为什么 MySQL 选择 B+ 树作为索引?
关于 MySQL 的 B+ 树,我们经常会被问这样的问题:
- 为什么索引用 B+ 树,而不用红黑树?
- 为什么索引用 B+ 树,而不用 B 树?
- 为什么索引用 B+ 树,而不用哈希表?
- 为什么索引用 B+ 树,而不用数组?
………………
你有没有想过,为什么 MySQL 数据库选择 B+ 树作为索引数据结构?这可不是随便选的,背后蕴藏着不少秘密。
要解释这个问题,其实不单单要从数据结构的角度出发,还要考虑磁盘 I/O 操作次数,因为 MySQL 的数据是存储在磁盘中的嘛。
MySQL 索引需要满足的条件
需要满足两点:
- 尽可能少的磁盘 I/O 操作
- 既要能高效的查询某一条记录,也要高效的进行范围查询
为什么索引用 B+ 树,而不用红黑树?
红黑树本质上是二叉树,而 B+ 树是多叉树,这样在存储相同数量量的情况下,红黑树的树会比 B+ 树的树高,由于 InnodB 引擎的数据都是存储在磁盘上的,如果树的高度越高,意味着磁盘 I/O 就越多,这样就会影响查询性能。
所以,InnodB 引擎选择了 B+树作为索引,而不是红黑树。
为什么索引用 B+ 树,而不用 B 树?
有三个角度来分析:
磁盘 I/O 角度;
范围查询角度;
增删改查角度;
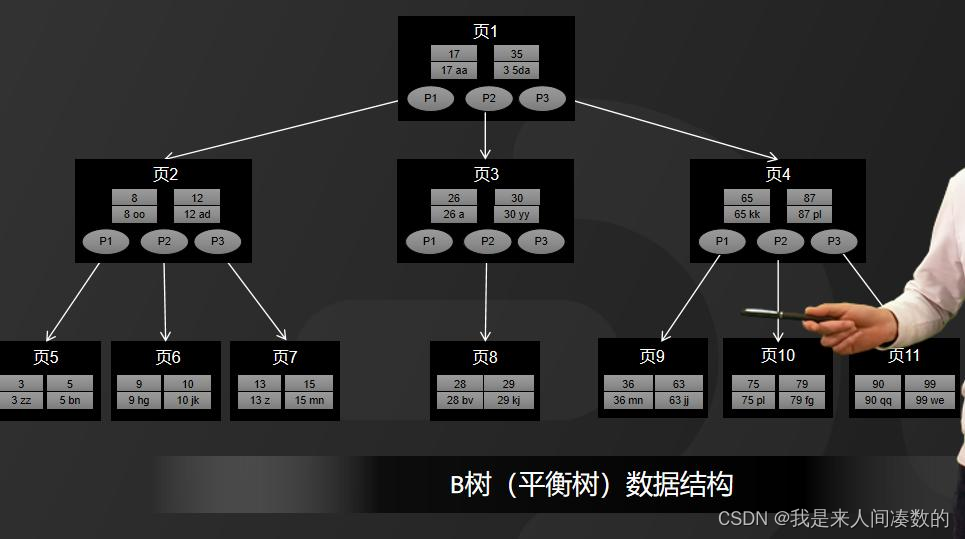
B+ 树的磁盘读写代价更低:B+ 树只有叶子节点才会存放索引和数据,非叶子节点只存放索引,而 B 树所有节点都存放索引和数据,而页的默认大小是固定的(16KB),如果不存储数据,就会存储更多的键值,相应的树的阶数就会更大,因此存储相同数据量的情况下, B+ 树可以比 B 树更加矮胖,查询叶子节点的磁盘 I/O 次数会更少
B+ 树便于范围查询:B+ 树所有叶子节点之间会用双向链表链表进行连接,使得 B+ 树在范围查询,排序查询,分组查询以及去重查询等变得更加简单,而 B 树只能通过中序遍历来完成,这会比 B+ 树涉及到更多的磁盘 I/O 操作
B+ 树增删改查更加稳定:B+ 树有大量的冗余节点,这些冗余数据可以让 B+ 树在插入、删除的效率都更
高,比如删除根节点的时候,不会像 B 树那样会发生复杂的树的变化。另外,B+树把所有的用户记录都放到了叶子节点这一层,因此查询、插入、删除数据都需要走到最后一层,这不同于 B 树可能在任意一层找到数据,所以B+树更为稳定。
所以,InnodB 引擎选择了 B+树作为索引,而不是 B 树。


为什么索引用 B+ 树,而不用哈希表?
- 哈希表的数据是散列分布的,不支持范围查询和排序
- 哈希表存在哈希冲突的问题,哈希冲突严重的话会降低查询效率
MySQL 会有很多范围查询和排序的场景,虽然哈希表的搜索时间复杂度为 O(1),但是哈希表的数据都是通过哈希函数计算后散列分布的,所以哈希表索引不支持范围查询和排序操作,不支持联合索引最左匹配原则,如果重复键值比较多,还容易造成哈希碰撞导致效率进一步降低,而 B+ 树可以满足这些应用场景,因此选择了用 B+ 树。
为什么索引用 B+ 树,而不用数组?
用数组来实现线性排序的数据虽然简单好用,但是插入新元素的时候性能太低。
因为插入一个元素,需要将这个元素之后的所有元素后移一位,如果这个操作发生在磁盘中呢?这必然是灾难性的。因为磁盘的速度比内存慢几十万倍,所以我们不能用一种线性结构将磁盘排序。
其次,有序的数组在使用二分查找的时候,每次查找都要不断计算中间的位置。
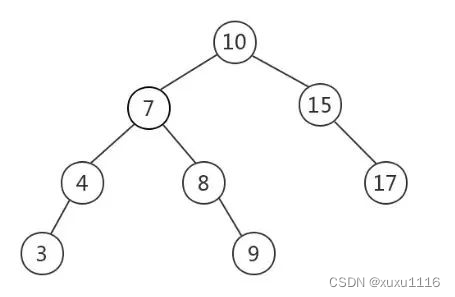
为什么索引用 B+ 树,而不用二叉搜索树?
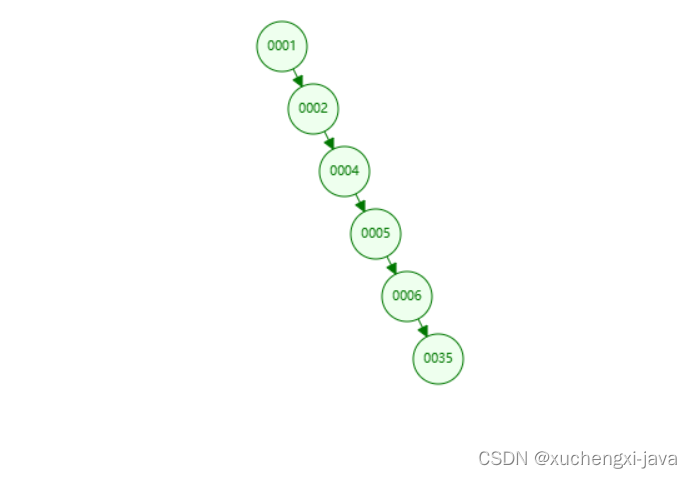
在特殊情况下,比如当每次插入的元素都是二叉查找树中最大的元素,二叉查找树就会退化成了一条链表,查找数据的时间复杂度变成了 O(n)
随着插入的元素越多,树的高度也变高,意味着需要磁盘 IO 操作的次数就越多,这样导致查询性能严重下降,再加上不能范围查询,所以不适合作为数据库的索引结构。