1.1-1.7部分转载至博客:
(2)什么是LASSO回归,怎么看懂LASSO回归的结果-CSDN博客
Lasso回归(Least Absolute Shrinkage and Selection Operator,最小绝对收缩和选择算子回归),是一种在统计学中广泛使用的回归分析方法。其核心在于通过对系数进行压缩,以达到变量选择和复杂度调整的目的,从而提高模型的预测精度和解释能力。Lasso回归在处理具有多重共线性数据或者高维数据时尤其有效。简单来说就是其可以在模型中删除不必要的特征或参数,使模型更简单,从而避免过拟合,以下是一个不严谨的示意图:
 1 基本概念
1 基本概念
1.1 Lasso回归的起源和动机
Lasso回归由Robert Tibshirani在1996年提出,主要是为了解决传统线性回归在处理高维数据时遇到的问题。在高维空间中,传统的最小二乘法回归(OLS)会出现变量选择困难、模型过拟合等问题。Lasso通过引入一个调整参数(λ),对系数的绝对值进行惩罚,迫使一些不重要的系数值变为零,这样不仅能自动选择重要的特征,还能有效控制模型的复杂度。
1.2 数学表达
 1.3 参数λ的影响
1.3 参数λ的影响
Lasso回归中的λ是一个关键的参数,其值的大小直接影响到最终模型的表现。当λ为0时,Lasso回归就退化为普通的最小二乘回归。随着λ值的增加,越来越多的系数被压缩为零,这有助于特征选择和降低模型复杂度。然而,如果λ过大,它可能会导致模型过于简单,从而影响模型的预测能力。因此,选择一个合适的λ值是实现最佳模型性能的关键。
1.4 Lasso的计算方法
Lasso问题的求解通常使用坐标下降法(Coordinate Descent),梯度下降法(Gradient Descent)或者最小角回归法(Least Angle Regression, LAR)等算法。这些算法通过迭代优化来逐渐逼近最优解。
1.5 Lasso与Ridge回归的比较
Lasso回归与Ridge回归都是正则化的线性模型。不同之处在于Ridge回归使用L2惩罚项(系数的平方和)进行正则化,而Lasso使用L1惩罚项。L2惩罚倾向于让系数值接近于零但不会完全等于零,适合处理变量间存在较强相关性的情况;而L1惩罚会使某些系数完全为零,从而实现特征的选择。
1.6 Lasso的优点和缺点
优点:
能有效处理参数的多重共线性问题。
通过稀疏解,自动进行变量选择,简化模型。
适合用于解析高维数据,其中特征数可能大于样本数。
缺点:
当变量数远多于样本数时,Lasso可能不稳定。
无法进行群体选择,即相关的变量不会一起被选入或剔除。
1.7 应用领域
由于其变量选择和复杂度控制的能力,Lasso回归被广泛应用于诸如生物信息学、金融分析、工业工程等领域,尤其在处理大规模数据集时显示出其优势。
总结来说,Lasso回归是一种强大的统计工具,它通过引入L1正则化惩罚项,帮助构建更简洁、更易解释的模型。正确地选择λ值和理解模型如何通过约束系数来控制复杂度,是使用Lasso回归进行数据分析和预测的关键。
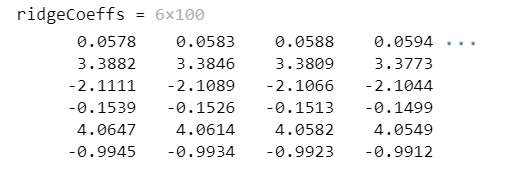
2 LASSO回归结果的解读
Lasso模型会输出两张图:回归系数路径图(A)和交叉验证曲线图(B),图来源于文章
Zhou D, Liu X, Wang X, Yan F, Wang P, Yan H, Jiang Y, Yang Z. A prognostic nomogram based on LASSO Cox regression in patients with alpha-fetoprotein-negative hepatocellular carcinoma following non-surgical therapy. BMC Cancer. 2021 Mar 8;21(1):246. doi: 10.1186/s12885-021-07916-3IF: 3.4 Q2 . PMID: 33685417IF: 3.4 Q2 ; PMCID: PMC7938545IF: 3.4 Q2 .

图A是回归系数路径图。该文章中纳入了23个变量,便有23条不同颜色的线。每条线上都有变量编号。即每一条曲线代表了每一个自变量系数的变化轨迹,纵坐标是系数的值,下横坐标是log(λ),上横坐标是此时模型中非零系数的个数。我们可以看到,随着参数log λ增大,回归系数(即纵坐标值)不断收敛,最终收敛成0。例如,最上面那条代表的自变量12在λ值很大时就有非零的系数,然后随着λ值变大不断变小。

图B是LASSO回归的交叉验证曲线。X轴是惩罚系数的对数 logλ,Y轴是似然偏差,Y轴越小说明方程的拟合效果越好。最上面的数字则为不同λ时,方程剩下的变量数。图上打了黄色和绿色标签的两条虚线,代表两个特殊的lambda(λ)值。左边虚线为λ min,意思是偏差最小时的λ ,代表在该lambda取值下,模型拟合效果最高。变量数是16,相比λ-se,保留下来的变量更多。右边虚线为λ-se,意思是最小λ右侧的1个标准误。在该λ取值下,构建模型的拟合效果也很好,同时纳入方程的个数更少,模型更简单。因此,临床上一般会选择右侧的λ1-se作为最终方程筛选标准。从上图可以看到,本方程λ-se对应的变量数量是5,所以最终纳入了5个变量进入方程。至于是哪5个,在用软件具体分析的时候会有展示,系数不为0的就是最终纳入的变量。
3 实操练习
空了来补上。。。。暂时还在编码中