前言
本文树剖默认重链剖分,默认读者了解树剖,没有具体讲解与证明,主要记录个人疑惑。
oiwiki中有写到 将整棵树剖分为若干条链,使它组合成线性结构,然后用其他的数据结构维护信息。
为什么需要这么做?这么做带来了什么好处?剖成链之后又怎么处理?
为什么需要树剖
在树上批量修改节点以及批量查询的时候,通过暴力效率非常低。如果是一个线性的数组,我们会用线段树等数据结构来处理。
那有没有方法,把树转换成一个线性的结构来操作呢?树剖就是这样的方法,把一个数剖成了多条线性的链。
同时,重链的使用保证了优秀的时间复杂度。
为什么可以树剖
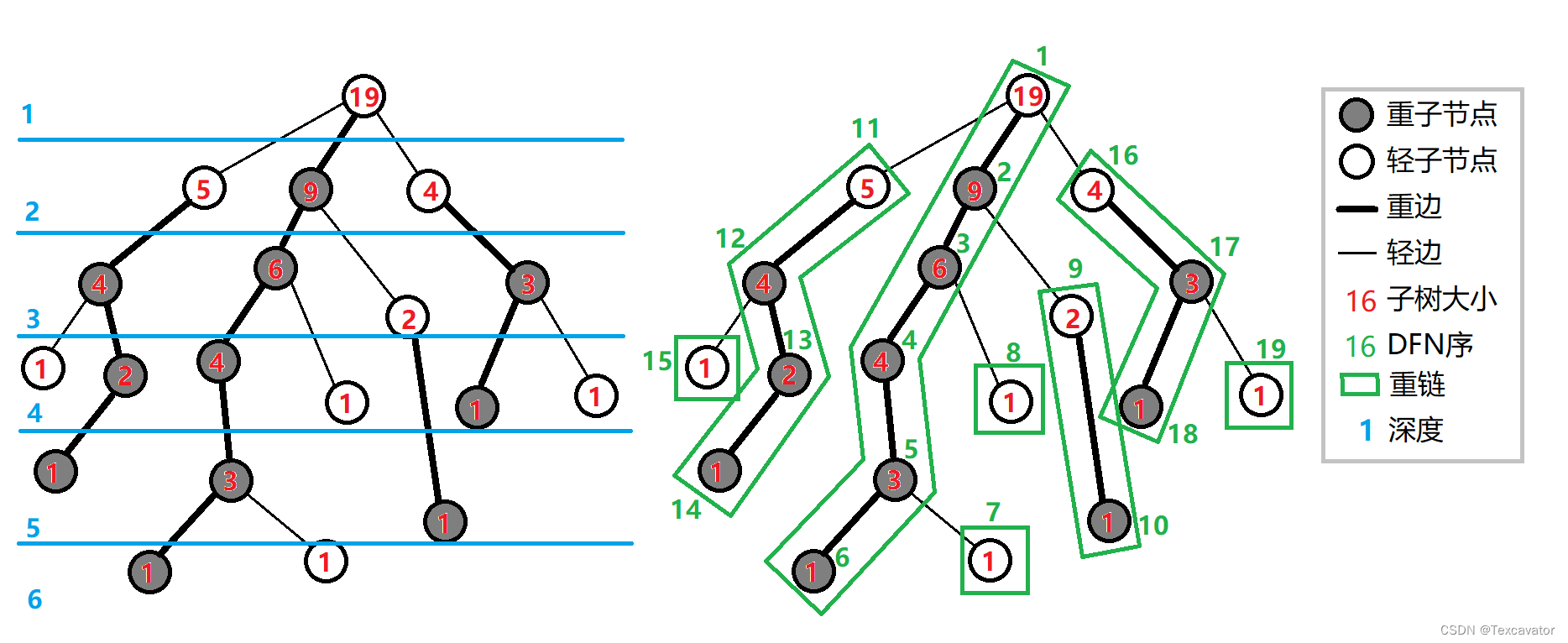
整个剖分的过程是一个dfs,声音是满足dfs序的。如果你构造时间戳就会发现,重链编号连续,某节点的所有子节点编号连续。
换句话说,就是你剖分出来的每一条链,都可以换成一段连续的数组。所有的链放一起,就是一个线性的数组了。
如何处理树剖
在剖分完之后,原来的树有了一个时间戳。每个节点对应的时间就是新的数组编号。只需用线段树等便于区修区查的数据结构维护这个数组即可。
但是还有个问题,如何快速通过原来的树节点,对应得到对应的数组编号呢?
假设现在修改的是x-y的最短路径的所有节点。
如果x,y在同一条重链,直接修改x-y即可(因为重链编号连续)。
如果不在,就通过lca的方法,把x和y跳到一条重链,然后修改id[x]-id[y]。但这个过程中,我们还需要一些处理。比如x跳到了lca(x),id[lca(x)] - id[x]的区间也需要修改。(也就是修改经过的节点)。
void update_path(int x, int y, int d){
while(top[x] != top[y]){ //lca过程
if(deep[top[x]] < deep[top[y]]) swap(x, y);
update(1, 1, n, id[top[x]], id[x], d);
x = fa[top[x]];
}
if(deep[x] > deep[y]) swap(x, y); //同一条链之后
update(1, 1, n, id[x], id[y], d);
}
总结
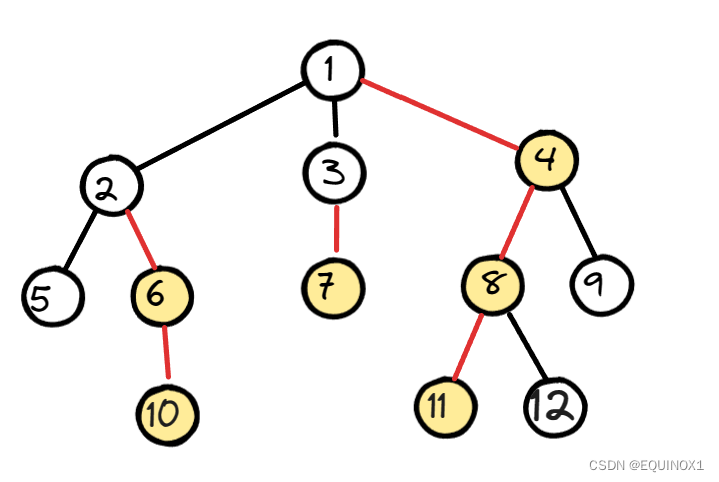
树剖看着难,其实只是一些简单的方法堆砌,核心部分就是剖分。总结就两点:通过重链设置加速lca,利用dfs序进行区间处理。

![[蓝桥杯学习] <span style='color:red;'>树</span><span style='color:red;'>链</span><span style='color:red;'>剖</span><span style='color:red;'>分</span>](https://img-blog.csdnimg.cn/direct/97ba6d4a2e08425d9519dbfe397dcb9b.png)