文章目录
Elasticsearch核心原理介绍
一、基本概念
1、集群(cluster)
一个Elasticsearch集群由一个或多个Elasticsearch节点组成,所有节点共同存储数据。每个集群都应有一个唯一的集群名(ClusterName),同一环境内如果存在同名集群,可能会出现不可知异常。
2、节点(node)
一个节点是集群中的一个服务器,用来存储数据并参与集群的索引和搜索。一个集群可以拥有多个节点,每个节点可以扮演不同的角色:
- 数据节点:存储索引数据的节点,主要对文档进行增删改查、聚合等操作。
- 专有主节点:对集群进行操作,例如创建或删除索引,跟踪哪些节点是集群的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集群的健康非常重要,默认情况下集群中的任一节点都可能被选为主节点。
- 协调节点:分担数据节点的CPU开销,从而提高处理性能和服务稳定性。
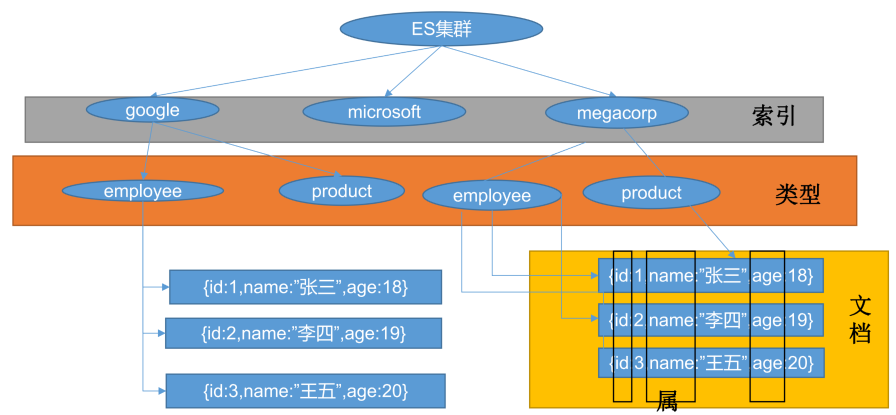
3、索引(index)
一个索引是一个拥有一些相似特征的文档的集合,相当于关系型数据库中的一个数据库。例如,用户可以拥有一个客户数据的索引,一个商品目录的索引,以及一个订单数据的索引。一个索引通常使用一个名称(所有字母必须小写)来标识,当针对这个索引的文档执行索引、搜索、更新和删除操作的时候,这个名称被用来指向索引。
4、类型(type)
一个类型通常是一个索引的一个逻辑分类或分区,允许在一个索引下存储不同类型的文档,相当于关系型数据库中的一张表,例如用户类型、博客类型等。由于6.x以后的Elasticsearch版本已经不支持在一个索引下创建多个类型,因此类型概念在后续版本中不再被提及。Elasticsearch 5.x允许在一个索引下存储不同类型的文档,Elasticsearch 6.x在一个索引下只允许一个类型,Elasticsearch 7.x索引类型命名只允许_doc,Elasticsearch 8.x不再有索引类型的概念。
5、映射(mapping)
mapping用来定义一个文档以及其所包含的字段如何被存储和索引,相当于关系型数据库中的Schema,例如在mapping中定义字段的名称和类型,以及所使用的分词器。
Elasticsearch与关系型数据库的映射关系如下表所示:

二、 Elasticsearch架构
Elasticsearch的架构是一个高度可扩展、分布式、基于Lucene构建的开源搜索和分析引擎。

三、 Elasticsearch全文搜索
现实中的数据分为结构化数据和非结构化数据,结构化数据主要通过关系型数据库进行存储和管理。非结构化数据又称为全文数据,包括各类文本、文档或者图片等。
非结构化数据的搜索有两种方式:
1、顺序扫描
按照顺序查找特定的关键字,这种方式是最低效的。
2、全文搜索
将非结构化数据中的部分数据提取出来变成有结构的,然后按照一定结构的数据再进行搜索。
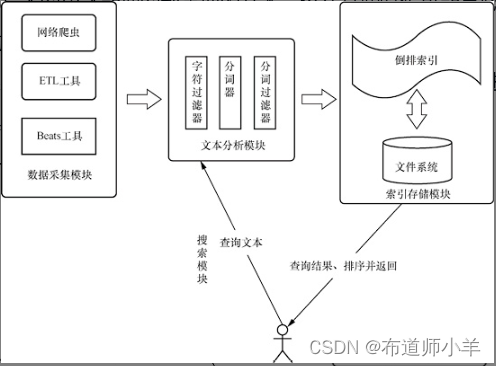
因此,全文搜索可以对每个词建立一个索引,指明该词在文本中出现的次数和位置。当用户查询时,根据事先建立的索引进行查找,并返回查找到的结果。
什么是Lucene
- Elasticsearch是以Lucene为底层基础建立的开源全文搜索引擎,Lucene是现在最好的开源全文检索引擎工具,但是Lucene只是一个工具包,并不是一个完整的全文搜索引擎。
- Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
倒排索引
Lucene能够实现全文搜索主要是因为实现了倒排索引的查询功能。倒排索引和正向索引不同,它不是由记录来确定属性的值而是由属性值来确定记录的位置。
倒排索引包含两个部分:
1、单词词典(Term Dictionary)
记录所有文档的单词,记录单词倒排列表的关联关系。
- 单词词典内每条索引项记载单词本身的信息以及指向“倒排列表”的指针。
- 单词词典一般比较大,可以通过B+树或者哈希拉链法实现,以满足高性能的插入与查询。
2、 倒排列表(Posting List)
记录了单词对应的文档结合,由倒排索引组成。倒排索引项包含:文档ID,词频TF(该单词在文档中出现的次数,用于相关性评分),位置(Position,单词在文档中分词的位置。用于语句搜索(phrase query)),偏移(Offset,记录单词的开始结束位置,实现高亮显示)。
假如有以下两段文字,通过分词器将文档的内容拆分成单独的词,再创建倒排索引。
Java is the best programming language.
Python is the best programming language. 以上内容可以转换为以下的倒排索引信息
关键词 |
文章编号 |
出现频率 |
出现位置 |
Java |
1 |
1 |
0 |
Python |
2 |
1 |
0 |
is |
1/2 |
1/1 |
5/7 |
the |
1/2 |
1/1 |
8/10 |
best |
1/2 |
1/1 |
12/14 |
programming |
1/2 |
1/1 |
17/19 |
language |
1/2 |
1/1 |
28/31 |
上表转换为倒排索引的图形结构信息

倒排索引有个很重要的特性是被写入磁盘后是不可改变的:它永远不会修改。
不变性有重要的价值:
- 不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
- 一旦索引被读入内核的文件系统缓存,便会留在那里,由于其不变性。只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
- 其它缓存(像filter缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化。
- 写入单个大的倒排索引允许数据被压缩,减少磁盘I/O 和需要被缓存到内存的索引的使用量。
不变索引的缺点就是它是不可变的,不能修改它。如果需要让一个新的文档可被搜索,需要重建整个索引。
问题总结:
1、Lucene是什么,和Elasticsearch什么关系?
- Lucene是一个开源全文检索引擎工具,只是一个工具包,并不是一个完整的全文搜索引擎。
- Elasticsearch是以Lucene为底层基础建立的开源全文搜索引擎
2、 倒排索引有哪些特点?
- 先分词
- 单词与文档构建对应信息
- 具有不变性
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨