系列文章目录
第二章 【机器学习】【监督学习】- 逻辑回归算法 (Logistic Regression)
第四章【机器学习】【监督学习】- K-近邻算法 (K-NN)
第五章【机器学习】【监督学习】- 决策树 (Decision Trees)
第六章【机器学习】【监督学习】- 梯度提升机 (Gradient Boosting Machine, GBM)
第七章 【机器学习】【监督学习】-神经网络 (Neural Networks)
第十一章【机器学习】【监督学习】-局部加权线性回归 (Locally Weighted Linear Regression, LWLR)
目录
前言
在先前的文章系列中,我们深入探讨了机器学习的基础框架和算法分类,为读者构建了关于这一领域的坚实理论基础。本章节我们将焦点转向监督学习领域中的一个核心算法—— 岭回归 (Ridge Regression),旨在详尽解析其内在逻辑、应用实践及重要参数调整策略。
一、基本定义
(一)、监督学习
监督学习(Supervised Learning)是机器学习中的一种主要方法,其核心思想是通过已知的输入-输出对(即带有标签的数据集)来训练模型,从而使模型能够泛化到未见的新数据上,做出正确的预测或分类。在监督学习过程中,算法“学习”的依据是这些已标记的例子,目标是找到输入特征与预期输出之间的映射关系。
(二)、监督学习的基本流程
数据收集:获取包含输入特征和对应正确输出标签的训练数据集。
数据预处理:清洗数据,处理缺失值,特征选择与转换,标准化或归一化数据等,以便于模型学习。
模型选择:选择合适的算法,如决策树、支持向量机、神经网络等。
训练:使用训练数据集调整模型参数,最小化预测输出与实际标签之间的差距(损失函数)。
验证与调优:使用验证集评估模型性能,调整超参数以优化模型。
测试:最后使用独立的测试集评估模型的泛化能力,确保模型不仅在训练数据上表现良好,也能在未见过的新数据上做出准确预测。
(三)、监督学习分类算法(Classification)
定义:分类任务的目标是学习一个模型,该模型能够将输入数据分配到预定义的几个类别中的一个。这是一个监督学习问题,需要有一组已经标记好类别的训练数据,模型会根据这些数据学习如何区分不同类别。
例子:垃圾邮件检测(垃圾邮件 vs. 非垃圾邮件)、图像识别(猫 vs. 狗)。
二、 岭回归 (Ridge Regression)
(一)、定义
岭回归(Ridge Regression)是一种用于处理多重共线性问题的线性回归模型,它是普通最小二乘回归的一种变体。岭回归通过在损失函数中加入正则化项来限制模型的复杂度,从而减少模型的方差,防止过拟合。这种正则化项通常是回归系数的平方和(L2范数),它有助于模型系数的收缩,使其更加稳健和接近真实值。
(二)、基本概念
在标准的线性回归中,模型试图找到一组参数(回归系数),以最小化预测值与实际值之间的平方误差之和。然而,当自变量之间存在高度相关性(即多重共线性)时,最小二乘估计的方差可能会变得很大,导致模型不稳定。岭回归通过在损失函数中引入一个惩罚项来解决这个问题,该惩罚项与回归系数的平方成正比,比例因子称为正则化参数(lambda)。
(三)、训练过程
岭回归的训练过程涉及以下步骤:
定义损失函数:岭回归的损失函数由两部分组成:一部分是预测误差的平方和,另一部分是回归系数的平方和(L2范数)乘以正则化参数。
求解参数:通过最小化损失函数来求解回归系数。在数学上,这通常涉及到对损失函数求导并设置导数等于零,然后解出参数向量。对于岭回归,这通常会产生一个闭式解,即正规方程。
选择正则化参数:正则化参数(lambda)的值需要通过交叉验证等方法来确定,以找到使模型泛化性能最佳的值。
(四)、特点
- 稳定性:岭回归能提供更稳定的系数估计,尤其是在面对多重共线性时。
- 偏倚-方差权衡:通过牺牲一些偏倚(模型的期望预测与真实值的差异),岭回归减少了模型的方差,从而提高了模型的预测稳定性。
- 计算效率:对于小到中等规模的数据集,岭回归的闭式解使得模型训练相对快速。
(五)、适用场景:
- 多重共线性:当自变量之间存在高度相关性时,岭回归是减少模型不稳定性和提高预测准确性的有效手段。
- 高维数据:在特征数量远大于观测数量的情况下,岭回归可以防止模型过拟合。
(六)、扩展
岭回归可以扩展到更复杂的模型,例如:
- 弹性网回归(Elastic Net Regression):结合了L1(Lasso回归)和L2(岭回归)正则化,能够在保留岭回归优点的同时,进行特征选择。
- 贝叶斯岭回归:将岭回归置于贝叶斯框架下,允许对模型参数的概率分布进行推断,从而提供不确定性的度量。
三、总结
总的来说,岭回归是一种在面对多重共线性问题时非常有用的线性回归模型,它通过引入正则化项来改善模型的稳定性和泛化能力。
更多内容,防止走丢,请关注公众号,公众号会持续更新各类技术内容和职场介绍:

码上云游



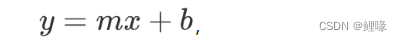
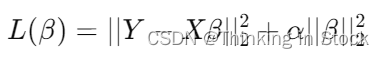





















![[网鼎杯 2020 朱雀组]phpweb](https://i-blog.csdnimg.cn/direct/e189c50ce5ef47fda1285f70f06d9d6b.png)