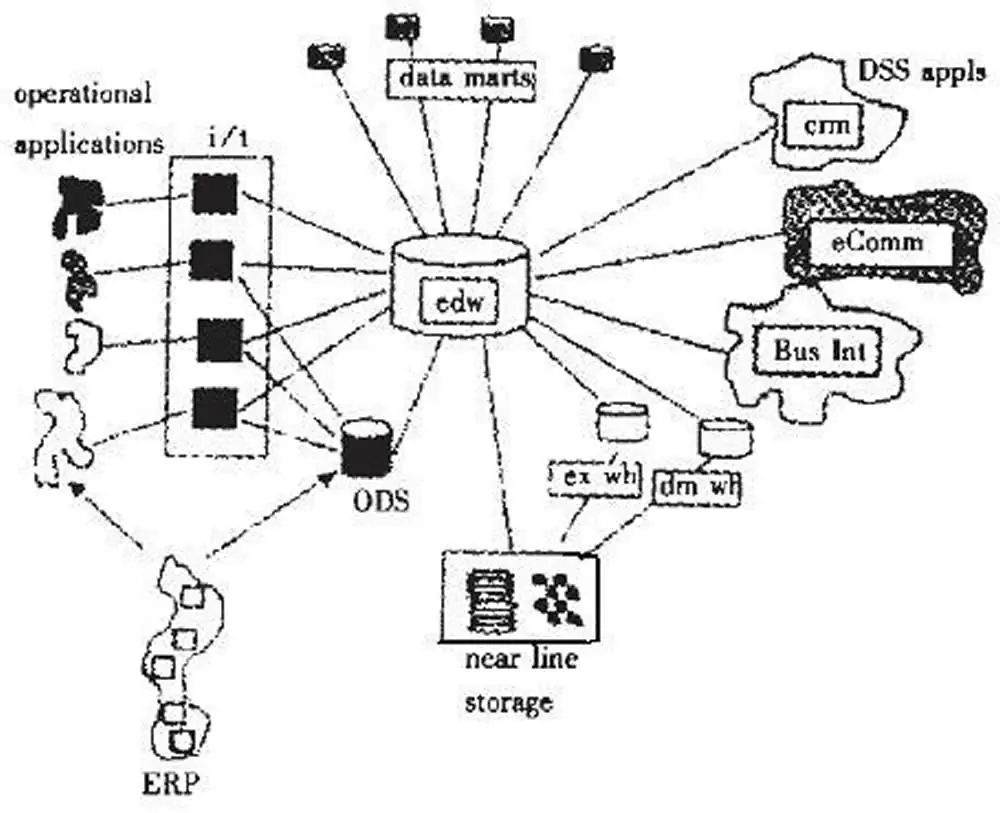
在https://hpg123.blog.csdn.net/article/details/137705869中,根据论文提供的数据初步整理出了模型剪枝的信息,但不够精练,故而在此深入分析。
主要解决以下问题:
1、模型剪枝真的有用么?
2、什么样的方案模型剪枝效果好?
3、模型剪枝对性能影响大么?
通过分析,得出结论,剪枝是有用的;自动结构化剪枝效果是综合效果最优的;对于任意规模的问题训练处的模型,剪枝50%基本上不会影响精度,如果问题规模较小,剪枝规模还可以更大。
前提概要
论文中提到的剪枝步骤包含:训练大模型、剪枝成小模型、微调小模型。

然后与剪枝方案对比的训练方案有,Scratch-E、Scratch-B。
Scratch-E:表示与剪枝模型训练相同epoch数,
Scratch-B:表示相同计算预算的训练(在ImageNet上,如果修剪模型节省的FLOPs超过2倍,则将训练epoch的数量增加一倍)
所涉及到的数据有:cifar10、cifar100、imagenet 。cifar10是简单数据、cifar100是复杂数据、 imagenet 是极其复杂的数据。
涉及的模型有:vgg模型(简单结构模型)、resnet模型(复杂结构模型)、densenet模型(超复杂结构模型)。
1、模型剪枝真的有用么?
整体来说是有用的,在论文中虽然证明未剪枝模型展现出了与剪枝模型相同的性能,但有很多隐含信息没有披露。
论文中的剪枝:是从0训练重参数模型开始,然而实际工作中是直接从剪枝开始、或者是从迁移学习模开始。绝大部分工作都是使用开源的预训练模型,从迁移学习开始
基于重参数模型模型得出的剪枝模型,本质上是一个精度快速上升(训练重参数模型),然后在轻微下降的过程。很多时候,模型剪枝掉少量参数后,并没有显著的精度下降,重新训练的精度起点比较高。例如一个模型剪枝掉10%的权重 从torch-prune项目中的一个图片可以看出,模型参数从2.57左右降低到2.28左右,精度只是从75%左右降低到60%左右。

然而,从0开始训练目标结构的模型,是一个精度慢慢上升的过程(小模型的拟合能力必然是没有迁移大模型强)。从零训练精度通常是从0开始增加,至少要20个epoch左右才能达到top精度的30%-50%左右。在精度起点上,从0训练就要额外多20个epoch保持相同的起点。
论文中所阐述的Scratch-B,可以媲美甚至超越剪枝的精度,要求相同的训练预算,这意味着epoch数要比剪枝多n倍。如下图所示,Scratch-E与Scratch-B的精度差距不足0.2%, 但这两个方法都是一样的训练起点与过程,只是Scratch-B的epoch数多了n倍。假设剪枝50%,Scratch-B训练了100个epoch,那Scratch-E则训练了200个epoch 这是一个精度缓慢的增长过程,在普通的训练重很可能就因为early stop策略而停止了,作者却通过耐心训练达成目标,但未取得与训练资源相匹配的效果。

2、什么样的方案模型剪枝效果好?
在论文中一个展示了3种剪枝策略:预定义的结构化修剪、自动结构化剪枝、基于非结构化大小的修剪。通过分析自动结构化剪枝是最为有效的。
预定义的结构化修剪:是指基于现有网络,进行layer kernel数量级的剪枝,在训练前就已经设定好目标结构了。以ImageNet结构为例,
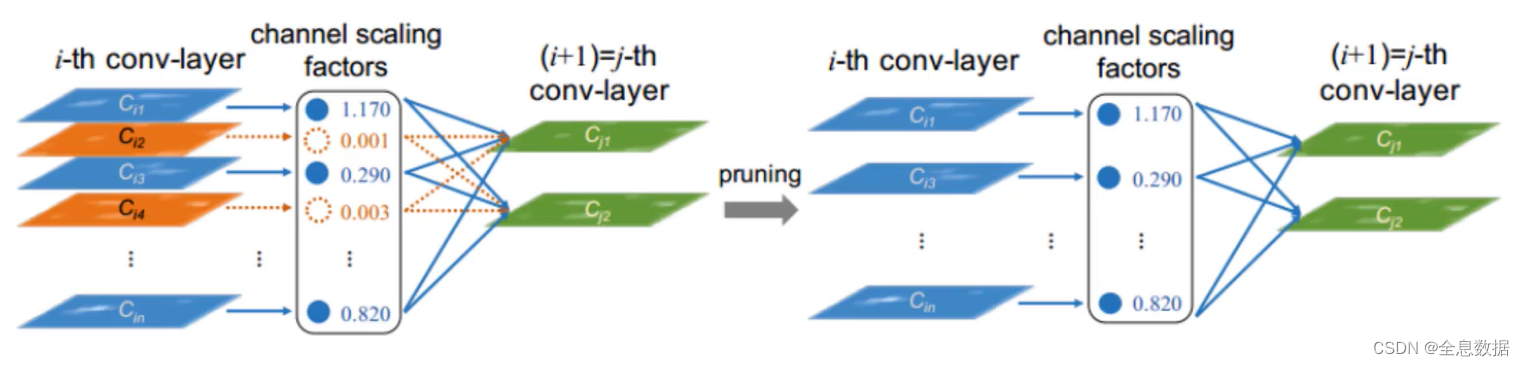
自动结构化剪枝:是指基于现有网络,对符合剪枝条件的layer kernel进行剪枝,在剪枝前不知道目标网络结构。
基于非结构化的修剪:是指基于现有网络,对符合剪枝条件的参数进行移除(是一个最细粒度的参数移除),在剪枝前不知道目标网络结构。
2.1 预定义的结构化修剪效果
这里关于CIFAR-10的结果可以忽略(这是一个简单数据集)。
关于ImageNet的剪枝中,基于L1规则的剪枝效果保持最好,是通过最小化下一层的特征图重建误差来修剪通道方法。 但这里的数据不够全面,没有展示出ResNet50在L1测量下的剪枝效果。然后论文作者得出结论,剪枝模型不如同等训练资源下的原始模型; 但我们已经分析出,这在工程上是个假命题; 同时也透露了,在预定义结构的剪枝方法下,是一定存在精度损失的。


2.2 自动结构化剪枝效果
该方法是基于L1等权重重要性分析规则,移除模型中的权重。本质上可以看成非结构化剪枝的更高层或更粗粒度
在该方法下,可以看到剪枝40%的权重,模型依然能保持相同的精度。可以看出该方案是优于2.1方案的。 这里没有进行剪枝后得出目标网络结构,实际上是无法开展Scratch-E或者Scratch-B的工作。

2.3 非结构化剪枝效果
非结构化剪枝表现出与自动化结构剪枝类似的将,可以确定剪枝50%左右对精度没有影响。但是,非结构化剪枝后的模型在普通硬件上并没有加速效果,只有结构化剪枝才能在普通硬件上加速。 实际上没有用

3、模型剪枝对性能影响大么?
对于一般性难点数据(CIFAR100级别),基于章节2中分析,其实已经可以发现剪枝50%(模型加速一倍),对任意被剪枝性能基本上是没有影响的。 基于DepGraph: Towards Any Structural Pruning论文数据,更是可以发现剪枝到30%(推理速度3x)也可以保持性能。

对于简单性数据(CIFAR10级别),基于下图可以看出,对于高冗余模型vgg16(传统conv模型),精度几乎没有影响,也就是说可以在高冗余模型中剥离出80%的无关参数。但对于Resnet等复杂设计的模型,精度存在下降。这与前面的图表数据有冲突,章节2中的图表展示,对于CIFAR10数据,对任意剪枝模型基本上没有精度变化。

对于复杂性数据(ImageNet级别),基于章节2中分析,其实已经可以发现剪枝50%(模型加速一倍),对任意被剪枝性能基本上是没有影响的。 通过论文SlimSAM: 0.1% Data Makes Segment Anything Slim中的数据也可以发现。如果存在精度下降,只能是说剪枝的方式与权重选择方式存在问题。






























![[240714] X-CMD 发布 v0.4.0:引入 pixi 、pkgx、scorecard、kill 和 top 模块](https://i-blog.csdnimg.cn/direct/e28ab35b455149fb929c79499cc41885.png#pic_center)