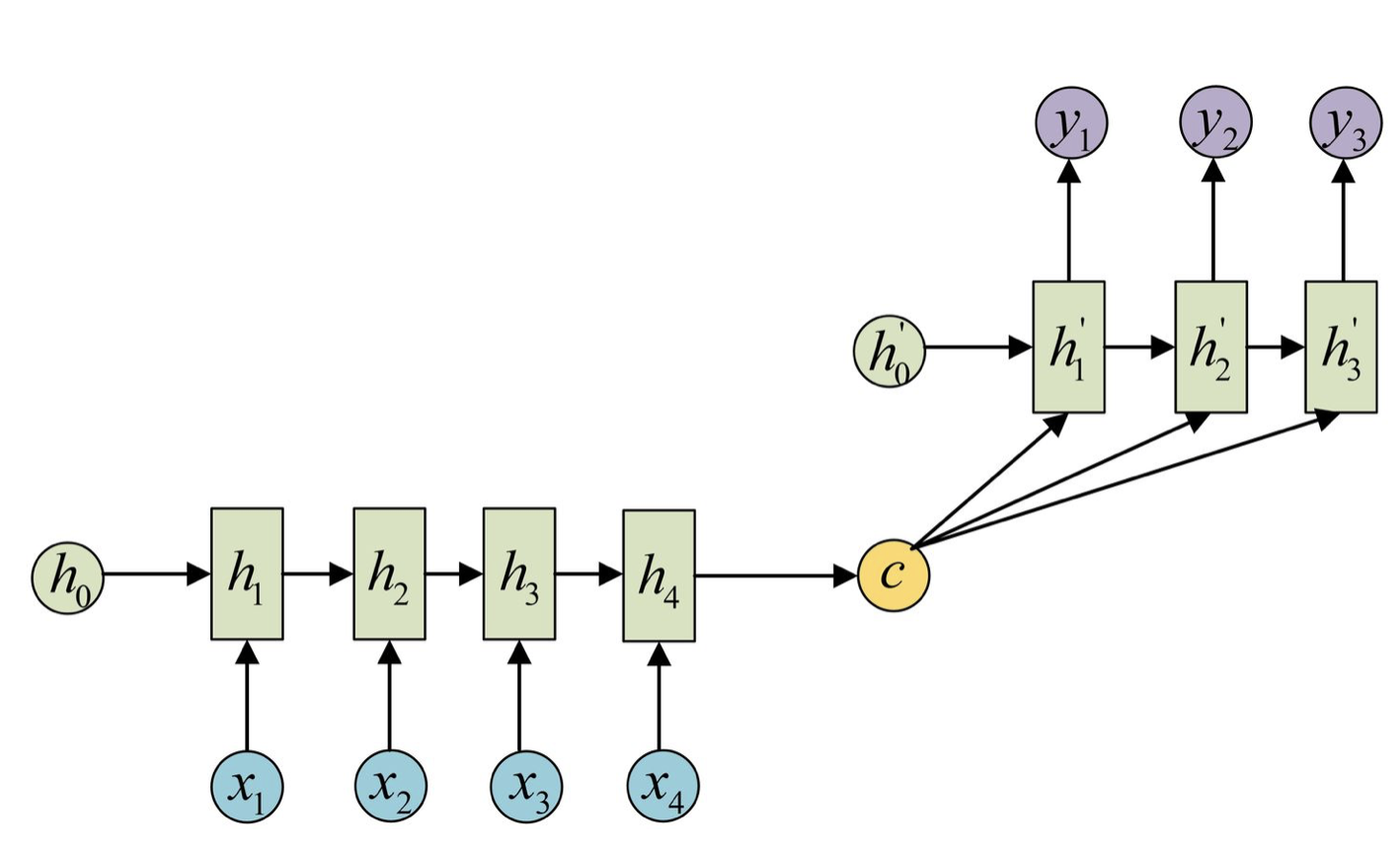
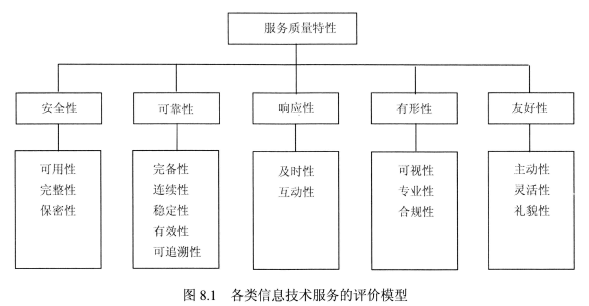
1. Kylin介绍
Apache Kylin是一个开源的、分布式的分析型数据仓库,它提供在Hadoop/Spark之上的SQL查询接口以及多维分析(OLAP)能力,用于支持超大规模数据。最初由eBay开发并贡献至开源社区。Kylin特别适用于大数据环境,能够通过其预计算技术,将大数据的 SQL 查询速度提升到亚秒级别,相比传统查询速度有显著提升。更多详细信息,可以参考Apache Kylin官网。
Apache Kylin 主要是通过 SQL 来进行数据查询的,其基础语法与标准的SQL语法非常相似。以下是一些在 Kylin 中使用的 SQL 基础语法示例:
1.1 查询数据
SELECT column1, column2, ...
FROM table_name
WHERE condition;
例如,查询销售事实表中特定日期的销售总额:
SELECT SUM(sales_amount) AS total_sales
FROM sales_fact
WHERE sale_date = '2023-01-01';
1.2 聚合函数
Kylin支持各种聚合函数,如SUM, COUNT, AVG, MAX, MIN等。
SELECT COUNT(*) AS total_count, SUM(sales_amount) AS total_sales
FROM sales_fact;
1.3 分组
使用GROUP BY语句可以对数据进行分组。
SELECT region, SUM(sales_amount) AS total_sales
FROM sales_fact
GROUP BY region;
1.4 排序
使用ORDER BY语句可以对查询结果进行排序。
SELECT product_category, SUM(sales_amount) AS total_sales
FROM sales_fact
GROUP BY product_category
ORDER BY total_sales DESC;
1.5 连接
Kylin支持多种类型的连接,包括INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL OUTER JOIN。
SELECT a.column1, b.column2
FROM table1 a
INNER JOIN table2 b ON a.id = b.id;
1.6 子查询
可以在WHERE或FROM子句中使用子查询。
SELECT column1, column2
FROM table_name
WHERE column1 IN (SELECT column1 FROM another_table);
1.7 Exists和Not Exists
使用EXISTS和NOT EXISTS进行子查询,判断记录是否存在。
SELECT column1, column2
FROM table_name
WHERE EXISTS (SELECT 1 FROM another_table WHERE another_table.column1 = table_name.column1);
1.8 Limit
使用LIMIT限制返回的记录数。
SELECT *
FROM table_name
LIMIT 10;
注意事项
- Kylin的 SQL 查询是基于预计算好的 Cube,因此并不是所有的 SQL 语法都支持。
- 在执行查询之前,需要确保相应的 Cube 已经被正确构建。
- 查询性能很大程度上取决于 Cube 的设计和优化。
以上是 Kylin 中一些基础的 SQL 语法用法,实际使用时,可能还需要根据具体的业务需求和 Kylin 的版本特性进行相应的调整。
2. 使用 Kylin 进行性能优化
使用 Apache Kylin 进行性能优化时,可以考虑以下几个方面:
- 合理设计Cube:
- 选择合适的维度和度量。
- 合理设置Cube的聚合组,避免不必要的聚合。
- 使用必要的Cube修剪策略,如排除不必要的历史数据。
- 优化数据模型:
- 确保星型模式或雪花模式的合理性,减少复杂join操作。
- 使用衍生维度(Derived Dimensions)减少维度数量。
- 调整系统配置:
- 优化Hadoop和HBase的配置,以适应Kylin的工作负载。
- 增加HBase的region服务器和内存配置,以提高查询响应速度。
- 查询优化:
- 避免使用SELECT *,只查询需要的列。
- 使用限制条件(WHERE子句)减少查询数据量。
- 利用缓存机制,对频繁查询的结果进行缓存。
- 监控和维护:
- 定期监控Kylin的性能指标,如查询延迟、系统负载等。
- 定期进行Cube的重建和合并,以维持查询性能。
- 资源管理:
- 根据查询负载动态调整资源,如增加计算资源以加快Cube构建速度。
- 使用资源队列管理不同优先级的查询任务。
- 使用最新版本:
- 关注Kylin的版本更新,使用最新版本以获得性能改进和bug修复。
这些优化技巧需要根据具体的使用场景和数据特点进行适当调整。在实际应用中,可能还需要结合具体的业务需求和系统环境进行更细致的优化。
- 关注Kylin的版本更新,使用最新版本以获得性能改进和bug修复。
3. 如何设置 Cube
设置 Cube 的聚合组是 Apache Kylin 中优化 Cube 结构的重要步骤。合理的聚合组设置可以减少Cube的存储空间,提高查询性能。以下是一些设置聚合组的建议:
- 理解聚合组的概念:
- 聚合组是一组维度的集合,这些维度在查询中经常一起出现。
- 在构建Cube时,每个聚合组都会生成一组基础立方体(base cuboid),其他所有立方体都可以通过这些基础立方体计算得出。
- 识别常用维度组合:
- 分析历史查询模式,找出经常一起出现的维度组合。
- 将这些常用的维度组合设置为一个聚合组。
- 合并维度:
- 如果某些维度在查询中总是同时出现,可以将它们合并为一个聚合组。
- 这可以减少Cube中存储的立方体数量,从而减少存储空间和提高查询速度。
- 排除不常用维度:
- 对于不经常一起查询的维度,不要将它们放在同一个聚合组中。
- 可以单独设置聚合组或将它们与其他维度组合,以减少不必要的计算和存储。
- 使用星型模式:
- 在设计聚合组时,利用星型模式的特点,将事实表和维度表的关系考虑进去。
- 通常,与事实表直接关联的维度应该放在同一个聚合组中。
- 设置聚合组的高级属性:
- 使用“强制聚合组”(Mandatory)属性确保某些维度总是包含在聚合组中。
- 使用“层次结构”(Hierarchy)属性定义维度之间的层次关系,这有助于优化Cube的构建和查询。
- 测试和调整:
- 在设置聚合组后,进行测试以验证查询性能是否有所提升。
- 根据测试结果调整聚合组设置,以达到最佳性能。
以下是一个设置聚合组的简单示例:
-- 假设我们有一个销售事实表,维度包括时间、地区、产品类别和销售渠道 -- 创建聚合组 CREATE AGGREGATION GROUP ON ( time_dim, region_dim ) INCLUDE ( product_category_dim, sales_channel_dim )
在这个例子中,time_dim和region_dim是经常一起查询的维度,因此它们被放在同一个聚合组中。product_category_dim和sales_channel_dim则是根据实际情况可能被包含在查询中的维度,因此它们被添加到聚合组中,但不是强制性的。
记住,合理的聚合组设置需要根据实际的业务需求和查询模式来定制,因此上述建议需要根据具体情况灵活应用。
4. 在 Kylin 中实现数据的安全访问
在 Apache Kylin 中实现数据的安全访问涉及多个层面,以下是一些关键措施:
- 用户认证:
- 集成LDAP/AD:Kylin 可以与
LDAP(轻量级目录访问协议)或Active Directory集成,使用现有的企业用户目录进行认证。 - 集成SSO(单点登录):通过集成
SSO解决方案,如OAuth、SAML等,实现用户身份的统一认证。
- 集成LDAP/AD:Kylin 可以与
- 用户授权:
- 角色和权限管理:在Kylin中,可以为用户分配不同的角色,如管理员、开发者、分析师等,每个角色有不同的权限。
- 项目级别权限:可以为用户或角色设置项目级别的权限,如查询、编辑 Cube、管理项目等。
- 数据访问控制:
- 行级过滤:通过配置行级过滤规则,可以限制用户只能查询到他们有权限查看的数据。
- 列级安全:可以为用户或角色设置列级权限,限制对敏感列的访问。
- 安全配置:
- Kylin配置文件:在
kylin.properties配置文件中设置安全相关的参数,如启用HTTPS、设置密码加密等。 - Kylin Web界面:在 Kylin 的 Web 界面中配置用户和角色权限。
以下是一些具体步骤来实现数据的安全访问:
- Kylin配置文件:在
集成LDAP/AD进行用户认证:
- 在
kylin.properties中配置 LDAP/AD 的连接信息:kylin.security.profile=ldap kylin.ldap.connection-string=ldap://ldap-server:389 kylin.ldap.user-search-base=dc=example,dc=com kylin.ldap.user-search-pattern=(uid={0}) - 重启Kylin服务以应用配置。
配置行级过滤:
- 在Cube的“高级设置”中,为需要过滤的表设置“行级过滤”。
- 输入过滤条件,例如:
DIM_TABLE.COLUMN = 'ALLOWED_VALUE'。
配置列级安全:
- 在 Kylin 的 Web 界面中,进入“系统”设置,然后选择“列级安全”。
- 为每个项目设置列级权限,指定哪些用户或角色可以访问哪些列。
管理用户和角色权限:
- 在 Kylin 的 Web 界面中,进入“管理员”控制台。
- 创建用户和角色,并为它们分配相应的权限。
通过上述措施,可以有效地在 Apache Kylin 中实现数据的安全访问。需要注意的是,安全策略应该根据组织的具体需求和政策来定制,并定期审查和更新以确保持续的安全性。