文章目录
-
- GPT关于3D-GS的回答
- MVSplat论文
- 三维重建——3D Gaussian Splatting
- 3D高斯可能并不是3D模型
- 三维重建——occupancy network类的
- 三维重建——voxel模型类
-
- A Voxel Generator Based on Autoencoder
- 3D Shape Generation and Completion through Point-Voxel Diffusion
- Image-to-Voxel Model Translation for 3D Scene Reconstruction and Segmentation
- TMVNet : Using Transformers for Multi-view Voxel-based 3D Reconstruction
- VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion
- 以上都是单目的
- 多视角 Multi-view Stereo
- Scan2CAD: Learning CAD Model Alignment in RGB-D Scans
- Robust Attentional Aggregation of Deep Feature Sets for Multi-view 3D Reconstruction
- 背景干净的图片生成3D模型
- Pix2Vox++: Multi-scale Context-aware 3D Object Reconstruction from Single and Multiple Images
- Long-Range Grouping Transformer for Multi-View 3D Reconstruction
- LegoFormer: Transformers for Block-by-Block Multi-view 3D Reconstruction
- VPFusion: Joint 3D Volume and Pixel-Aligned Feature Fusion for Single and Multi-view 3D Reconstruction
- DiffPoint: Single and Multi-view Point Cloud Reconstruction with ViT Based Diffusion Model
- 体素生成方面的数据集
- 0624阶段性总结
GPT关于3D-GS的回答
如果我获得了一个3D高斯溅射的表达,给定任意的相机内参和外参,是不是就能生成一副2D图像
Yes, given a 3D Gaussian splatting representation and the intrinsic and extrinsic camera parameters, you can generate a 2D image from any desired viewpoint. Here’s a step-by-step explanation of how this process works:
1. 3D Gaussian Representation
3D Gaussians are defined by their mean (center), covariance matrix (defining their shape and orientation in 3D space), and color. These parameters collectively represent the scene.
2. Camera Parameters
To render a 2D image, you need:
- Intrinsic parameters: These define the camera’s internal characteristics, such as focal length, principal point, and distortion coefficients.
- Extrinsic parameters: These define the camera’s position and orientation in the world space, typically represented by a rotation matrix and a translation vector.
3. View Transformation
The 3D Gaussians need to be transformed from the world coordinate system to the camera coordinate system using the extrinsic parameters. This involves:
- Rotation: Aligning the scene with the camera’s viewpoint.
- Translation: Positioning the scene relative to the camera.
The transformation can be represented as:
[ \text{camera_coords} = R \cdot \text{world_coords} + T ]
where ( R ) is the rotation matrix and ( T ) is the translation vector.
4. Projection Transformation
The transformed 3D Gaussians are then projected onto the 2D image plane using the intrinsic parameters. This projection involves:
- Mapping the 3D coordinates to 2D coordinates on the image plane.
- Applying perspective projection using the camera’s focal length and principal point.
The projection matrix ( P ) combines the intrinsic parameters:
[ \text{image_coords} = P \cdot \text{camera_coords} ]
where ( P ) is the projection matrix constructed from the intrinsic parameters.
5. Gaussian Splatting
The 3D Gaussians are then “splatted” onto the 2D image plane. This involves:
- Projecting each Gaussian’s mean to the 2D plane.
- Transforming the 3D covariance matrix to 2D to define the shape and orientation of the projected Gaussian.
- Rendering the 2D Gaussians as ellipses based on the transformed covariance matrix.
6. Visibility and Occlusion Handling
To correctly render the scene, visibility and occlusion need to be managed. This is typically handled using a depth buffer (z-buffer) to ensure that closer Gaussians correctly occlude those farther away from the camera.
Example Code Outline
Here is an outline of what the process might look like in Python using a hypothetical rendering function:
import numpy as np
import matplotlib.pyplot as plt
def render_image(gaussians, intrinsic_params, extrinsic_params):
R, T = extrinsic_params
P = intrinsic_params
projected_gaussians = []
for gaussian in gaussians:
mean, covariance, color = gaussian
# Transform mean to camera space
camera_mean = R @ mean + T
# Project mean to 2D
homogeneous_mean = np.append(camera_mean, 1)
image_mean = P @ homogeneous_mean
image_mean /= image_mean[2]
# Transform covariance to camera space and project to 2D
camera_covariance = R @ covariance @ R.T
projected_covariance = P @ camera_covariance @ P.T
# Store the 2D Gaussian (mean, covariance, color)
projected_gaussians.append((image_mean[:2], projected_covariance, color))
# Render the projected Gaussians
fig, ax = plt.subplots()
for mean, covariance, color in projected_gaussians:
ellipse = plot_ellipse(mean, covariance, color)
ax.add_patch(ellipse)
plt.xlim(0, intrinsic_params[0][2] * 2)
plt.ylim(0, intrinsic_params[1][2] * 2)
plt.show()
# Example usage with hypothetical data
gaussians = generate_gaussians() # Your 3D Gaussians
intrinsic_params = get_intrinsic_params() # Your camera's intrinsic parameters
extrinsic_params = get_extrinsic_params() # Your camera's extrinsic parameters
render_image(gaussians, intrinsic_params, extrinsic_params)
In this example, generate_gaussians, get_intrinsic_params, and get_extrinsic_params are placeholders for functions that would provide the necessary data. The plot_ellipse function would handle the rendering of each Gaussian as an ellipse on the 2D plane.
Conclusion
By following these steps, you can render a 2D image from any viewpoint using a 3D Gaussian splatting representation and given camera parameters. This approach is powerful for creating realistic images from complex 3D data efficiently.
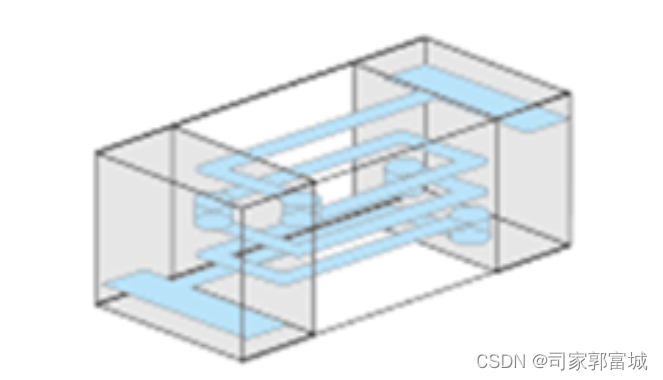
MVSplat论文
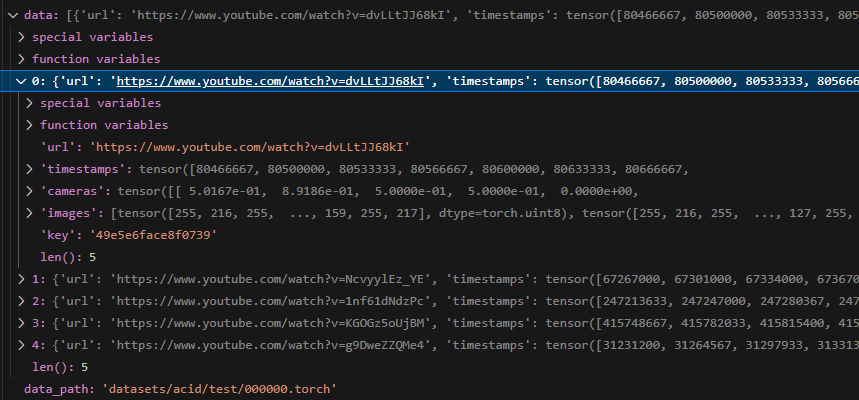
数据构造:包含url、时间戳、相机参数(没看懂)、连续帧图像、key
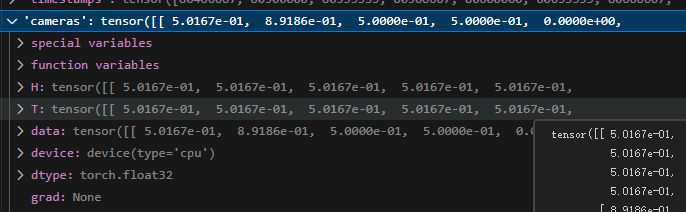
相机里面有H、T、data,可能要去pixelSplat论文里去看
三维重建——3D Gaussian Splatting
高斯溅射3D Guassian Splatting是2023年Siggraph发表的一项创新性技术,其基本的思路为利用运动结构恢复SfM,从一组多目图像中估计一个显性的稀疏点云。对于该点云中的每一个点,构造一个类似散射场的高斯椭球概率预测模型,通过神经网络完成学习,获得每一个椭球的对应参数,进而得到一个类似体像素的离散表示,以支持多角度的体渲染和光栅化。
神经散射场的问题在于无法将概率预测控制在一个可控的区域。高斯椭球提供了一个有效的解决方案,该技术将概率预测压缩在一个基于稀疏点云的多个高斯分布中。即每一个概率预测的计算都是以稀疏点云中的一个点为标定,一个特定的作用范围作为概率预测的界限。这样,体渲染面对的不是全局场景,而是椭球限定的一组小区域。全局优化被拆解为一组局部优化,对应的计算效率自然会有所提升。高斯溅射技术就是基于上述思路提出,以平衡渲染效率和精度。
https://blog.csdn.net/aliexken/article/details/136072393
https://zhuanlan.zhihu.com/p/661569671
三维高斯根据知乎的解读,主要应用点在于通过在一个方向上的积分快速生成二维渲染图像,不太适合乐高装配任务
3D高斯可能并不是3D模型
https://github.com/graphdeco-inria/gaussian-splatting/issues/418
高斯溅射出来的2D可能看起来很像本来那个3D的东西向那个观察点投影所看到的,但是,“也仅仅是看起来像,和那个物理实在,可能有比较远的差距”; 当你需要更接近物理实际的点云和表面mesh的时候,问题挑战不仅在于充分利用高斯点的全部信息(不仅mean, covar等直接的位置中心和点形状信息,还包括sh feature,还可能需要考虑周边点,因为渲染的的时候有个融合过程),更在于GS的输出GaussPointCloud本身的质量就没有那么好(相对于物理实际)
三维重建——occupancy network类的
三维重建——voxel模型类
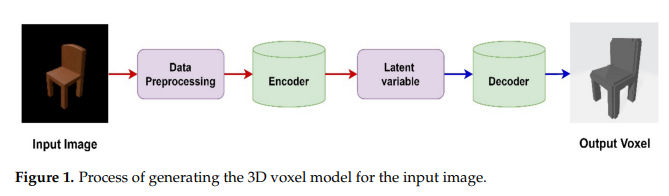
A Voxel Generator Based on Autoencoder
从简单图形生成voxel模型
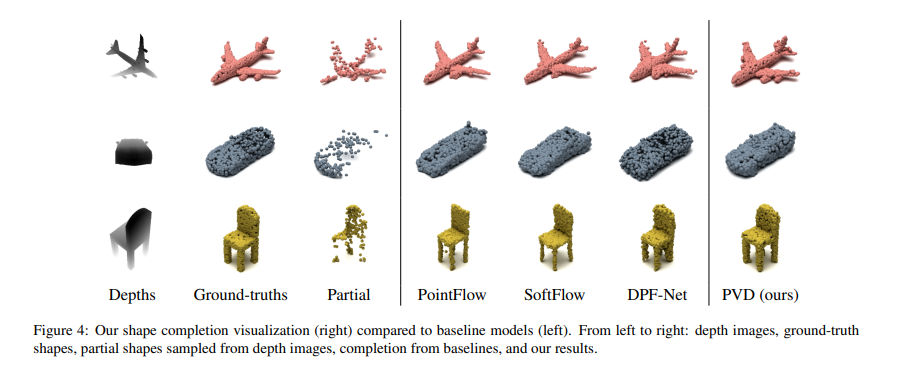
3D Shape Generation and Completion through Point-Voxel Diffusion
从深度图生成voxel模型
https://arxiv.org/pdf/2104.03670
Image-to-Voxel Model Translation for 3D Scene Reconstruction and Segmentation
https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123520103.pdf
部分开源: https://github.com/vlkniaz/SSZ

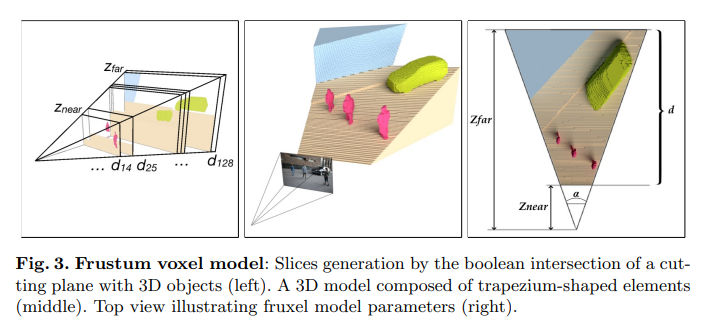

看起来比较接近要做的事
没说速度多少
TMVNet : Using Transformers for Multi-view Voxel-based 3D Reconstruction
https://openaccess.thecvf.com/content/CVPR2022W/PBVS/papers/Peng_TMVNet_Using_Transformers_for_Multi-View_Voxel-Based_3D_Reconstruction_CVPRW_2022_paper.pdf
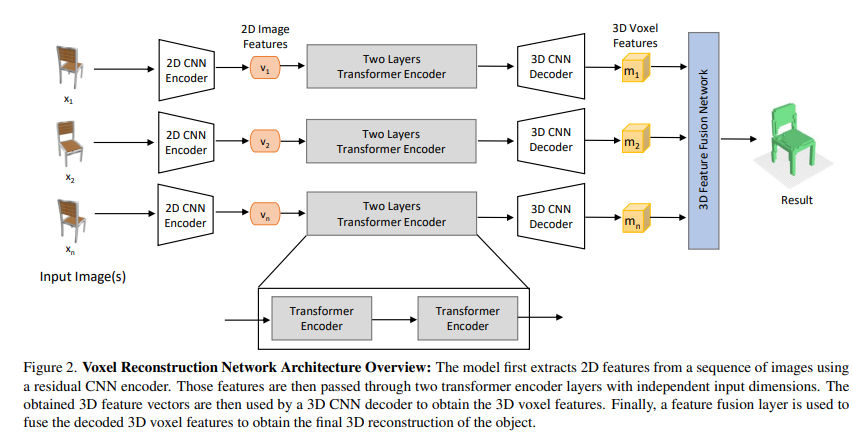
从多视角图像中生成voxel模型,输入比较干净
没开源
VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion
https://openaccess.thecvf.com/content/CVPR2023/papers/Li_VoxFormer_Sparse_Voxel_Transformer_for_Camera-Based_3D_Semantic_Scene_Completion_CVPR_2023_paper.pdf
英伟达的组
开源: https://github.com/NVlabs/VoxFormer
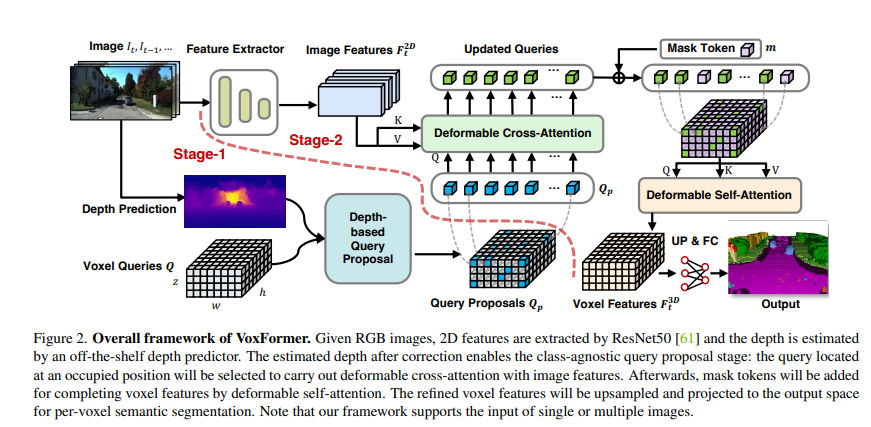
以上都是单目的
多视角 Multi-view Stereo
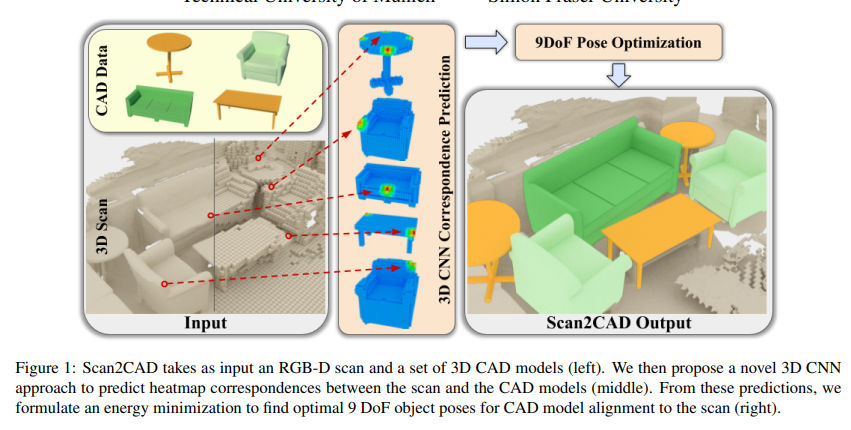
Scan2CAD: Learning CAD Model Alignment in RGB-D Scans
https://arxiv.org/pdf/1811.11187v1
Robust Attentional Aggregation of Deep Feature Sets for Multi-view 3D Reconstruction
https://arxiv.org/pdf/1808.00758v2

这篇看起来输入输出比较像
3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction
https://arxiv.org/pdf/1604.00449v1
这篇也类似
背景干净的图片生成3D模型
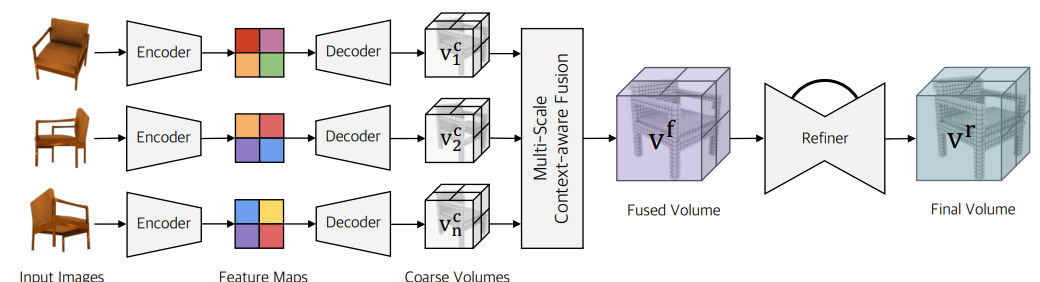
Pix2Vox++: Multi-scale Context-aware 3D Object Reconstruction from Single and Multiple Images
https://arxiv.org/pdf/2006.12250 2020
https://gitlab.com/hzxie/Pix2Vox
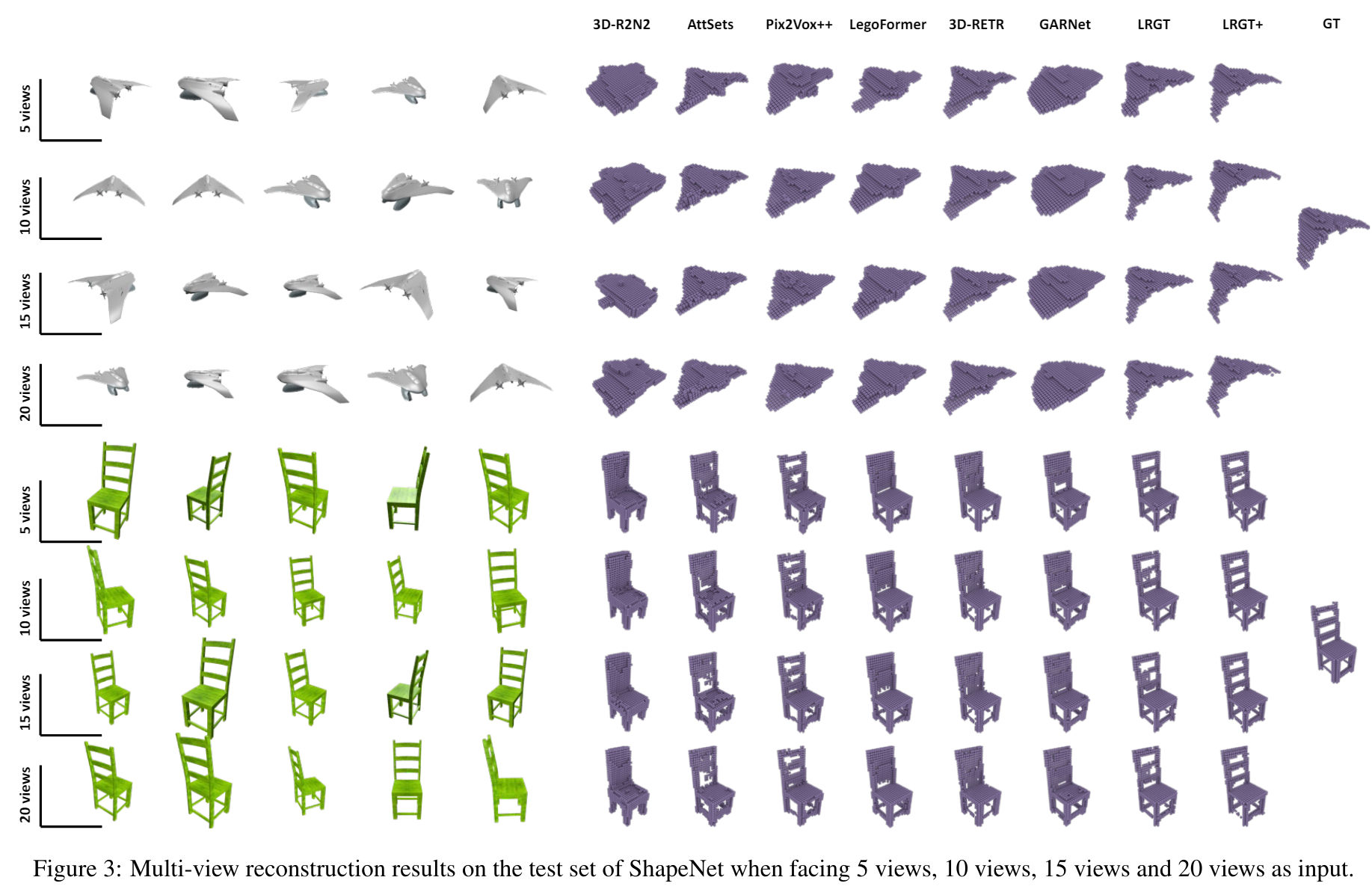
Long-Range Grouping Transformer for Multi-View 3D Reconstruction
https://arxiv.org/pdf/2308.08724 2023
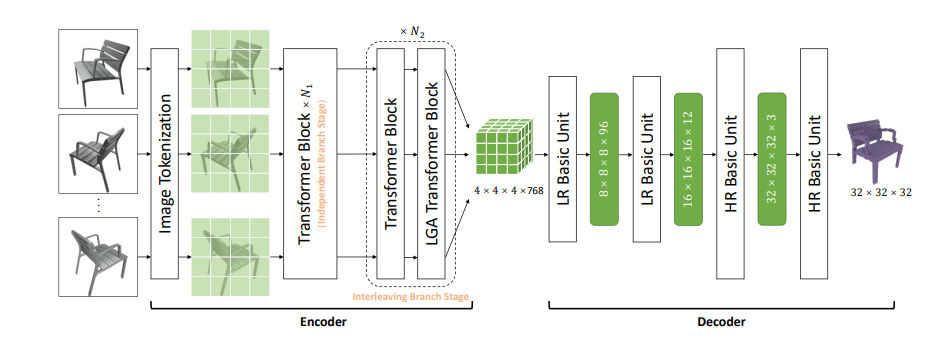
文章的baseline提到了
LegoFormer: Transformers for Block-by-Block Multi-view 3D Reconstruction
https://arxiv.org/pdf/2106.12102
https://github.com/faridyagubbayli/LegoFormer

可以单帧也可以多帧
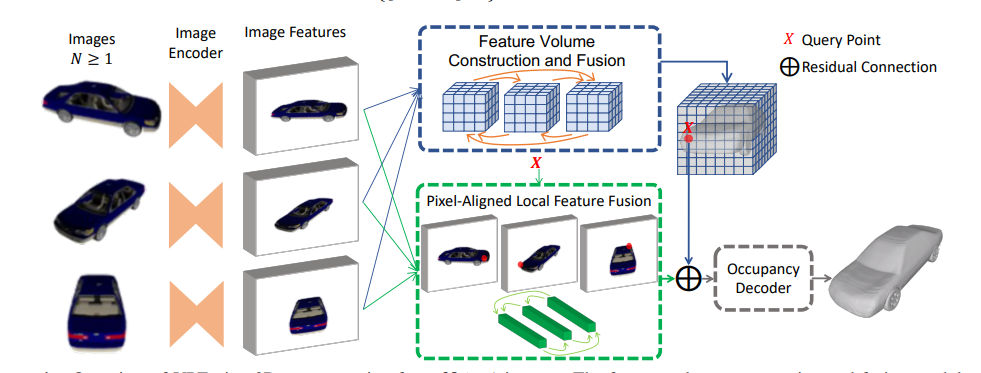
VPFusion: Joint 3D Volume and Pixel-Aligned Feature Fusion for Single and Multi-view 3D Reconstruction
https://arxiv.org/pdf/2203.07553 2022
DiffPoint: Single and Multi-view Point Cloud Reconstruction with ViT Based Diffusion Model
https://arxiv.org/pdf/2402.11241v1 2024

提到了这方面的baseline
这篇没开源
体素生成方面的数据集
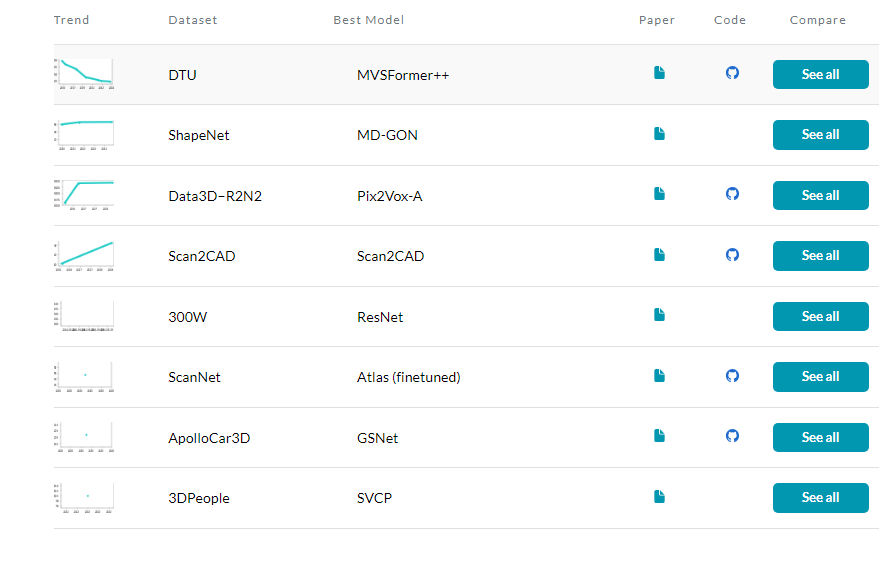
好像就ShapeNet和Data3D-R2N2
https://paperswithcode.com/sota/3d-object-reconstruction-on-data3dr2n2
0624阶段性总结
DTU数据集
LRGT这类使用shapenet数据集的渲染图训练
MVSFormer这种生成的是基于参考图视角的深度图,速度慢,只有一个视角
MVSplat和pixelSplat这类3DGS是生成渲染图,也可以从高斯生成点云,据说不够准确
voxFormer等单目occ方法,可以多目联动,但是数据集都是大尺度的KITTI之类的
上海人工智能实验室新数据集:
https://omniobject3d.github.io/