下来就最重要的是代码的梳理了。