引言
当今,人工智能技术日益成熟,大语言模型作为其重要组成部分,正以惊人的速度改变着我们的生活和工作方式。今天也是很荣幸,博主得到平台的信任,有幸拿到了一块香橙派 AI pro,这块板子作为业界首款基于昇腾深度研发的AI开发板,其配备的 8/20TOPS澎湃算力是目前开发板市场中所具备的最大算力,那么今天我们就将探索如何利用香橙派 AIpro 平台,通过Ollame将大语言模型部署到本地。
目录
一、香橙派与迅龙软件介绍
香橙派(Orange Pi)是一系列由深圳市迅龙软件有限公司。公司成立于2005年,作为全球领先的开源硬件和开源软件服务商,致力于让极客、创客、电子爱好者享用到优质而具有高性价比的科技产品,通过大规模的社会化协作去创建一个更加美好的信息化人类文明。
1.1香橙派 AI pro 开发版

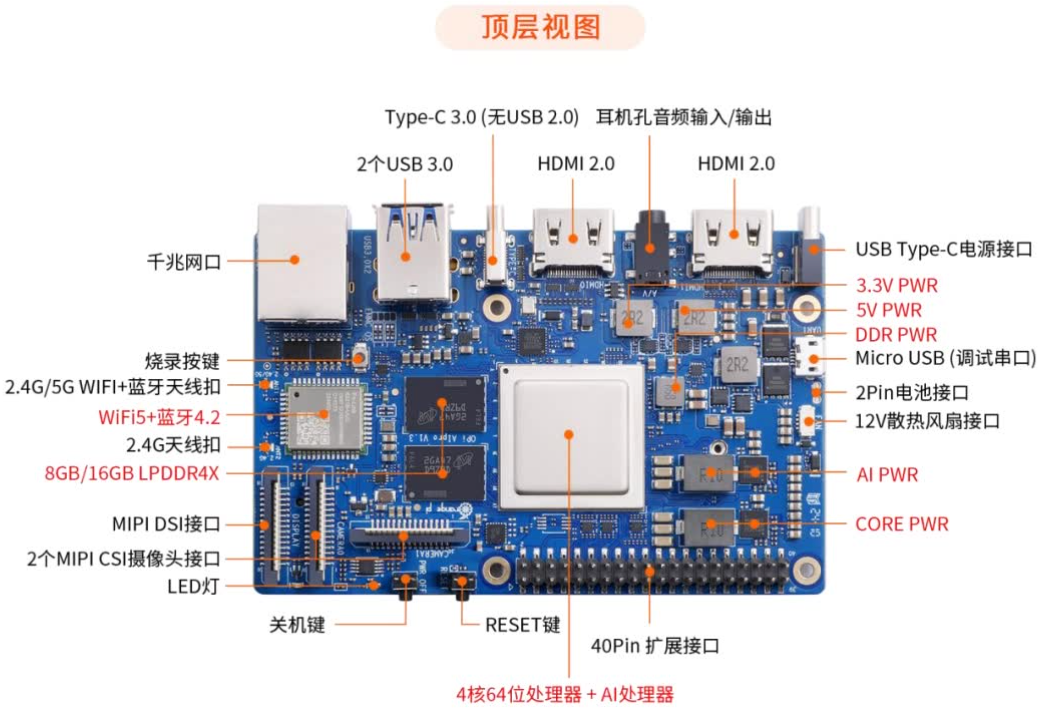
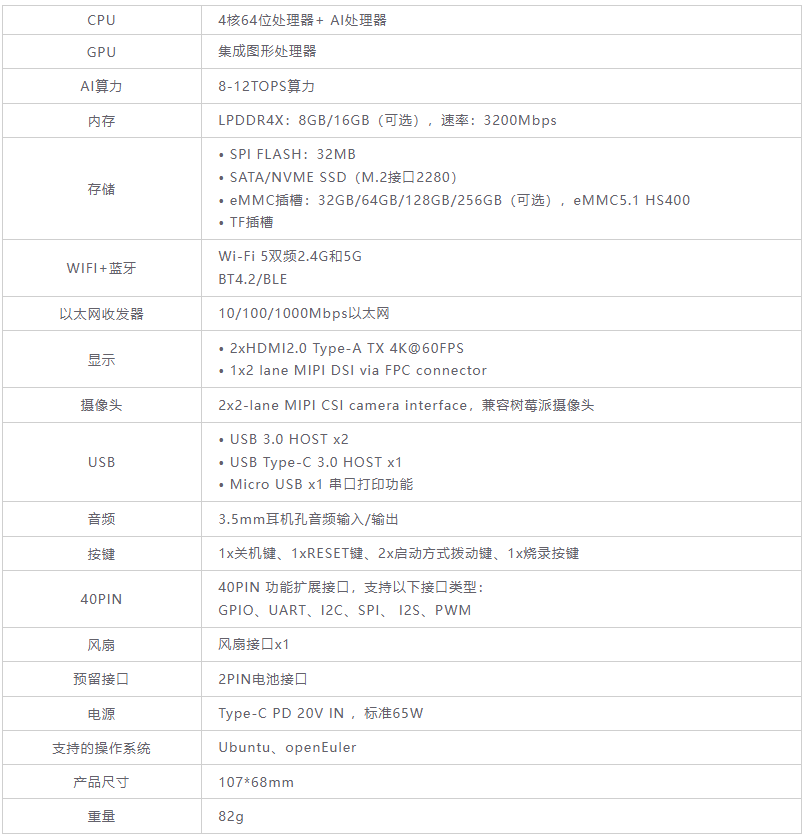
此次评测的是香橙派 AI pro 开发版,香橙派AI pro开发板是由香橙派联合华为推出的高性能AI开发板,它采用了昇腾AI技术路线,集成了4核64位处理器和AI处理器,支持高达8-12TOPS的AI算力。该开发板配备了8GB/16GB LPDDR4X内存,并支持通过eMMC模块或M.2接口扩展存储空间。香橙派AIpro支持双4K高清输出,并提供了丰富的接口,包括两个HDMI输出、GPIO接口、Type-C电源接口、支持SATA/NVMe SSD的M.2插槽等,适用于多种AI应用场景,如AI边缘计算、深度视觉学习、视频分析等。操作系统方面,香橙派AIpro支持Ubuntu和openEuler,以满足不同开发者的需求
1.2外观评价
刚收到板子的心情非常激动的,这边随手拍拍给大家展示一下,不多不说香橙派这次外观上没得说,无论是包装还是内部做工都很专业很精致。



接上线开机完全体,应该是我拍照的问题,感觉图片看起来都好丑啊!!!

二、上手实测与部署大模型
开机启动,这套开发版内置了 Open Euler 系统镜像。这里简单介绍一下,Open Euler 是一由中国开源软件基金会主导,以Linux稳定系统内核为基础,华为深度参与,面向服务器、桌面和嵌入式等的一个开源操作系统

输入密码并连接WiFi,我们就得到了一台基于Open Euler的开发设备了
2.1使用Ollame部署和运行大模型
上机第一件事,打开命令行,安装Docker

在我们的主机上安装Docker,需要设置 Docker 仓库。依次在终端执行下面的命令
sudo apt-get update sudo apt-get install ca-certificates curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc
添加apt仓库源
echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \ $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update



安装Docker
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin验证Docker是否安装成功
sudo docker run hello-world
2.2 部署和运行开源大模型
我们本次使用的是Ollame部署和运行大模型,Ollama 是一个强大的框架,设计用于在 Docker 容器中部署 LLM。它帮助用户快速在本地运行大模型,通过简单的安装指令,可以让用户执行一条命令就在本地运行开源大型语言模型。
因为我们是一台单机环境,运行环境:8核心、32G内存
docker pull ollama/ollama该命令是从Ollma镜像库中拉取和安装Ollama环境。
目前镜像是默认连接Github下载,如果尝试多次都是连接timeout,建议手动从Ollama官网下载安装

接下来我们启动
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
接下来我们在本地启动
docker exec -it ollama ollama run llama2
操作后进入Ollama容器,(docker exec -it ollama ollama)启动Ollama,并且自动运行llama2大模型。如果是手动启动的Ollama服务,可以运行如下:
sudo systemctl start ollama
2.3下载大模型和运行
Ollama官方地址:https://ollama.com/library
搜索qwen,进入通义千问qwen1.5系列模型链接:qwen (ollama.com)
默认看到6个模型,如果需要更多量化版本的模型,可以在下拉框选择tags中,看到更多量化版本的模型。

6 model sizes, including 0.5B, 1.8B, 4B (default), 7B, 14B, 32B (new) and 72B
ollama run qwen:0.5bollama run qwen:1.8bollama run qwen:4bollama run qwen:7bollama run qwen:14bollama run qwen:32bollama run qwen:72bollama run qwen:110b

选择好了模型以后,直接运行对应的命令(这里需要修改内容,不要直接复制代码!!!)
ollama run qwen:1.8b
完成自动下载和运行,就可以进行对话了,使用qwen:1.8b运行, 速度会偏慢(回答问题需要等待)
当然也可以采用量化版本运行:
ollama run qwen:4b-chat-v1.5-q5_K_M
下次想运行时和使用,输入以下命令
sudo systemctl start ollama ollama run qwen:4b
三、香橙派 AI pro的使用体验
3.1性能和配置
收到开发板并实际上手体验的这俩天,香橙派 AI pro开发板带给我的感觉就是优秀和稳定 ,无论是本地部署大模型还是办公的一般体验都是相当好的,而且尽管是一个开发板,它的散热也没有任何妥协,使用过程中没有一次因为负载过重导致自动重启,在持续的高负荷运作中,体感温度一直保持在50到60°左右,要知道我们本次实现的内容也算是重活了,这也体现了香橙派 AI pro对做工和温控方面的严格。

搭载着目前业界最强大的 8/20TOPS澎湃算力,AI 处理器,丰富的插件扩展口,对未来的嵌入式AI 项目,具有良好的支持。可玩度那是非常的高,为项目创新和开发人员提供广阔的空间,不仅可以用做智能家居开发,还能对各种ALot 都可以能应用
3.2丰富的开发者社区和官方资料

丰富的社区也应证了我的猜想,这就是一款针对开发者,并且收到广大开发者喜爱的开发硬件设备

包括大量年轻人活跃的某站,也有大量基于香橙派的开发视频

官方也为我们提供了相当有趣的项目供我们学习和实践上手测试
四、结语
以上内容就是如何基于Ollame实战大模型部署的内容了,有赖于香橙派 AI pro这块板子配备的 8/20TOPS澎湃算力是目前开发板市场中所具备的最大算力,这款业界首款基于昇腾深度研发的AI开发板,为我们的实践上手提供了很大助力,相信你们看到这里也已经迫不及待的想体验体验了,快去基于你的香橙派 AI pro部署并实测吧,那咱们就下次再见啦。

































![[GXYCTF2019]BabySQli](https://i-blog.csdnimg.cn/direct/fe36ffd77aa642e8a078c1c496ae785c.png)