「AI秘籍」系列课程:

BTS 的《Dynamite》1拥有 15,815,254 条评论,是 YouTube 上评论最多的视频之一。
假设 BTS 成员想知道这些听众对这首歌的感受。每秒阅读一条评论,他仍然需要 4 个多月的时间。幸运的是,使用机器学习,他可以自动将每条评论标记为正面或负面。这被称为情绪分析。同样,通过在线评论、调查回复和社交媒体帖子,企业可以获得大量客户反馈。情绪分析对于分析和理解这些数据至关重要。

在本文中,我们将介绍使用 Python 构建情绪分析模型的过程。具体来说,我们将使用 SVM 创建一个词袋模型。通过解释这个模型,我们还可以了解它的工作原理。在此过程中,您将学习文本处理的基础知识。我们将介绍关键的代码片段,您可以在 GitHub2上找到完整的项目。在深入研究所有这些之前,让我们先解释一下什么是情绪分析。
什么是情绪分析?
情绪是某人用语言表达的想法或感觉。考虑到这一点,情绪分析就是预测/提取这些想法或感觉的过程。我们想知道一篇文章的情绪是积极的、消极的还是中性的。我们所说的积极/消极情绪的具体含义取决于我们试图解决的问题。
对于 BTS 示例,我们试图预测听众的观点。积极情绪意味着听众喜欢这首歌。我们可以使用情绪分析来标记我们平台上的潜在仇恨言论。在这种情况下,消极情绪意味着文本包含种族主义/性别歧视观点。其他一些例子包括预测讽刺/挖苦,甚至是预测一个人的意图(即他们是否打算购买产品)。

使用 Python 进行情绪分析
因此,情绪分析模型有很多种。进行情绪分析的方法也有很多种。我们将集中精力应用其中一种方法。即使用 SVM 创建词袋模型。让我们从可以帮助我们做到这一点的 Python 包开始。
包
在第 1-4 行,我们有一些标准包,例如 Pandas/NumPy 来处理我们的数据,以及 Matplotlib/Seaborn 来可视化它。对于建模,我们使用 scikit learn 中的 svm 包(第 6 行)。我们还使用一些指标包(第 7 行)来衡量我们模型的性能。最后一组包用于文本处理。它们将帮助我们清理文本数据并创建模型特征。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import svm
from sklearn.metrics import accuracy_score,confusion_matrix
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
stopwords = stopwords.words('english')
from sklearn.feature_extraction.text import CountVectorizer
数据集
为了训练我们的情绪分析模型,我们使用了 sentiment140 数据集3中的一组推文样本。该数据集包含 160 万条推文,这些推文被归类为具有积极或消极情绪。您可以在表 1 中看到一些示例。

使用下面的代码,我们将加载整个数据集。1,600,000 行数据量很大,尤其是考虑到我们必须清理文本并从中创建特征。因此,为了使事情更易于管理,在第 9 行,我们随机抽取了 50,000 条推文。
# load dataset
data = pd.read_csv(data_path + '/training.1600000.processed.noemoticon.csv',
encoding='latin-1',
header = None,
usecols=[0,5],
names=['target','text'])
# random sample
data = data.sample(n=50000,random_state=100).reset_index(drop=True)
print(len(data))
print(sum(data.target==4))
data.head()
---
50000
24950
target text
0 4 @nicholasmw 1 day u will find that girl worry
1 0 there is nothing on tv and im so desperate to ...
2 0 Very excited that greys is on tonight. Not so ...
3 4 2pm's again and again is a great song. Nichkhu...
4 0 My teeth hurt
文本清理
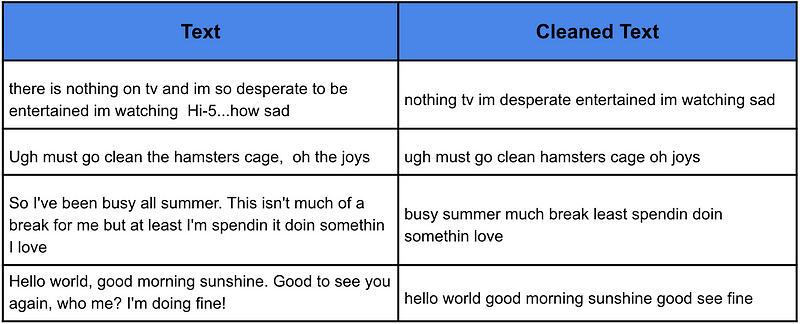
下一步是清理文本。我们这样做是为了删除文本中不重要的部分,并希望使我们的模型更准确。具体来说,我们将文本变为小写并删除标点符号。我们还将从文本中删除非常常见的词,即停用词。
为此,我们创建了下面的函数,该函数接受一段文本,执行上述清理并返回清理后的文本。在第 18 行中,我们将此函数应用于数据集中的每条推文。我们可以在表 2 中看到此函数如何清理文本的一些示例。
def clean_text(text):
"""
Return cleaned text
params
------------
text: string
"""
text = text.lower() # lowercase
tokens = word_tokenize(text)
tokens = [t for t in tokens if not t in stopwords] # remove stopwords
tokens = [t for t in tokens if t.isalnum()] # remove punctuation
text_clean = " ".join(tokens)
return text_clean
text = data['text'][3]
print(text)
clean_text(text)
# clean text
data['text'] = [clean_text(text) for text in data['text']]
---
2pm's again and again is a great song. Nichkhun hwaiting!!!
'2pm great song nichkhun hwaiting'
请注意,所有清理过的推文都是小写,没有标点符号。单词“there”、“is”、“on”、“and”、“so”、“to”、“be”和“how”都已从第一条推文中删除。这些都是停用词的例子。我们预计这些词在正面和负面推文中都很常见。换句话说,它们不会告诉我们有关推文情绪的任何信息。因此,通过删除它们,我们希望留下能够传达情绪的单词。
接下来,重要的是要考虑文本清理将如何影响您的模型。对于某些问题,停用词和标点符号等内容可能很重要。例如,愤怒的顾客可能更有可能使用感叹号!!!如果您不确定,您可以始终将文本清理视为超参数。您可以同时使用停用词和不使用停用词来训练模型,并查看对准确性的影响。
特征工程(词袋)
即使经过清理,与所有 ML 模型一样,SVM 也无法理解文本。这意味着我们的模型无法将原始文本作为输入。我们必须首先以数学方式表示文本。换句话说,我们必须将推文转换为模型特征。一种方法是使用 N-gram。
N-gram 是 N 个连续单词的集合。在图 2 中,我们看到了一个句子如何分解为 1-gram(单字)和 2-gram(双字)的示例。单字只是句子中的单个单词。双字是所有两个连续单词的集合。三字(3-gram)是所有 3 个连续单词的集合,依此类推。您可以通过简单地计算某些 N-gram 出现的次数来以数学方式表示文本。

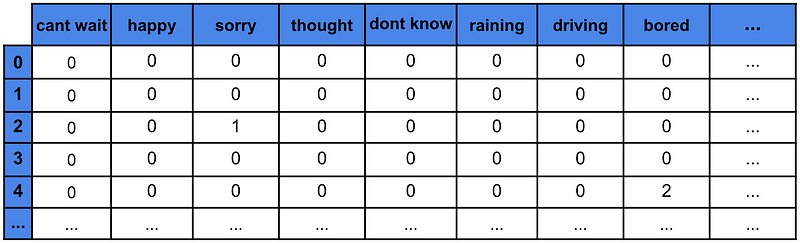
对于我们的问题,我们从推文中选取 1000 个最常见的单元词/二元词。也就是说,我们计算这些 N 元词在清理后的推文语料库中出现的次数,并选取前 1000 个。为了创建模型特征,我们计算这些 N 元词在每条推文中出现的次数。这种方法称为词袋法4。
表 3 给出了使用此方法创建的特征矩阵的示例。顶行给出了 1000 个 N-gram 中的每一个。每条推文都有一个编号行。矩阵中的数字给出了 N-gram 在推文中出现的次数。例如,“抱歉”在推文 2 中出现了一次。本质上,我们将每条推文表示为一个向量。换句话说,我们使用 N-gram 计数对我们的推文进行矢量化。
下面的代码用于创建其中一个特征矩阵。我们首先将数据集分成训练集(80%)和测试集(20%)。在第 6 行中,我们定义了一个 CountVectoriser,它将使用前 1000 个 unigrams/bigrams 对我们的推文进行矢量化。在第 7 行中,我们使用它来对我们的训练集进行矢量化。.fit_transform **()**函数将首先获取 1000 个最常见的 N-gram,然后计算它们在每条推文中出现的次数。
# train test split
train = data[0:40000]
test = data[40000:50000].reset_index(drop=True)
# Create count vectoriser
vectorizer = CountVectorizer(ngram_range=(1, 2), max_features=1000)
# Transform training corpus into feature matrix
X = vectorizer.fit_transform(train['text'])
feature_names = vectorizer.get_feature_names_out()
x_train = pd.DataFrame(data=X.toarray(),columns=feature_names)
y_train = train['target']
我们遵循类似的过程来矢量化我们的测试集。在本例中,我们使用**.transform()**函数。这将使用与训练集相同的列表来计算每个 N-gram 出现的次数。使用相同的 N-gram 列表来矢量化每个集合非常重要。对测试集使用不同的列表会导致模型做出错误的预测。
# Transform testing corpus into feature matrix
X = vectorizer.transform(test['text'])
x_test = pd.DataFrame(data=X.toarray(),columns=feature_names)
y_test = test['target']
最后,我们使用最小-最大缩放来缩放特征矩阵。这可确保所有特征都在同一范围内。这一点很重要,因为 SVM 可能会受到具有较大值的特征的影响。与 N-gram 列表一样,我们以相同的方式缩放两个集合(即使用训练集中的最大值和最小值)。
# Min-Max scalling
x_max = x_train.max()
x_min = x_train.min()
x_train = (x_train - x_min)/x_max
x_test = (x_test - x_min)/x_max
我们使用从训练集中获得的 N-gram 和缩放权重转换了测试集。如上所述,这样做是为了让两个集合以相同的方式矢量化。这样做也是为了避免数据泄露。实际上,我们的模型将用于新的/未见过的推文。这些推文及其 N-gram 和权重在训练期间不可用。因此,为了更好地指示未来的性能,我们的模型应该在被视为未见过的集合上进行测试。
造型
准备好训练集和测试集后,我们就可以训练模型了。 我们将在下面代码的第 2 行中完成这项工作。 在这里,我们在训练集上训练一个 SVM。 具体来说,我们使用一个具有线性核的 SVM,并将惩罚参数设置为 1。在第 5 行,我们使用该模型对测试集进行预测,在第 8 行,我们计算这些预测的准确率。
# fit SVM
model = svm.SVC(kernel='linear', C=1).fit(x_train, y_train)
# get predictions on test set
y_pred = model.predict(x_test)
# accuracy on test set
accuracy = accuracy_score(y_test,y_pred)
print("Accuracy: {}".format(accuracy))
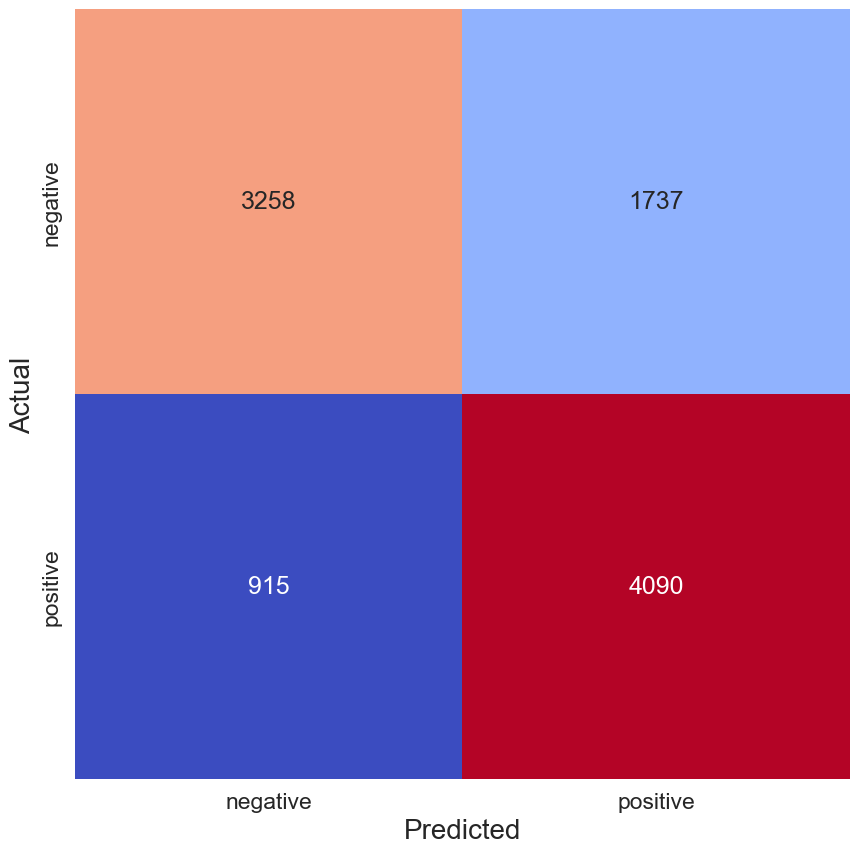
最终,该模型在测试集上的准确率为 73.4%。 我们可以通过图 2 中的混淆矩阵更深入地了解模型的性能。 错误的负面推文有 915 条,而错误的正面推文则有 1737 条。 换句话说,大部分错误是由于模型错误地将具有负面情绪的推文预测为具有正面情绪。 因此,作为初稿,我们的模型还不算太差,但还有很大的改进空间。
# create confusion matrix
conf_matrix = confusion_matrix(y_test,y_pred)
conf_matrix = pd.DataFrame(data = conf_matrix,
columns=['negative','positive'],
index=['negative','positive'])
# plot confusion matrix
plt.figure(figsize=(10, 10), facecolor='w', edgecolor='k')
sns.set(font_scale=1.5)
sns.heatmap(conf_matrix,cmap='coolwarm',annot=True,fmt='.5g',cbar=False)
plt.ylabel('Actual',size=20)
plt.xlabel('Predicted',size=20)
我们可以通过几种方式来提高模型的性能。我们可以花更多时间来调整模型的超参数。如上所述,我们将惩罚参数设置为 1。这实际上是在测试了几个不同的值(即 0.001、0.01、0.1、1 和 10)并查看哪个值具有最高的 k 折交叉验证准确率后选择的。其他超参数(例如内核和文本清理步骤)可以以相同的方式进行调整。我们还可以解释我们的模型,弄清楚它的工作原理并根据这些发现进行更改。

解释我们的模型
解释 SVM 的一种方法是查看模型权重/系数。在训练 SVM 的过程中,训练集中的每个 N-gram 都会被赋予权重。具有正权重的 N-gram 与积极情绪相关。同样,具有负权重的 N-gram 与消极情绪相关。
图 3 显示了 1000 个 N-grams 中 15 个的系数。 前 5 个都具有较高的正向系数。 这是有道理的,因为您可能会认为包含 "yay "或 "drunk "等词的推文会有正面情绪。 同样,系数为负数的单词 “sucks”、"cant " 等都与负面情绪有关。 请注意,也有一些 N-grams 的系数接近于 0。
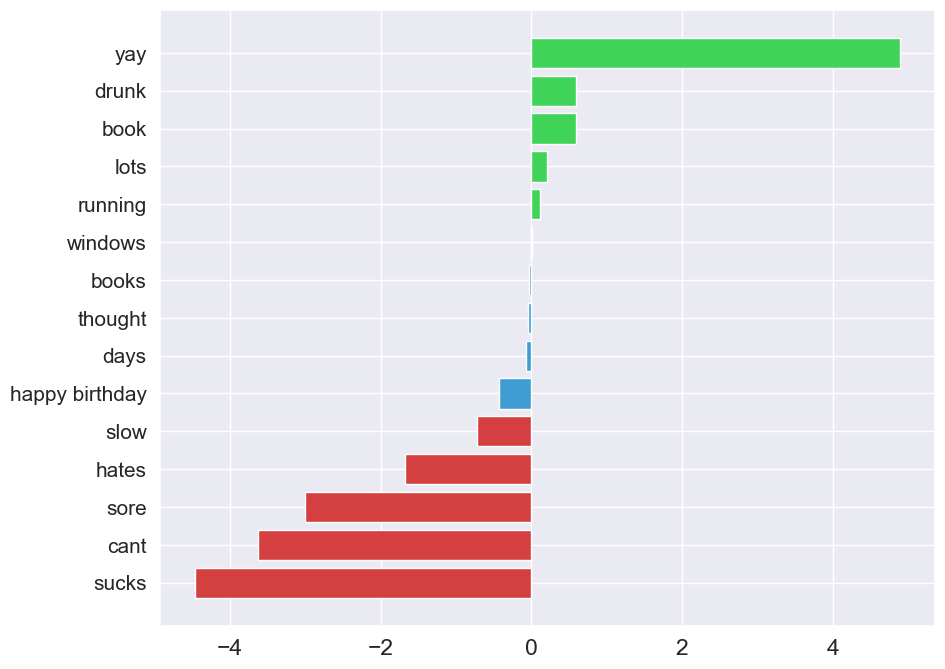
# Create a dataset of model coefs
coef = pd.DataFrame({'feature_names':feature_names, 'coef': model.coef_[0]})
# Get some example coefs
example = coef.loc[[128,988,385,519,769,
845,218,948,191,92,
711,810,388,782,93]
].sort_values('coef')
# Plot coefs
plt.figure(figsize=(10,8))
ticks = range(len(example))
color = ['#d43f3f']*5 + ['#3f9dd4']*5 + ['#3fd458']*5
plt.barh(ticks, example.coef,color=color, align='center')
plt.yticks(ticks, example.feature_names,size=15)
系数较小的 N-gram 不会对我们模型的预测产生太大影响。系数可能很小,因为 N-gram 往往出现在具有积极和消极情绪的推文中。换句话说,它们不会告诉我们有关推文情绪的任何信息。与停用词一样,我们可以删除这些词,并希望提高我们模型的性能。
超参数调整和模型解释是我们提高准确度的众多方法之一。您还可以通过尝试不同的模型(如神经网络)来获得更好的结果。除了词袋模型,您还可以使用更高级的技术(如词嵌入)来矢量化推文。有很多选择,希望本文能为您提供一个良好的起点。
情感分析是自然语言处理 (NLP) 中的一种问题。在下面的文章中,我将带您了解解决另一种问题的过程——语言识别。如果您对 NLP 感兴趣,我建议您阅读它。我们还基于上面解释的许多概念。
使用 DNN 和字符三元组对一段文本的语言进行分类