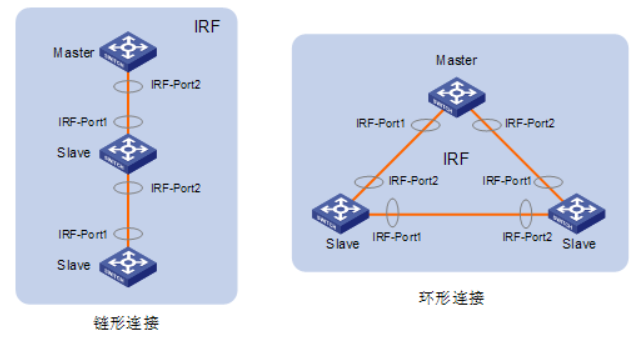
在Python中分析PDF文件信息,你可以使用多个库。以下是一些流行的Python库,它们可以帮助你处理和分析PDF文件:
PyPDF2:
PyPDF2是一个流行的Python库,用于从PDF文件中提取文本、合并PDF文件、拆分PDF文件等。你可以使用它来读取PDF文件并提取其中的文本内容。安装:
pip install PyPDF2使用示例:
import PyPDF2 pdf_file_path = 'example.pdf' pdf_file_obj = open(pdf_file_path, 'rb') pdf_reader = PyPDF2.PdfFileReader(pdf_file_obj) num_pages = pdf_reader.numPages page_text = "" for page in range(num_pages): page_obj = pdf_reader.getPage(page) page_text += page_obj.extractText() print(page_text) pdf_file_obj.close()PDFMiner:
PDFMiner是一个用于从PDF文档中提取和处理文本的库。与PyPDF2相比,PDFMiner在处理包含复杂布局和字体的PDF文件时可能更加准确。安装:
pip install pdfminer.six(注意:pdfminer.six是PDFMiner的Python 3版本)使用示例:
from pdfminer.high_level import extract_text text = extract_text('example.pdf') print(text)Pdfplumber:
Pdfplumber是一个可以方便地处理PDF的Python库,不仅可以提取文本,还可以提取图像、表格等信息,并提供可视化的调试工具。安装:
pip install pdfplumber使用示例:
import pdfplumber with pdfplumber.open('example.pdf') as pdf: first_page = pdf.pages[0] print(first_page.extract_text())PyMuPDF(也称为fitz):
PyMuPDF是一个功能强大的PDF处理库,支持渲染PDF页面、提取文本和图像、修改PDF文件等。安装:
pip install pymupdf使用示例:
import fitz # PyMuPDF doc = fitz.open('example.pdf') for page_num in range(len(doc)): page = doc[page_num] text = page.get_text() print(text)pdf2image 和 OCR:
如果你需要处理的是包含图像或者扫描版的PDF文件,你可能需要将PDF页面转换为图像,并使用OCR(光学字符识别)技术来提取文本。pdf2image库可以将PDF转换为图像,而pytesseract(Tesseract OCR的Python接口)可以用来识别图像中的文本。安装:
pip install pdf2image pytesseract(还需要安装Tesseract OCR引擎)使用示例(转换PDF为图像后使用OCR提取文本):
from pdf2image import convert_from_path import pytesseract from PIL import Image images = convert_from_path('example.pdf') for image in images: text = pytesseract.image_to_string(image) print(text)
根据你的具体需求(如只需提取文本、需要处理图像PDF等),你可以选择适合的库来完成任务。