这是发表在 CVPR 2024 年的一篇文章,其中的一个作者 Tianfan Xue 是香港中文大学的一个老师,之前是谷歌计算摄影团队的研发人员。
这篇文章主要解决 HDR 视频重建的问题,目前的 HDR 场景,无论是拍照还是视频,基本都是要用到多帧融合的方法,拍照因为时间充裕,相对来说更好解决一些,但是对于视频来说,要做到实时还是很有挑战的。所以这篇文章想解决的就是实时的 HDR 视频重建。
Abstract
文章一开始就直接亮出观点,基于不同曝光的 HDR 视频重建问题目前依然存在很多的挑战,尤其是在相机或者场景物体大幅运动的情况下。目前的方法都是利用光流将 LDR 的图像序列进行对齐,然后利用 attention 机制去鬼影。这类方法在处理复杂运动场景的时候,效果不是很好,而且运算的代价很大。为了解决这些问题,文章作者为实时的 HDR 视频重建问题提出了一个鲁棒而且高效的位移场估计器,称为 HDRFlow。HDRFlow 有三个创新的设计点,一个是 HDR 域的对齐 loss (HALoss),一个高效的包含多个尺度的大 kernel 的 flow 网络(MKL),以及一种新的 flow 训练机制。这个 HALoss 可以用于监督 flow 网络去学习一个更准确的 HDR 场景下的 flow 估计,可以对过亮或者过暗场景进行更好的对齐。MKL 的设计,可以让网络以合理的运算代价去有效的对大运动场景建模。此外,文章作者还将仿真数据 Sintel 用于模型的训练,利用仿真数据提供的前向和方向 flow 去监督 flow 网络,让网络的处理效果进一步提升。文章也提到,实验证明 HDRFlow 的效果优于之前的一些方法,同时,文章作者也指出,这是目前第一个可以做到实时运行的 HDR 视频视频模型,在处理 720P 分辨率的输入时,只需要 25ms。
- 图 1

HDRFlow
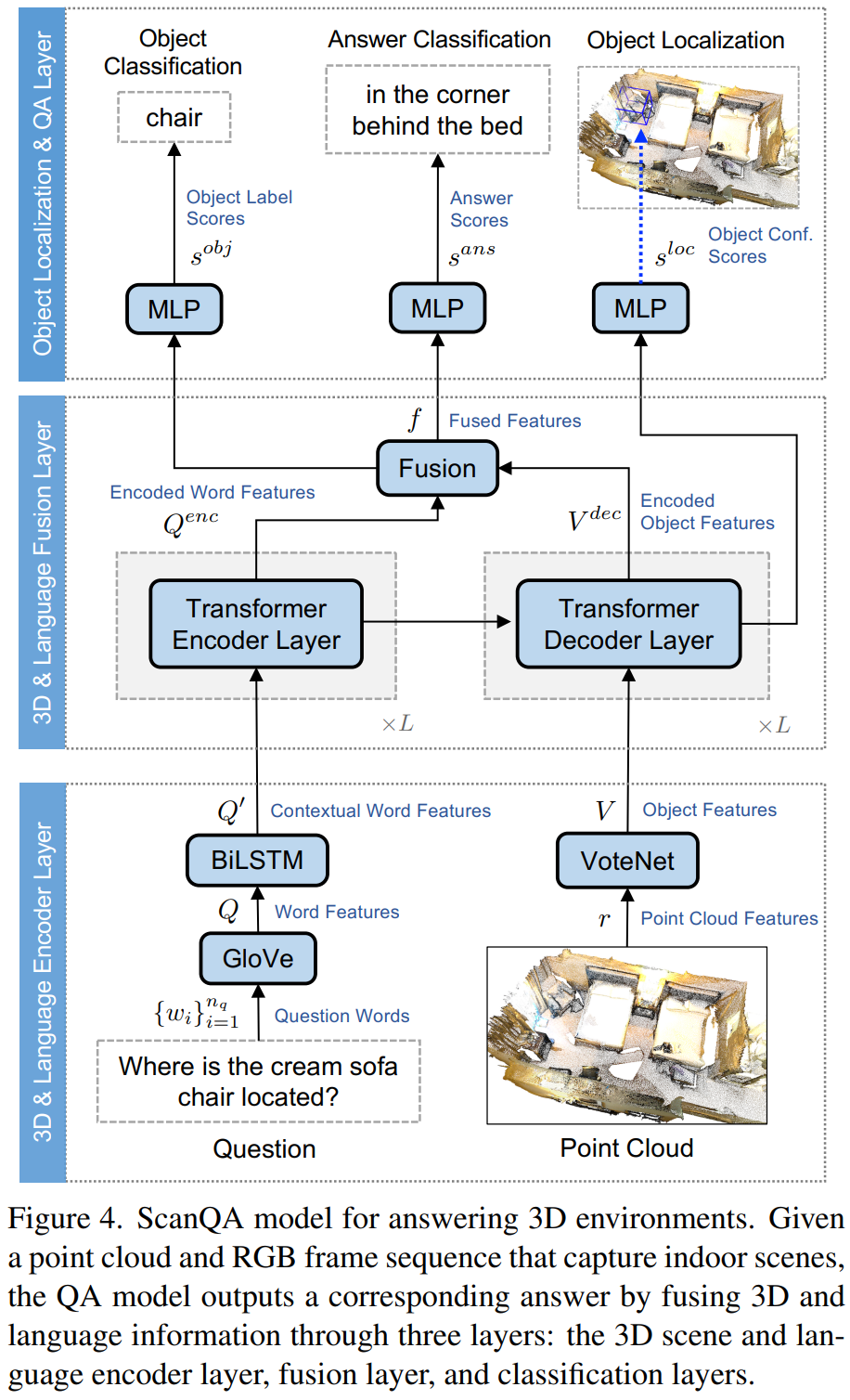
在 HDR 融合场景中,输入的 LDR 视频序列包含多帧不同曝光 { e t } \{e_t\} {et},其中 t = 1 , 2 , . . . n t=1,2,...n t=1,2,...n 的 LDR 图像帧 { L t } \{L_t\} {Lt}。HDR 融合的目标就是用这些 LDR 视频序列得到高质量的 HDR 视频 { H t } \{H_t\} {Ht},文章评估两种典型的多曝光方式,三帧两段曝光 {EV-3, EV+0, EV-3, . . . }, 以及五帧三段曝光 {EV-2, EV+0, EV+2, EV-2, EV+0, . . . },这两种形式,都以中间帧作为参考帧,剩下的帧与参考帧融合以得到 HDR 输出,为了描述方便,文章以三帧两段曝光作为输入进行算法的介绍。
- 图 3

文章的整体算法框架如图 3 所示,整个算法框架包括两个模型,一个是 flow 网络,用于估计位移,另外一个是融合网络。首先,文章输入三帧 LDR 图像帧进入 flow 网络去估计双向的光流,定义为 F t → t − 1 , F t → t + 1 F_{t \rightarrow t-1}, F_{t \rightarrow t+1} Ft→t−1,Ft→t+1。这些光流可以将相邻图像帧 warp 到参考帧的坐标系上。接下来,将 warp 之后的相邻帧,参考帧以及原始的相邻帧在 LDR 域以及 HDR 域的表达形式计算得到,同时输入后面的融合网络进行融合。文章中,将 LDR 图像映射到 HDR 域的表达式如下所示:
I t = L t γ / e t (1) I_{t} = L_{t}^{\gamma} / e_{t} \tag{1} It=Ltγ/et(1)
其中, e t e_t et 表示曝光时间, γ = 2.2 \gamma=2.2 γ=2.2,fusion 融合网络用于估计融合权重,然后将对齐后的 LDR 图像进行融合。
Flow Network with Multi-size Large Kernel
为了将参考帧中缺失的信息进行重建,需要用到其它帧的信息,将相邻帧与参考帧对齐是重建的前提。文章中设计了一个高效的 flow 网络用来估计参考帧到相邻帧之间的 flow 信息。
这个 flow 网络包括一个 encoder 编码器,多尺度的大 kernel 以及一个解码器 decoder。为了平衡运算效率,文章作者将大的卷积 kernel 放在了 encoder 的最后几层,这个 flow 网络是一个单次前向的网络,不需要进行迭代预测,所以这个 flow 网络可以高效地进行双向光流的预测,对于 720P 分辨率的图像,处理耗时大概在 10ms。
- 网络结构

因为不同帧之间的曝光不同,文章将参考帧进行处理,向相邻帧的曝光对齐,这样可以保证两者的亮度尽量一致:
g t + 1 ( L t ) = c l i p ( ( ( L t γ / e t ) e t + 1 ) 1 / γ ) (2) g_{t+1}(L_{t}) = clip \left( ((L_{t}^{\gamma}/e^{t})e^{t+1})^{1/\gamma} \right) \tag{2} gt+1(Lt)=clip(((Ltγ/et)et+1)1/γ)(2)
从这个表达式可以看出,就是将 LDR 图像通过反 gamma 操作,得到线性域的图像,然后对齐曝光系数,然后再做一个 gamma,就得到新曝光下的 LDR 图像。 g t + 1 ( L t ) g_{t+1}(L_{t}) gt+1(Lt) 表示参考帧做完曝光对齐之后的图像,然后把 L t − 1 , g t + 1 ( L t ) , L t + 1 L_{t-1}, g_{t+1}(L_{t}), L_{t+1} Lt−1,gt+1(Lt),Lt+1 输入 flow 网络。flow 网络的 encoder 部分包含两个子网络,一个用于构建 feature map 金字塔,另外一个用于构建图像金字塔。feature map 金字塔包括 8 个残差模块,四个尺度 1/2, 1/4, 1/8, 1/16,每个尺度两个残差模块。图像金字塔通过 pooling 操作,将 LDR 图像逐渐下采样,然后在每个尺度上,feature map 与下采样的图像进行 concatenate。最终得到的 flow feature 的尺寸是 H/16 X W/16 X 256,这些 flow feature 再通过大 kernel 进行卷积处理。
flow 网络的解码器部分包括两个上采样模块以及一个 flow head。上采样到原始输入的 1/4 时,flow head 预测双向的光流信息,这个时候得到光流也是 1/4,文章通过双线性插值上采样到和原始图像大小,最终的光流图称为: F t → t − 1 , F t → t + 1 F_{t \rightarrow t-1}, F_{t \rightarrow t+1} Ft→t−1,Ft→t+1,基于这个光流信息,相邻的两帧可以与参考帧进行对齐: L ~ t − 1 → t , L ~ t + 1 → t \tilde{L}_{t-1 \rightarrow t}, \tilde{L}_{t+1 \rightarrow t} L~t−1→t,L~t+1→t
文章也借鉴了之前一些做分割以及检测的工作,将大尺度的 kernel 用于这个模型中,文章用了三个尺度 7x7, 9x9, 11x11,用 depthwise attention 的方式对 feature map 进行处理,然后再 concatenate 起来。
HDR-domain Alignment Loss
为了重建高质量,没有伪纹理的 HDR 视频,准确的对齐是非常重要的,文章中引入了一种 photometric consistency 损失函数对 flow net 进行监督,不过 LDR 图像因为曝光不同,本身就有不同的亮度,这个与 photometric consistency 的假设相冲突。
为了处理亮度上的差异,文章作者提出了一种 HDR 域的对齐损失函数,这个损失函数可以更为鲁棒地处理不同帧之间的亮度差异。在训练的时候,LDR 图像帧是从 HDR 帧退化得到的,HDR 帧本身没有亮度差异,所以可以用 HDR 帧直接计算光度一致性损失函数。换句话说,flow 网络基于 LDR 图像预测位移场,然后将预测得到的位移场,对 HDR 图像进行 warp,然后用 warp 后的 HDR 图像计算 photometric consistency 损失函数,为了得到更好的主观质量,文章在计算 photometric consistency 之前,先将 HDR 图像用如下的表示式进行变换:
T ( H ) = log ( 1 + μ H ) log ( 1 + H ) (4) \mathcal{T}(H) = \frac{\log(1 + \mu H)}{\log(1 + H)} \tag{4} T(H)=log(1+H)log(1+μH)(4)
其中, μ = 5000 \mu = 5000 μ=5000
所以,给定训练数据中的 HDR 图像帧, H t − 1 , H t , H t + 1 H_{t-1}, H_t, H_{t+1} Ht−1,Ht,Ht+1 以及退化得到对应的 LDR 图像帧 L t − 1 , L t , L t + 1 L_{t-1}, L_t, L_{t+1} Lt−1,Lt,Lt+1,通过 LDR 图像帧,先计算出 flow 图, F t → t − 1 , F t → t + 1 F_{t \rightarrow t-1}, F_{t \rightarrow t+1} Ft→t−1,Ft→t+1,基于这些 flow 图,对 HDR 图像帧计算 photometric consistency,如下图所示:
L t , t − 1 p h o t o = ∥ T ( H t ) − W ( T ( H t − 1 ) , F t → t − 1 ) ∥ 1 L t , t + 1 p h o t o = ∥ T ( H t ) − W ( T ( H t + 1 ) , F t → t + 1 ) ∥ 1 L H A = ( 1 − M t ) ⊙ ( L t , t − 1 p h o t o + L t , t + 1 p h o t o ) (5) \mathcal{L}_{t, t-1}^{photo} = \left \| \mathcal{T}(H_t) - \mathcal{W}(\mathcal{T}(H_{t-1}), F_{t \rightarrow t-1} ) \right \|_{1} \\ \mathcal{L}_{t, t+1}^{photo} = \left \| \mathcal{T}(H_t) - \mathcal{W}(\mathcal{T}(H_{t+1}), F_{t \rightarrow t+1} ) \right \|_{1} \\ \mathcal{L}_{HA} = (1 - M_{t}) \odot (\mathcal{L}_{t, t-1}^{photo} + \mathcal{L}_{t, t+1}^{photo}) \tag{5} Lt,t−1photo=∥T(Ht)−W(T(Ht−1),Ft→t−1)∥1Lt,t+1photo=∥T(Ht)−W(T(Ht+1),Ft→t+1)∥1LHA=(1−Mt)⊙(Lt,t−1photo+Lt,t+1photo)(5)
其中, W \mathcal{W} W 表示 warp 操作, M M M 表示一个掩码 mask,表示参考帧中曝光良好的区域,为了识别出这些曝光良好的区域,文章将 LDR 图像 L t L_t Lt 先转换到 YCbCr 颜色空间,然后基于亮度通道 Y 进行计算, M t M_t Mt 定义为 δ l o w < Y < δ h i g h \delta_{low} < Y < \delta_{high} δlow<Y<δhigh,文章作者认为,这个网络主要是把参考帧中曝光不好的区域用相邻帧的信息进行融合,所以这个 HA 损失函数也是聚焦在这些区域,让网络对这些区域计算更准的光流 flow,以融合相邻帧的信息。
Fusion Network
融合网络的目标,是从参考帧,对齐后的相邻帧,以及原始的相邻帧中融合得到一张高质量的 HDR 图像。在 LDR 的参考帧中,静态场景或者运动物体都有可能存在过曝或者欠曝的情况。文章作者认为,对齐后的相邻帧可以对动态场景做出贡献,而原始的相邻帧可以对静态场景进行补偿,所以文章中融合网络的输入是既包含了原始的图像帧,也包含对齐后的图像帧。
文章中的融合网络是一个 U 型的网络结构,中间有跳连,包括三层下采样,以及三层上采样,最终网络输出的是各图像的融合权重,最终的 HDR 图像是输入图像的加权融合:
H ^ t = w 0 I t + w 1 I ~ t − 1 → t + w 2 I ~ t + 1 → t + w 3 I t − 1 + w 4 I t + 1 ∑ j = 0 4 w j (6) \hat{H}_t = \frac{w_0I_{t} + w_1 \tilde{I}_{t-1 \rightarrow t} + w_2 \tilde {I}_{t+1 \rightarrow t} + w_3 I_{t-1} + w_4 I_{t+1} }{\sum_{j=0}^{4}w_j} \tag{6} H^t=∑j=04wjw0It+w1I~t−1→t+w2I~t+1→t+w3It−1+w4It+1(6)
Training Scheme and Loss
文章也提到,之前的很多工作都是基于真实的视频进行训练,文章作者认为之前的这些真实视频,可能缺乏大运动的场景,所以文章也用到了一个仿真数据集,Sintel 以补偿场景的多样性。最终的总体 loss 函数,包含了重建 loss,flow loss 以及 HA loss 函数,其中的 flow loss 函数只有仿真数据集才有,这些 loss 的定义如下所示:
L r e c = ∥ T ( H ^ t ) − T ( H t g t ) ∥ 1 (7) \mathcal{L}_{rec} = \left \| \mathcal{T}(\hat{H}_t ) - \mathcal{T}(H_{t}^{gt}) \right \|_1 \tag{7} Lrec= T(H^t)−T(Htgt) 1(7)
L f l o w = ∥ F t → t − 1 − F t → t − 1 g t ∥ 1 + ∥ F t → t + 1 − F t → t + 1 g t ∥ 1 (8) \mathcal{L}_{flow} = \left \| F_{t \rightarrow t-1} - F_{t \rightarrow t-1}^{gt} \right \|_1 + \left \| F_{t \rightarrow t+1} - F_{t \rightarrow t+1}^{gt} \right \|_1 \tag{8} Lflow= Ft→t−1−Ft→t−1gt 1+ Ft→t+1−Ft→t+1gt 1(8)
L t o t a l = λ 1 L r e c + λ 2 L H A + λ 3 L f l o w (9) \mathcal{L}_{total} = \lambda_{1}\mathcal{L}_{rec} + \lambda_{2}\mathcal{L}_{HA} + \lambda_{3}\mathcal{L}_{flow} \tag{9} Ltotal=λ1Lrec+λ2LHA+λ3Lflow(9)
其中 λ 1 = 1 , λ 2 = 0.5 , λ 3 = 0.001 \lambda_1 = 1, \lambda_2 = 0.5, \lambda_3 = 0.001 λ1=1,λ2=0.5,λ3=0.001
文章中提到的测试平台是基于 NVIDIA 3090 GPU 做的,在这个硬件设置下,推理速度可以达到 25ms 每帧,基本做到实时。



![[<span style='color:red;'>论文</span><span style='color:red;'>阅读</span>]DETR](https://img-blog.csdnimg.cn/direct/e8df1ed8695749d1b661ff6ad6833838.png)
![[<span style='color:red;'>论文</span><span style='color:red;'>阅读</span>]BEVFusion](https://img-blog.csdnimg.cn/direct/65697d2df3dc47d2a67baf3c2e53c330.png)