表定义:
create table if not exists liuliang_detail
(
user_id string comment ''
,record_time string comment 'yyyymmdd hh:mi:ss'
)
comment '流量明细表'
;
方法一:
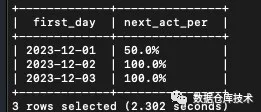
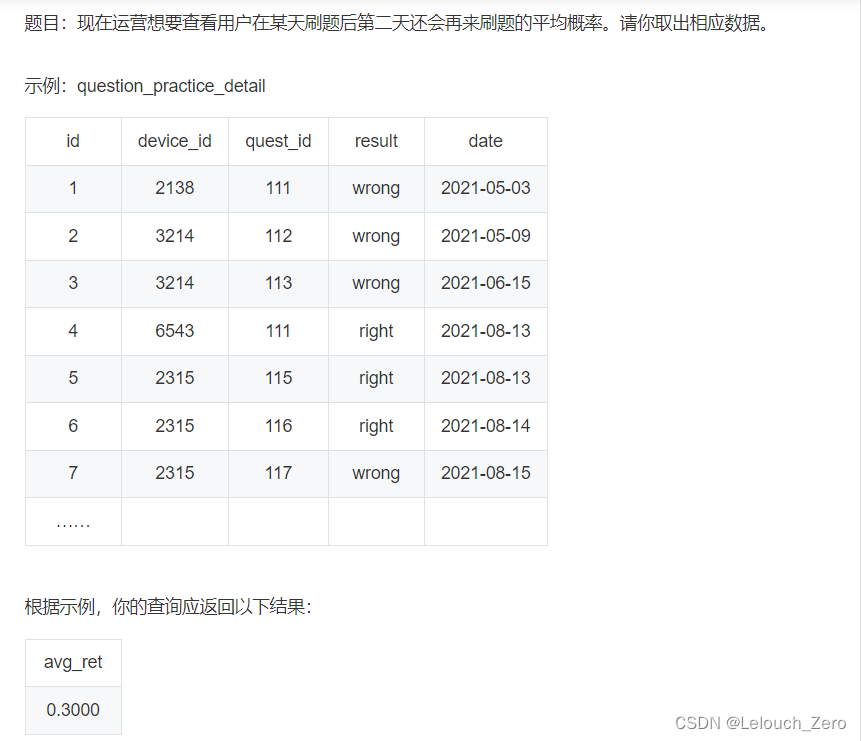
计算的是整段时间范围内,每一天为基准的所有的留存1、2、7天的用户数。
方法一的优势是可以一次性计算出,每天的不同时间范围的留存率。
但是不是很直观,并且计算量比较大。
# 按照用户的访问时间进行排序
create table if not exists liuliang_partition as
select a.user_id
,a.record_time
,row_number() over(partition by user_id order by record_time) rn_asc
--,row_number() over(partition by user_id order by recordtime desc) rn_des
from liuliang_detail a
where date(record_time) >= '2021-01-01' -- 最好根据产品上线时间确定,要不然流量表太大,影响运行效率
;
# 计算整段时间范围内,以每天为基准的的留存率
select recorddate
,count(distinct user_id) total_uv
,count(distinct case when rn_asc = 1 then user_id else null end) new_uv -- 首次访问uv
,round(100*count(distinct case when rn_asc = 1 then user_id else null end)/count(distinct user_id), 1) new_uv_ratio -- 首次访问uv占比
,count(distinct case when rn_asc <> 1 and diff_days = 1 then user_id else null end) lastday_uv -- 次日留存
,count(distinct case when rn_asc <> 1 and diff_days = 2 then user_id else null end) last2day_uv -- 2日留存
,count(distinct case when rn_asc <> 1 and diff_days = 3 then user_id else null end) last3day_uv -- 3日留存
,count(distinct case when rn_asc <> 1 and diff_days = 4 then user_id else null end) last4day_uv -- 4日留存
,count(distinct case when rn_asc <> 1 and diff_days = 5 then user_id else null end) last5day_uv -- 5日留存
,count(distinct case when rn_asc <> 1 and diff_days = 6 then user_id else null end) last6day_uv -- 6日留存
,count(distinct case when rn_asc <> 1 and diff_days = 7 then user_id else null end) last7day_uv -- 7日留存
,count(distinct case when rn_asc <> 1 and diff_days = 14 then user_id else null end) last14day_uv -- 14日留存
,count(distinct case when rn_asc <> 1 and diff_days = 30 then user_id else null end) last30day_uv -- 30日留存
from
(
select a.*
,date(record_time) recorddate
,datediff(cast(a.record_time as date), cast(b.record_time as date)) diff_days -- 留存天数
from liuliang_partition a
left join liuliang_partition b on a.user_id = b.user_id and a.rn_asc = b.rn_asc+1
) x
group by recorddate;方法二:
计算的是用户首次登陆时间为基准时间,计算该基准时间之后的n日留存率。
优点:代码直观好理解
缺点:如果要计算n天留存需要增加代码量
-- 计算次日留存率
WITH FirstLogin AS (
-- 找出每个用户的首次登录时间
SELECT
user_id,
MIN(record_time) AS first_record_time
FROM
user_log
GROUP BY
user_id
),
RetentionUsers AS (
-- 找出次日登录的用户
SELECT
a.user_id,
a.record_time,
DATE_ADD(b.first_record_time, INTERVAL 1 DAY) AS expected_next_day
FROM
user_log a
JOIN
FirstLogin b ON a.user_id = b.user_id
WHERE
DATE(a.record_time) = DATE(expected_next_day)
)
-- 计算留存率
SELECT
COUNT(DISTINCT RetentionUsers.user_id) AS next_day_retention_users,
COUNT(DISTINCT FirstLogin.user_id) AS initial_users,
ROUND(COUNT(DISTINCT RetentionUsers.user_id) / COUNT(DISTINCT FirstLogin.user_id) * 100, 2) AS next_day_retention_rate
FROM
FirstLogin
LEFT JOIN
RetentionUsers ON FirstLogin.user_id = RetentionUsers.user_id;


























![[人工智能]对未来建筑行业的影响](https://i-blog.csdnimg.cn/direct/9e2acfa9ae8d4d5d97c2effe055e7c31.png#pic_center.png)