nn 包提供通用深度学习网络的模块集合,接收输入张量,计算输出张量,并保存权重。通常使用两种途径搭建 PyTorch 中的模型:nn.Sequential和 nn.Module。
nn.Sequential通过线性层有序组合搭建模型;nn.Module通过__init__ 函数指定层,然后通过 forward 函数将层应用于输入,更灵活地构建自定义模型。
目录
搭建线性层
使用 nn 包搭建线性层。线性层接收 64*1000 维的输入,保存 1000*100 维的权重,并计算 64*100 维的输出。
import torch
input_tensor = torch.randn(64, 1000)
linear_layer = nn.Linear(1000, 100)
output = linear_layer(input_tensor)
print(input_tensor.size())
print(output.size())
通过nn.Sequential搭建
考虑一个两层的神经网络,四个节点作为输入,五个节点在隐藏层,一个节点作为输出

from torch import nn
model = nn.Sequential(
nn.Linear(4, 5),
nn.ReLU(),
nn.Linear(5, 1),
)
print(model)
通过nn.Module搭建
在 PyTorch 中搭建模型的另一种方法是对 nn.Module 类进行子类化,通过__init__ 函数指定层,然后通过 forward 函数将层应用于输入,更灵活地构建自定义模型。
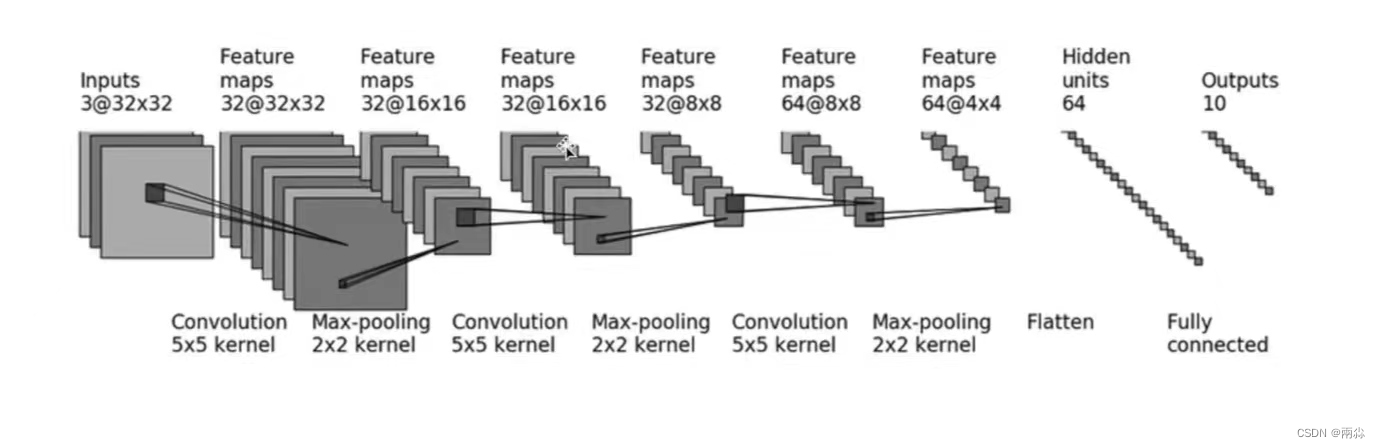
考虑两个卷积层和两个完全连接层搭建的模型:

import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
def forward(self, x):
pass定义__init__ 函数和forward 函数
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5, 1)
self.conv2 = nn.Conv2d(20, 50, 5, 1)
self.fc1 = nn.Linear(4*4*50, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4*4*50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)重写两个类函数并打印模型
重写:子类中实现一个与父类的成员函数原型完全相同的函数
Net.__init__ = __init__
Net.forward = forward
model = Net()
print(model)
查看模型位置
print(next(model.parameters()).device) 
将模型移动至CUDA设备
device = torch.device("cuda:0")
model.to(device)
print(next(model.parameters()).device)
获取模型摘要
借助torchsummary包查获取模型摘要
pip install torchsummaryfrom torchsummary import summary
summary(model, input_size=(1, 28, 28))

![[pytorch] 7. <span style='color:red;'>神经</span><span style='color:red;'>网络</span><span style='color:red;'>搭</span><span style='color:red;'>建</span>实例](https://img-blog.csdnimg.cn/direct/85c28e9b9abc403c8c41d73735ef8696.png)