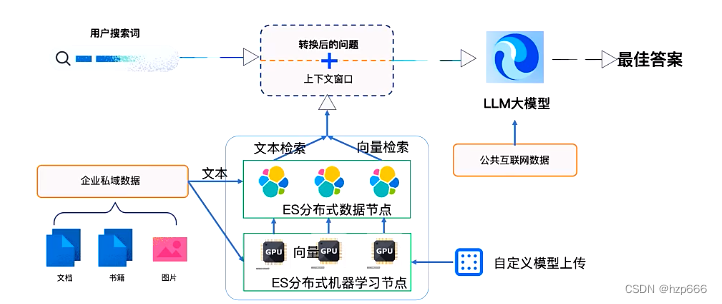
问题
大家在使用 cosy voice 自回归模型时(sft 模型)时,可能遇到声音忽大忽小现象。
解决方案
在生成音频之前,加上标准话音频响度即可。
import pyloudnorm as pyln
import numpy as np
from cosyvoice.cli.cosyvoice import CosyVoice
import torch
import torchaudio
def _norm_loudness(audio, rate):
"""
标准化音频响度
:param audio: 音频数据,可以是 PyTorch 张量或 NumPy 数组
:param rate: 采样率
:return: 标准化后的音频数据,PyTorch 张量
"""
if isinstance(audio, torch.Tensor):
audio = audio.numpy()
if audio.ndim == 2:
audio = audio.squeeze()
meter = pyln.Meter(rate)
loudness = meter.integrated_loudness(audio)
normalized_audio = pyln.normalize.loudness(audio, loudness, -16.0)
return torch.from_numpy(normalized_audio)
def prepare_audio(audio):
"""
准备音频数据
:param audio: 音频数据
:return: 标准化后的音频数据
"""
if audio.ndim == 1:
audio = audio.unsqueeze(0)
return _norm_loudness(audio, 22050)
wav_list = []
cosyvoice = CosyVoice("./pretrained_models/CosyVoice-300M-SFT")
output = cosyvoice.inference_sft(line, "旁白")
tts_speech = prepare_audio(output["tts_speech"])
wav_list.append(tts_speech)
wav_list = [wav if wav.ndim == 2 else wav.unsqueeze(0) for wav in wav_list]
wav_list = torch.concat(wav_list, dim=1)
output_path = os.path.join(f"./tmp/{book_name}/gen", f"{book_name}_{idx}.wav")
torchaudio.save(output_path, wav_list, 22050)




































![[译] Rust标准库有些特殊,让我们改它](https://img-blog.csdnimg.cn/img_convert/c3e6fbabddcfb53d56c294ffb5e9f074.png)
