在数据库管理系统中,确保数据的一致性和完整性是至关重要的。特别是在面对系统崩溃或意外中断时,如何有效地恢复事务状态成为了一个关键问题。MySQL的InnoDB存储引擎通过引入REDO日志和UNDO日志机制,巧妙地解决了这一问题,确保了事务的原子性、持久性、一致性和隔离性(ACID特性)。本文将深入探讨这两种日志在数据库崩溃时如何协同工作以恢复事务。
1. UNDO日志:保障事务的原子性
原理
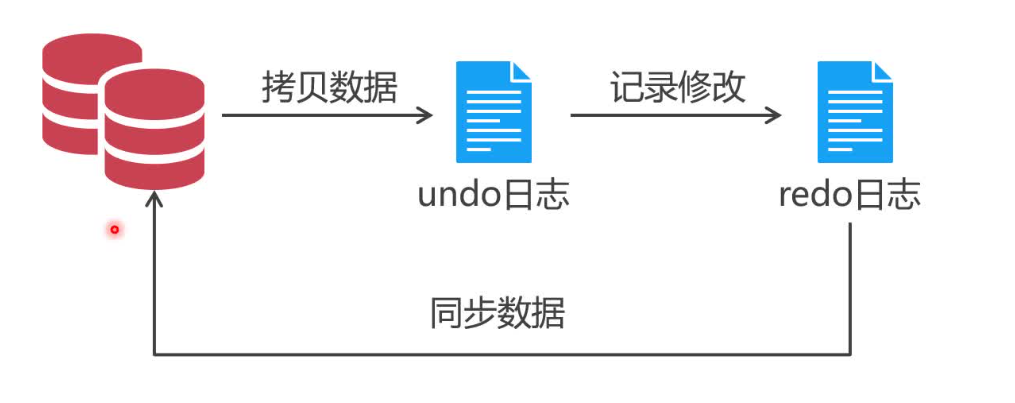
UNDO日志是InnoDB存储引擎实现事务原子性的核心机制。每当事务对数据库进行修改时,InnoDB会首先将这些修改前的数据记录到UNDO日志中。这样,如果事务在执行过程中遇到错误或用户执行了ROLLBACK操作,系统就可以利用UNDO日志中的备份数据,将数据库恢复到事务开始前的状态,确保“要么全部完成,要么不做任何操作”的原子性要求。
持久化与恢复
为了同时保证原子性和持久性,InnoDB确保UNDO日志在数据持久化之前被写入磁盘。这意味着,即使在事务提交前的某个时刻系统崩溃,只要UNDO日志是完整的,就可以利用它来回滚事务,恢复到崩溃前的状态。而如果数据在写入磁盘前系统崩溃(即在UNDO日志之后、数据持久化之前),则由于数据未真正写入磁盘,磁盘上的数据将保持在事务开始前的状态。
缺陷与优化
尽管UNDO日志在保障事务原子性方面发挥了重要作用,但它也带来了性能上的挑战。频繁地将数据和UNDO日志写入磁盘会显著增加磁盘I/O负担,降低系统性能。为了优化这一点,InnoDB引入了缓冲池(Buffer Pool)来缓存数据和日志,减少直接写入磁盘的次数。然而,这也对事务的持久性提出了新的挑战,因此引入了REDO日志机制来进一步保障数据的可靠性。
2. REDO日志:确保事务的持久性
原理
与UNDO日志相反,REDO日志记录的是新数据的备份。在事务提交前,InnoDB只需将REDO日志持久化到磁盘,而无需立即将数据本身写入磁盘。这样,即使数据在写入磁盘前系统崩溃,也可以通过REDO日志来恢复最新的数据状态,从而确保事务的持久性。
恢复机制
当系统崩溃重启后,InnoDB会首先检查REDO日志。如果发现存在未应用的事务日志,它会按照日志中的记录顺序,重新执行这些操作,将数据库恢复到崩溃前的最新状态。这一过程称为“前滚”(Forward Roll)或“重做”(Redo)。
协同工作
在实际应用中,UNDO日志和REDO日志是协同工作的。UNDO日志用于在事务失败或回滚时恢复数据到原始状态,确保事务的原子性;而REDO日志则用于在系统崩溃后恢复已提交事务的修改,确保事务的持久性。两者相互配合,共同构成了InnoDB存储引擎强大的事务恢复机制。
结论
通过引入UNDO日志和REDO日志机制,MySQL的InnoDB存储引擎能够在系统崩溃或事务失败时有效地恢复数据状态,确保事务的ACID特性得以保持。这两种日志机制各自承担不同的角色,但又相互依存、协同工作,为数据库的稳定运行提供了坚实的保障。























![[论文笔记] 揭开缺陷:探索合成中的缺陷——大型语言模型的数据和缓解策略 Unveiling the Flaws: Exploring Imperfections in Synthetic Data](https://i-blog.csdnimg.cn/direct/26783b01790f47b18ef1f7081bca569d.png)

















