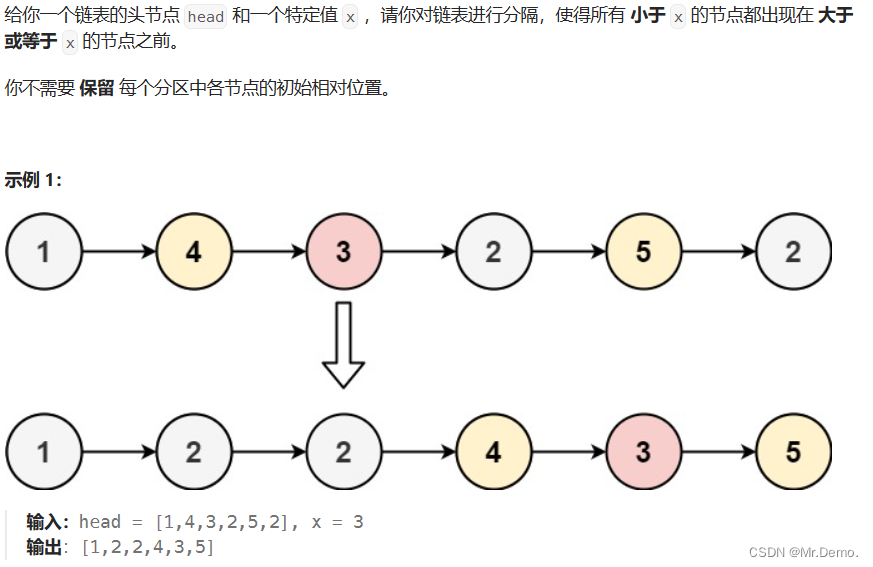
前言
我们之前学习过顺序表,也学习了 ArrayList 类的使用,它们的本质实际上就是数组。而今天我们要介绍的链表和它们都不一样,它解决了 ArrayList 不适用做任意位置插入和删除的缺点,链表不需要将元素整体向前或者向后搬移,插入和删除都十分方便,接下来就让我们一起来认识链表吧
1. 链表的介绍
1.1 链表的定义
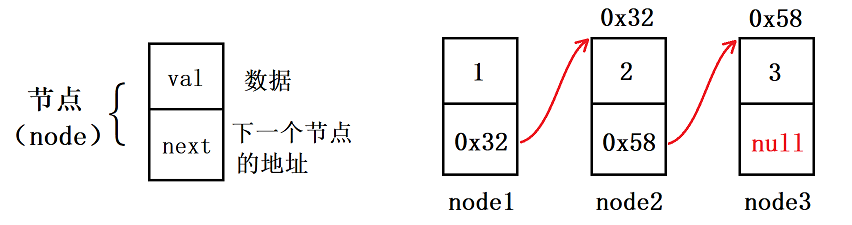
链表是由多个地址不连续的存储节点连接而成的一种线性表,这些节点在内存中不是连续存放的,每个节点不仅存放实际的数据(数据域),而且包含下一个节点的地址信息(地址域,也叫做指针域)
注意:
- 链表在逻辑结构上是连续的,在物理结构上不一定连续(和顺序表不一样)
- 节点的地址域可以存储下一个节点的地址,最后一个节点的地址域为 null
- 因为创建节点的申请是在堆上的,两次申请的空间可能连续,也可能不连续,它们通常分散在内存中的任何位置
1.2 链表的结构种类
我们可以根据是否带头节点、单向或双向链接、以及是否循环来分类,一共有八种类型,每种类型都有其独特的特点
带头节点或不带头节点
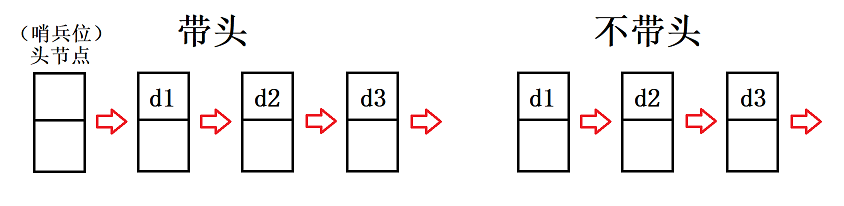
- 带头链表:最前面有一个头节点,称作“哨兵位”,它不存储数据,用来指向第一个存储有效数据的节点
- 不带头链表:直接从第一个节点开始,没有额外的头节点
单向或者双向
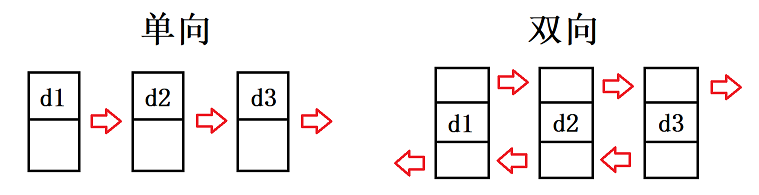
- 单向链表:每个节点只包含一个指向下一个节点的地址。它只能从前往后遍历,不能从后往前遍历
- 双向链表:每个节点包含两个地址,一个指向前一个节点,一个指向后一个节点。它可以从任一节点开始向前或向后遍历
循环或者非循环
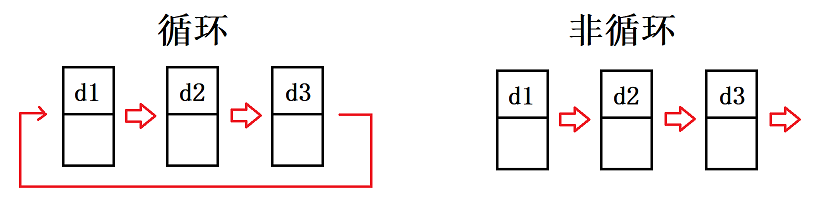
- 循环链表:链表的最后一个节点的地址域指向链表的第一个节点,形成一个闭环
- 非循环链表:链表的最后一个节点的地址域为空(null),表示链表的结束
在上面八种组合中,我们主要介绍的是:无头单向非循环链表,无头双向非循环链表
- 无头单向非循环链表:结构简单,是一种非常灵活的数据结构,适用于多种不同的应用场景,我们在力扣上刷链表题遇到最多的就是这种类型,也经常出现在很多笔试面试中
- 无头双向非循环链表:在需要双向遍历和频繁修改链表结构的场景中非常有用,而且在 Java 的集合中 LinkedList 的底层就是无头双向非循环链表
2. 单向链表的模拟实现
请注意,以下的链表默认为 无头单向非循环
链表是由若干个节点组成的,而节点又是个完整的结构,包含数据域和地址域,所以我们可以把节点定义为内部类,这样就可以更方便的使用节点
除此之外,我们还需要定义成员变量 head,用来指向第一个节点。因为它是链表的属性,所以应该定义在节点内部类的外面
// 我们创建一个 MySingleLinkedList 类
public class MySingleLinkedList {
//内部类-节点
static class ListNode {
public int val; //数据域
public ListNode next; //地址域
public ListNode(int val) {
this.val = val;
}
}
//链表的头节点
public ListNode head;
}
2.1 创建链表
接着我们可以来创建链表,此处先展示比较简单的方法:创建一个个节点,再按顺序连接起来
问题是,我们要怎么让第一个节点和第二个节点进行关联?
node1.next = node2;
原因:node1 指向的是节点对象,可以使用 . 来访问里面的成员属性 next,node2 引用的是完整的对象,它会存储自己所存储位置的地址
//创建链表
public void createList() {
ListNode node1 = new ListNode(11);
ListNode node2 = new ListNode(22);
ListNode node3 = new ListNode(33);
ListNode node4 = new ListNode(44);
//将前一个节点的 next 赋值为下一个节点的地址
node1.next = node2;
node2.next = node3;
node3.next = node4;
//最后让 head 赋值为第一个节点
this.head = node1;
}
//最后可以使用 head 来引出整个链表
分析:
- 我们创建 node1 到 node4 共四个节点,再将
next赋值为下一个节点的地址。node4 的节点因为没有赋值,默认为 null,标志链表的结尾。最后再将head为赋值 node1 的地址,就完成了最简单的链表创建 - 出了该方法后,因为node 是局部变量,因此它们都会消失,我们就可以使用 head 来引出整个链表
测试:debug 一下
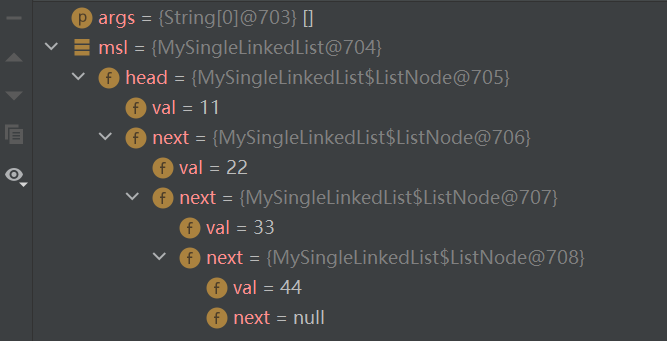
(这是一个比较粗糙的创建链表方法,仅为了方便理解和演示)
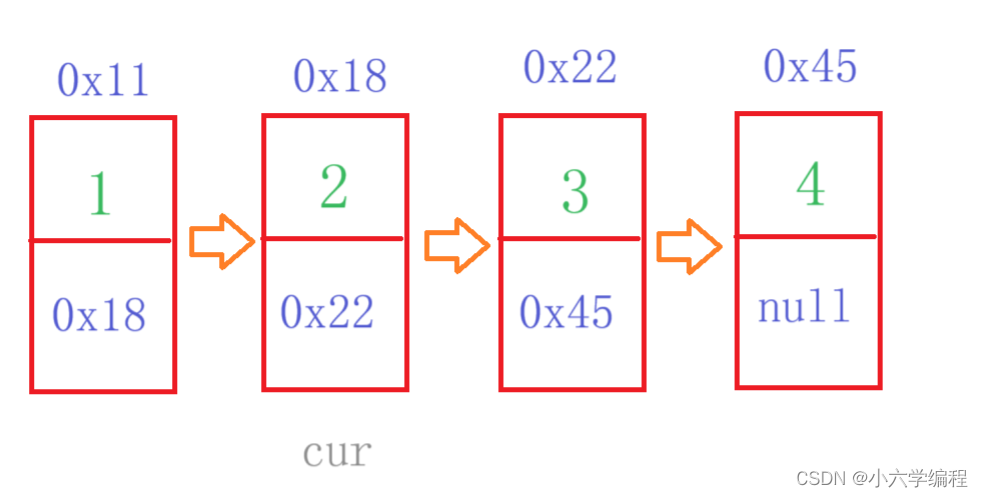
2.2 打印链表
思路:很简单,我们可以让 head 一直往后走,使用 head = head.next 向后遍历,并且当 head == null ,就让循环停下来,表示遍历完成
但是这个方法有一个缺点:即我们只能打印一次,打印完后 head 就变成 null 了,无法再找到该链表。解决方法也很简单,我们设置一个“代理人” cur,打印的时候只让它去往后遍历,head 就还是呆在头节点那里
//打印链表
public void display() {
//代理人cur,防止head跑完后找不到头节点
ListNode cur = head;
while (cur != null) {
System.out.print(cur.val+" ");
cur = cur.next;
}
System.out.println();
}
代码运行结果如下:

2.3 求链表长度
思路:cur + 计数器。跟打印链表基本一样,多加了一个计数器,最后返回计数器的值
//求链表长度
public int size() {
int count = 0;
ListNode cur = head;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}
3. 单向链表常见方法的模拟实现
3.1 头插法
头插法是在链表中插入新节点的方法,新节点总是被插入到链表的头部,即成为链表的第一个节点
实现思路:我们要先实例化一个新的节点 node,拿着这个节点去头插,插入到当前链表头节点的前面,成为新的头节点;具体操作就是先让新节点和后面的节点建立关系 node.next = head,接着 head 要指向当前头插的新节点 head = node(这两步的顺序一定不能颠倒)
//头插节点,也适用于空链表
public void addFirst(int val) {
//先绑后面的节点,再让 head 赋值
ListNode node = new ListNode(val);
node.next = head;
this.head = node;
}
- 该头插法也适用于空链表,因为此时的
head为null,node 的地址域指向null也是正确的 - 时间复杂度为 O(1),在插入节点时不需要遍历整个链表
3.2 尾插法
有头插法,那也应该有尾插法。它是在链表尾部插入新节点的方法,新节点被添加到链表的最后一个节点之后,成为新的最后一个节点
实现思路:还是要先实例化一个新的节点 node,拿着这个节点去尾插;具体操作要先找到链表的尾巴,然后将最后一个节点的 next 赋值为当前要插入节点的地址。而且,尾插需要考虑 head 为空的情况,这个需要单独判断
//后插节点
public void addLast(int val) {
ListNode node = new ListNode(val);
//如果链表为空
if (head == null) {
head = node;
return;
}
//不为空,就正常尾插
ListNode cur = head;
while (cur.next != null) {
cur = cur.next;
}
//找到尾节点了,next 赋值
cur.next = node;
}
- 尾插法需要遍历整个链表以找到最后一个节点,因此时间复杂度为 O(n),其中 n 是链表的长度
- 为了优化尾插法的性能,我们可以在链表结构中维护一个指向最后一个节点的尾指针,这样在插入新节点时可以直接访问到链表的尾部,而不需要遍历整个链表。但是在每次插入或者删除时都需要更新尾指针
3.3 指定位置插入
我们可以在指定位置 index 插入新节点,假设第一个节点的下标为 0,一共有三种情况我们要考虑到
index不合法,即小于 0 或者大于 链表长度,出现这种情况就报错,抛出异常index为 0,我们就可以使用头插法;index为链表长度,我们就可以使用尾插法index合法且不为 0 也不为链表长度,那我们就正常插入:首先要找到index前一个位置的节点,找到后让新节点的next指向后一个节点node.next = cur.next,然后再把前一个节点的next指向要插入的新节点的地址cur.next = node(这两步的顺序一定不能颠倒)
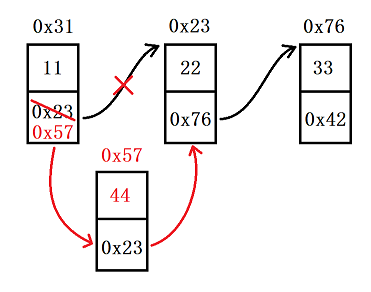
//在 index 位置插入
public void addIndex(int index, int val) {
//1.判断index的合法性
try {
checkIndex(index);
} catch (IndexNotLegalException e) {
e.printStackTrace();
}
//2.考虑 index == 0 || index == length
if (index == 0) {
addFirst(val);
return;
}
if (index == size()){
addLast(val);
return;
}
//3.一切正常就在 index 位置插入
ListNode node = new ListNode(val);
ListNode cur = head;
//找到 index - 1 位置的节点
int count = index - 1;
while (count != 0) {
cur = cur.next;
count--;
}
//让新节点的 next 指向下一个节点,且绑定新节点
node.next = cur.next;
cur.next = node;
}
//判断异常
public class IndexNotLegalException extends RuntimeException{
public IndexNotLegalException() {
}
public IndexNotLegalException(String message) {
super(message);
}
}
- 要创建异常类来判断
index的不合法情况 - 先让新节点绑定后面的节点,再让前一个节点的
next指向新节点的地址**(顺序不能乱)**
3.4 查找值 key 的节点是否在链表中
也是非常简单,使用 cur 直接遍历,再判断 key 等不等于每一个节点的 val 值,如果 val 的类型是引用类型,就得使用 equals 来判断。因为此处演示的 val 的类型为 int,所以就直接 == 判断了
//查找是否存在 key
public boolean contains(int key) {
ListNode cur = head;
while (cur != null) {
if (cur.val == key) {
return true;
}
cur = cur.next;
}
return false;
}
3.5 删除值为 key 的节点
思路:先判断有没有等于 key 的节点,如果没有就直接 return;如果有,那就得找到数据为 key 的前一个节点,如果跳过这个节点,让前一个节点直接连接后一个节点,这时因为 key 节点没有人引用它,就会被直接回收
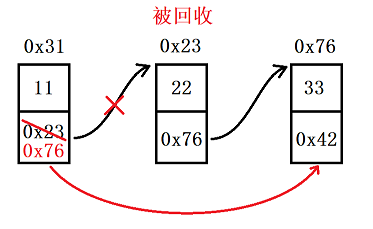
//删除值第一个值为 key 的节点
public void remove(int key) {
//判空
if (head == null) {
return;
}
//判断头节点,如果是,直接让 head 跳到下一个节点
if (head.val == key) {
head = head.next;
return;
}
//正常删除
ListNode cur = head;
//不能使用 cur != null,防止空指针异常
while (cur.next != null) {
//找到了,开始删除
if (cur.next.val == key) {
cur.next = cur.next.next;
return;
}
//继续往后找
cur = cur.next;
}
}
3.6 删除所有值为 key 的节点
上面介绍的操作实际上删除的是第一个值为 key 的节点,此处我们想要的是删除所有值为 key 的节点,思路类似,但方法还是有些不同:我们先创建 cur 用来表示要删除的节点,prev 用来表示 cur 的前驱节点;接着就是让 cur 去找到值为 key 的节点,找到后让 prev 的 next 去指向 cur 的下一个节点,然后 cur 继续往后走;另外头节点需要单独考虑,删除完成后,最后再来判断头节点的值,如果也是 key,那就让 head 往后走
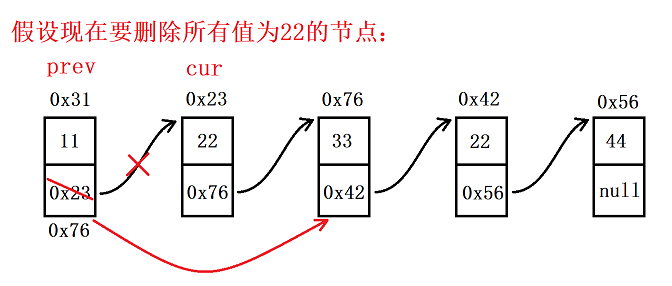
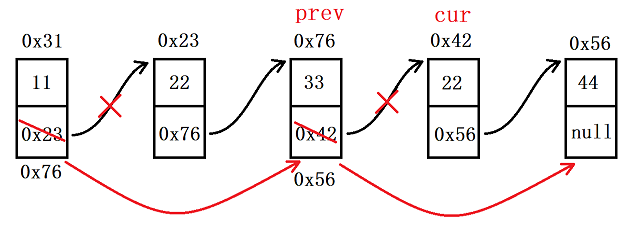
//删除所有值为 key 的节点
public void removeAllVal(int key) {
//判空
if (head == null) {
return;
}
//判断是否相等并删除
ListNode prev = head;
ListNode cur = head.next;
while (cur != null) {
if (cur.val == key) {
prev.next = cur.next;
cur = cur.next;
} else {
prev = cur;
cur = cur.next;
}
}
//判断头节点的值是否为 key
if (head.val == key) {
head = head.next;
}
}
3.7 清空链表
清空链表很简单,我们可以直接让 head = null ,这样链表中的所有节点都会被回收,因而被清空;麻烦点的话也可以遍历链表一个个置为 null,
//清空链表(简单版)
public void clear1() {
head = null;
}
//清空链表(复杂版)
public void clear2() {
ListNode cur = head;
while(cur != null) {
ListNOde curN = cur.next;
cur.next = null;
cur = curN;
}
head = null;
}
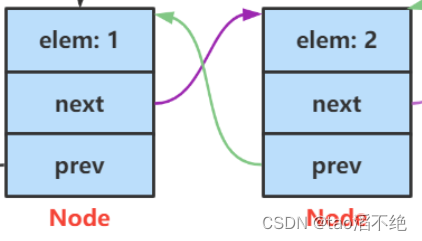
4. 双向链表的模拟实现
请注意,以下的链表默认为 无头双向非循环
上面讲完了单向链表,这里我们再来讲一下双向链表,因为在集合里中的 LinkedList 类的底层就是双向链表,我们来看一下它长什么样
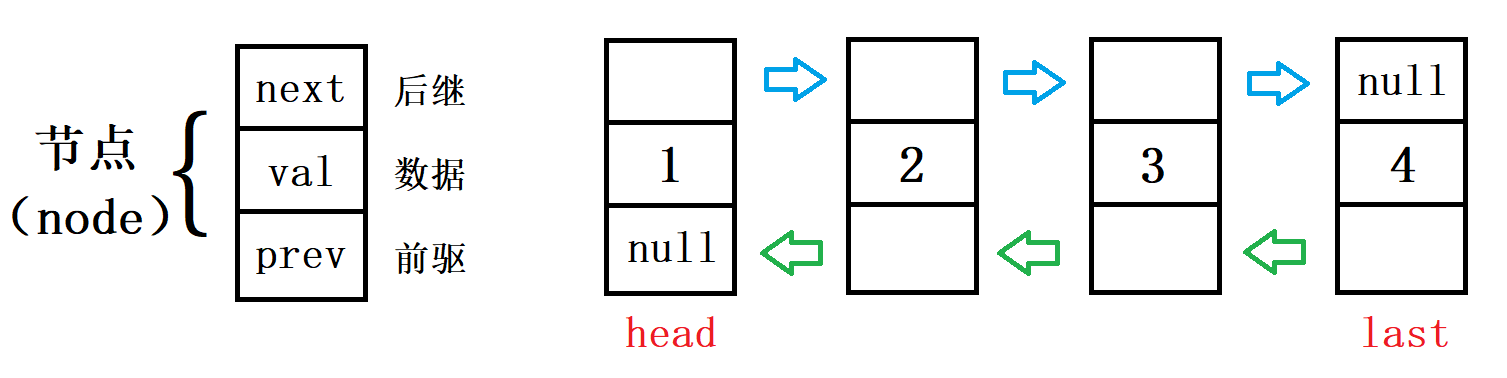
与单向链表的区别在于它不仅有后继节点,还有前驱节点,可以找到前一个节点。而且为了方便从后往前遍历,我们使用 last 来标记最后一个节点
public class MyLinkedList {
static class ListNode {
public int val;
public ListNode prev;//前驱
public ListNode next;//后继
public ListNode(int val) {
this.val = val;
}
}
public ListNode head;//标志头节点
public ListNode last;//标志尾节点
}
因为无论单向还是双向链表,在求链表的长度,打印链表,还是查找值 key 的节点是否在链表中这三种方法都是一样的,双向链表这博主就略过了
5. 双向链表常见方法的模拟实现
5.1 头插法
实现思路:首先创建一个新节点,然后让头节点的 prev 赋值为新节点的地址,接着让新节点的 next 指向头节点,最后把 head 赋值为新节点的地址。但是我们还是要考虑空链表的情况
//头插法
public void addFirst(int val) {
ListNode node = new ListNode(val);
//空链表,直接让 head 和 last 等于 node
if (head == null) {
head = last = node;
} else {
//开始绑定,注意顺序不能随意调换
node.next = head;
head.prev = node;
head = node;
}
}
5.2 尾插法
实现思路:跟头插法很类似,就是绑定的时候顺序不能乱,也是要判空
//尾插法
public void addLast(int val) {
ListNode node = new ListNode(val);
//空链表,直接让 head 和 last 等于 node
if (head == null) {
head = last = node;
} else {
//绑定
last.next = node;
node.prev = last;
last = node;
}
}
5.3 指定位置插入
实现思路:因为在双向链表中,我们可以找到前一个节点,所以就让 cur 直接走到要插入的位置 index,接下来就是绑定了。一共要改变四个地方,顺序什么的不能搞乱了
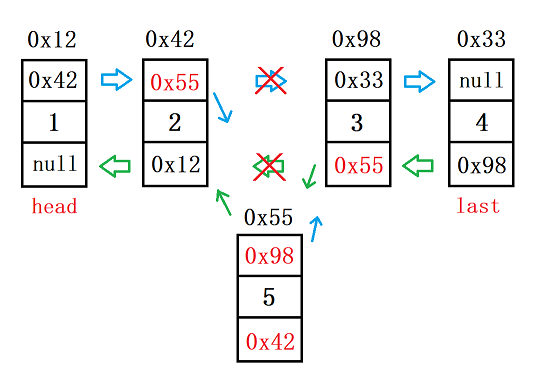
//在 index 位置前插入 key,且第一个数据节点下标为 0
public void addIndex(int index, int key) {
//index 的值不合法
try {
checkIndex(index);
} catch (Exception e) {
e.printStackTrace();
}
//如果为0,就是头插
if (index == 0) {
addFirst(key);
return;
}
//如果是链表的长度,就是尾插
if (index == size()) {
addLast(key);
return;
}
//找到要插入位置的那个节点
ListNode cur = findIndex(index); //简单遍历就行
ListNode node = new ListNode(key);
cur.prev.next = node;
node.prev = cur.prev;
node.next = cur;
cur.prev = node;
}
5.4 删除值为 key 的节点
实现思路:想要删除,我们必须先遍历一遍链表,使用 cur 从头到尾找一遍。找到后就让当前节点 cur 的前一个节点的后继连上下一个节点,下一个节点的前驱连接前一个节点 cur.prev.next = cur.next 和 cur.next.prev = cur.prev。但是我们还要考虑特殊情况,如要删的是头节点或尾节点,链表只有一个节点或者空链表的情况
//删除第一个值为 key 的节点
public void remove(int key) {
ListNode cur = head;
while (cur != null) {
if (cur.val == key) {
//如果是头节点
if (cur == head) {
head = head.next;
//如果链表仅有一个节点
if (head == null) {
//让 last 也变为 null
last = null;
} else {
//让新的头节点的前驱为 null
head.prev = null;
}
} else {
//前面的连上后面的
cur.prev.next = cur.next;
if (cur.next == null) {
//如果是尾节点
last = last.prev;
} else {
//后面的接上前面的
cur.next.prev = cur.prev;
}
}
//找到一个删除完就 return
return;
}
//一直往后走
cur = cur.next;
}
}
- 在删完节点后,记得及时
return - 关于删头节点和尾节点那部分有点绕,
if - else太多了(如果有大佬能有更简洁的思路,欢迎评论区留言)
5.5 删除所有值为 key 的节点
实现思路:很简单,我们可以直接使用上面的代码,然后把 return 去掉,这样就能遍历完链表上的所有节点,删去所有值为 key 的节点,最后遍历到结尾,就能自然结束方法
//删除所有值为 key 的节点
public void removeAll(int key) {
ListNode cur = head;
while (cur != null) {
if (cur.val == key) {
//如果是头节点
if (cur == head) {
head = head.next;
//如果链表仅有一个节点
if (head == null) {
//让 last 也变为 null
last = null;
} else {
//让新的头节点的前驱为 null
head.prev = null;
}
} else {
//前面的连上后面的
cur.prev.next = cur.next;
if (cur.next == null) {
//如果是尾节点
last = last.prev;
} else {
//后面的接上前面的
cur.next.prev = cur.prev;
}
}
//找到一个删除完就 return
//return;
}
//一直往后走
cur = cur.next;
}
}
5.6 清空链表
实现思路:跟上面一样,将一个个节点置为 null 也行,一次性 head = last = null 也行
//清空链表(简单版)
public void clear1() {
head = last = null;
}
//清空链表(复杂版)
public void clear2() {
ListNode cur = head;
while(cur != null) {
ListNOde curN = cur.next;
cur.prev = null;
cur.next = null;
cur = curN;
}
head = last = null;
}
6. LinkedList 常见方法的使用
LinkedList 是采用双向循环链表实现,LinkedList 是 List 接口的另一个实现。除了可以根据索引访问集合元素外,LinkedList 还实现了 Deque 接口,可以当作双端队列来使用,也就是说,既可以当作“栈”使用,又可以当作队列使用
6.1 构造方法
| 方法 | 介绍 |
|---|---|
| LinkedList( ) | 无参构造器 |
| public LinkedList(Collection<? extends E> c) | 一个包含指定集合元素的构造器 |
LinkedList<String> list = new LinkedList<>();
Collection<String> elements = ...; // 已有的集合(必须是E或者E的子类)
LinkedList<String> list = new LinkedList<>(elements);
//演示1
List<Integer> list = new LinkedList<>(); //平时创建链表的方式
//演示2
List<Integer> list = new LinkedList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
List<Integer> list1 = new LinkedList<>(list);
System.out.println(list1.toString());
6.2 常见方法
| 方法 | 介绍 |
|---|---|
| boolean add(E e) | 尾插元素 e |
| void add(int index, E e) | 在位置为 index 上插入 e(注意,头节点位置为 0) |
| void addAll(Collection<? extends E> c) | 尾插一个集合 c 中的所有元素 |
| E get(int index) | 获取下标 index 位置的元素 |
| E set(int index, E element) | 将下标 index 的元素改成 element |
| boolean remove(Object o) | 删除第一个元素 o |
| E remove(int index) | 删除 index 位置的元素 |
| boolean contains(Object o) | 判断 o 是否在线性表中 |
| void clear( ) | 清空链表 |
| int size( ) | 得到链表大小 |
- 关于这些方法知道就好,常用的方法就这么一些,如果忘记了就查查文档,不需要死记硬背
6.3 遍历 LinkedList
直接打印,因为 LinkedList 重写了 toString
List<Integer> list = new LinkedList<>(); list.add(1); list.add(2); list.add(3); list.add(4); list.add(5); System.out.println(list.toString());for-each 遍历
for (Integer x : list) { System.out.print(x + " "); } System.out.println();迭代器打印
//创建迭代器 ListIterator<Integer> iterator = list.listIterator(); while (iterator.hasNext()) { System.out.print(iterator.next() + " "); } System.out.println();反向迭代器打印
ListIterator<Integer> rit = list.listIterator(list.size()); while (rit.hasPrevious()) { System.out.print(rit.previous() + " "); } System.out.println();
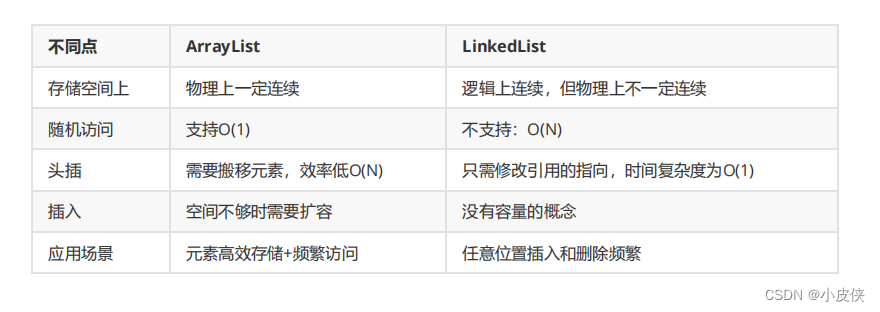
7. ArrayList 和 LinkedList 的区别
| 不同点 | ArrayList | LinkedList |
|---|---|---|
| 底层结构 | 动态数组 | 双向链表 |
| 存储空间 | 逻辑和物理上都连续 | 逻辑上连续,物理上不一定连续 |
| 访问性能 | 支持随机访问:O(1) | 不支持随机访问:O(n) |
| 插入/删除性能 | 需要移动元素,效率低 | 直接改变节点的链接,效率高 |
| 内存机制 | 超出了初始容量需要扩容 | 可以动态扩容 |
| 使用场景 | 频繁随机访问元素 | 大量插入删除元素 |
ArrayList 和 LinkedList 在很多方面都不相同,各有优劣,我们还是要根据实际的应用场景来选择合适的顺序表
结语
今天我们讲了链表中的单向和双向链表,关于它们的方法机制以及方法的使用需要十分熟练地掌握,最后我们还比较了一下 ArrayList 和 LinkedList 的区别,使用哪种还是要具体的使用场景~
希望大家能够喜欢本篇博客,有总结不到位的地方还请多多谅解。若有纰漏,希望大佬们能够在私信或评论区指正,博主会及时改正,共同进步!