现在来看下面的代码:
#include <stdio.h>
#include <list>
#include <set>
#include <algorithm>
using namespace std;
template <class S>
void ls(S *s)
{
typename S::iterator it;
it = s->begin();
printf("{ ");
while (it!=s->end()) {
int n= *it;
printf("%d ", n);
++it;
}
printf("}\n");
}
int main()
{
int i;
int n;
list<int> l;
set<int> s;
for(i=0; i<10; i++) {
l.push_back(i);
}
for(i=0; i<10; i++) {
s.insert(i);
}
ls(&l);
ls(&s);
list<int>::iterator li;
set<int>::iterator si;
li = find(l.begin(), l.end(), 9);
if(li!=l.end()) printf("%d\n", *li);
si = s.find(9);
if(si!=s.end()) printf("%d\n", *si);
return 0;
}
一个是int的list容器,一个是int的set容器。由于接口的高度相似性,究竟用哪个好,对写代码的开发者来说,几乎无感。把代码交给容器,似乎就此失去控制了。“从代码上根本看不出来”,“但用set检索的效率更高”,听到人们私下里轻轻的说。
如果不想装入大量的数据,执行数十万,数百万的检索进行比较,那么怎么知道用set检索的效率更高呢。
有办法的。还可以用容器强制类型转换这种方法。对于容器的一个参数数据类型T,这里是int,可以对它重载一个2进制内容完全一样的 wrap_T,拦截它的构造函数,析构函数,赋值,比较等接口函数,就可以抓到它的运行轨迹。 wrap_T,这里是原样包装起来的interger类型:
struct integer {
int x;
integer(int n) {x=n;}
~integer() { printf("~ %d\n", x); }
bool operator<(const struct integer &r) const {
printf("{%d.%d} ", x, r.x);
if(x<r.x) return true;
return false;
}
bool operator==(const struct integer &r) const {
printf("%d. ", x);
if(x==r.x) return true;
return false;
}
};
现在就可以看到它们的不同了:
#define TYPE integer
struct Predict {
TYPE t;
Predict(int n):t(n){}
Predict(const Predict &p):t(p.t){printf("copy constructor\n");}
bool operator()(const TYPE &v) {
printf("%d ", v.x);
if(t==v) return true;
return false;
}
};
template <class S>
typename S::iterator find2(S *s, Predict &p)
{
typename S::iterator si;
S &t= *s;
si= find_if(t.begin(), t.end(), p);
printf("\n");
return si;
}
int main()
{
int i;
int n;
list<int> l;
set<int> s;
for(i=0; i<10; i++) {
l.push_back(i);
}
for(i=0; i<10; i++) {
s.insert(i);
}
ls(&l);
ls(&s);
list<int>::iterator li;
set<int>::iterator si;
li = find(l.begin(), l.end(), 9);
if(li!=l.end()) printf("%d\n", *li);
si = s.find(9);
if(si!=s.end()) printf("%d\n", *si);
Predict p(9);
((list<TYPE>::iterator&)li) =find2((list<TYPE>*)&l, p);
if(li!=l.end()) printf("%d\n", *li);
(set<TYPE>::iterator&)si = ((set<TYPE>&)s).find(TYPE(9));
if(si!=s.end()) printf("%d\n", *si);
return 0;
}
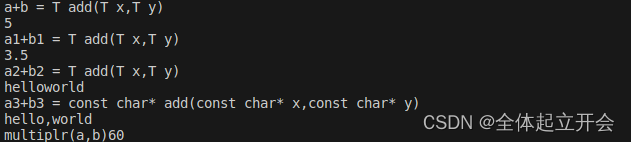
运行结果是:
{ 0 1 2 3 4 5 6 7 8 9 }
{ 0 1 2 3 4 5 6 7 8 9 }
9
9
copy constructor
copy constructor
0 9. 1 9. 2 9. 3 9. 4 9. 5 9. 6 9. 7 9. 8 9. 9 9. ~ 9
~ 9
9
{3.9} {5.9} {7.9} {8.9} {9.9} {9.9} ~ 9
9
~ 9
这里用了两组强制类型转换,把int的容器,直接当作类型integer的容器来看了:因为integer是int的原样包装,它们在2进制上没有任何不同,也就是说,在运行期没有任何不同,这样转换当然是可以的。转换后自动利用重载的函数输出list的find算法和set的find()方法的比较轨迹。
list的find算法搜索整个容器逐个数据比较;set的find()方法只比较了一个子集。因此set的检索比较快。list的find用了operator==比较,(Predict让它用的),set的find()方法用了less比较,a<b和b<a都不成立,于是就找到了。所以set的find()中最后9和9比较了2次。此外,list的find中的 Predict是值传递的,find_if模板内部又调用了实际操作的__find_if,所以 Predict被复制传递了2次。
最后,值得一提的是,如果Predict中省略了比较,而始终返回false,搜索就变成了遍历。这个例子中,自己写了iterator遍历打印所有元素的ls。也可以不写,懒就直接用标准库的find_if:
struct Predict2 {
bool operator()(int v) {
printf("%d ", v);
return false;
}
};
template <class S>
void ls2(S *s)
{
S &t= *s;
printf("{ ");
find_if(t.begin(), t.end(), Predict2());
printf("}\n");
}