文章目录
CountDownLatch
CountDownLatch:同步等待多个线程完成任务的并发组件
CountDownLatch:同步等待多个线程完成任务的并发组件
CountDownLatch 是 Java 并发库中提供的一种非常有用的工具类,用于使一个或多个线程等待其他线程完成一组操作。它通过一个计数器来实现这一功能,初始计数器被设置为一个特定的值,每当一个线程完成自己的任务后,就将计数器减一,直至计数器到达零,所有等待的线程将被释放,继续执行后续的操作。
主要特点:
- 一次性:
CountDownLatch只能使用一次,一旦计数器到达零,就不能再次使用。如果需要多次等待,需要创建新的实例。 - 不可重置:计数器一旦递减,不能重新设置。这意味着如果需要重复使用,必须创建新的
CountDownLatch实例。 - 非公平性:
CountDownLatch不保证等待线程的释放顺序,当计数器到达零时,所有等待线程都会被同时唤醒。
常用方法:
CountDownLatch(int count):构造函数,初始化计数器的值。await():使当前线程等待,直到计数器到达零,或者当前线程被中断。await(long timeout, TimeUnit unit):使当前线程等待,直到计数器到达零,或者等待时间超过指定的超时时间,或者当前线程被中断。countDown():将计数器减一,表示一个参与者已完成任务。
使用示例:
假设我们有一个主程序,需要等待一组子线程完成各自的任务后,才能继续执行后续操作。可以使用 CountDownLatch 来实现这一功能。
import java.util.concurrent.CountDownLatch;
public class CountDownLatchExample {
public static void main(String[] args) throws InterruptedException {
// 创建 CountDownLatch 实例,计数器初始值设为 3,意味着有 3 个子线程需要完成任务
CountDownLatch latch = new CountDownLatch(3);
// 启动 3 个子线程
for (int i = 0; i < 3; i++) {
new Thread(() -> {
// 模拟子线程执行耗时操作
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("子线程完成任务");
// 子线程完成任务后,调用 countDown 减少计数器的值
latch.countDown();
}).start();
}
// 主线程等待所有子线程完成
latch.await();
System.out.println("所有子线程已完成任务,主线程继续执行...");
}
}
在这个示例中,主线程会调用 latch.await() 方法等待,直到所有的子线程都调用了 latch.countDown() 方法,将计数器从初始的 3 减至 0,此时主线程才会继续执行后续的代码。
总结
CountDownLatch 是 Java 并发编程中一个非常实用的工具,它可以帮助我们轻松地实现线程间的同步等待,特别适用于需要等待一组操作全部完成的场景。通过合理运用 CountDownLatch,可以有效地提高多线程程序的健壮性和效率。
CountDownLatch源码剖析之如何基于AQS实现同步阻塞等待
CountDownLatch源码剖析:基于AQS实现同步阻塞等待
CountDownLatch 是Java并发库中的一个重要组件,它主要用于同步多个线程的执行流程,直到所有参与的线程完成特定操作。CountDownLatch 的核心是基于 AbstractQueuedSynchronizer (AQS) 实现的,AQS 是Java并发包中一个抽象框架,用于构建各种同步组件,如 Semaphore, ReentrantLock 等。
AQS简介
AQS 定义了一套多线程访问共享资源的框架,主要包含两部分:同步器状态和等待队列。AQS 中的同步器状态是一个整型的 volatile 变量,用于表示资源的独占状态。等待队列是一个 FIFO 的线程队列,当线程尝试获取资源失败时,会被插入到等待队列中,并阻塞等待。
CountDownLatch结构
CountDownLatch 内部维护了一个 Sync 类,继承自 AQS,用于管理同步状态。CountDownLatch 的核心在于计数器 count 的管理,当 count 降为零时,所有等待的线程将被释放。
核心源码分析
Sync类定义:private static final class Sync extends AbstractQueuedSynchronizer { private static final long serialVersionUID = 4982264981921886391L; Sync(int count) { setState(count); } int getCount() { return getState(); } protected boolean tryAcquireShared(int acquires) { return (getState() == 0); } protected boolean tryReleaseShared(int releases) { // Decrement count; signal when transition to zero for (;;) { int c = getState(); if (c == 0) return false; int nextc = c-1; if (compareAndSetState(c, nextc)) return nextc == 0; } } }构造函数:
public CountDownLatch(int count) { if (count < 0) throw new IllegalArgumentException("count < 0"); this.sync = new Sync(count); }构造函数初始化
Sync对象,设置同步状态为count。await方法:public void await() throws InterruptedException { sync.acquireSharedInterruptibly(1); }await方法调用AQS的acquireSharedInterruptibly方法,尝试获取共享模式下的资源。如果当前count大于零,线程将被阻塞。countDown方法:public void countDown() { sync.releaseShared(1); }countDown方法调用AQS的releaseShared方法,尝试释放共享模式下的资源,即减少count的值。如果count降为零,所有等待的线程将被唤醒。
总结
CountDownLatch 通过 AQS 的共享模式实现线程的同步等待。当计数器 count 的值大于零时,任何调用 await 方法的线程都会被阻塞,直到 count 降为零,所有等待的线程才被释放。countDown 方法负责减少 count 的值,当最后一个线程调用 countDown 使 count 降为零时,所有等待的线程将被唤醒,继续执行后续操作。
这种实现方式充分利用了 AQS 的同步机制,提供了简单而强大的线程同步功能。
CyclicBarrier
CyclicBarrier:将工作任务给多线程分而治之的并发组件
CyclicBarrier:多线程协作的并发组件
CyclicBarrier 是 Java 并发工具包 (java.util.concurrent) 中的一个类,用于帮助多个线程在执行过程中同步。它特别适合于“分而治之”的场景,即一个大任务被分解成若干个小任务,分别由多个线程并行处理,当所有小任务完成后,再集中处理这些结果,或者执行下一个阶段的任务。
主要特性
固定参与者数量:创建
CyclicBarrier时,需要指定一个固定数量的参与者。当所有参与者都到达了屏障点,所有线程才会被释放,继续执行后续任务。可重用性:与
CountDownLatch不同,CyclicBarrier在所有参与者通过后可以被重用,即它可以循环使用,直到程序显式地关闭它。屏障动作:在创建
CyclicBarrier时,可以传入一个Runnable接口的实例,称为“屏障动作”。当所有参与者都到达屏障时,会先执行这个动作,然后再释放所有线程。异常处理:如果在
await方法中任何一个参与者抛出了异常,那么所有等待的参与者都将被中断,屏障将重置。
使用场景
CyclicBarrier 适用于以下几种场景:
- 并行计算:多个线程并行处理数据的不同部分,当所有线程完成时,集中处理结果。
- 多阶段任务:任务分为多个阶段,每个阶段由多个线程并行执行,每个阶段结束后,所有线程在屏障处等待,直到所有线程到达,再一起进入下一个阶段。
- 数据收集:多个线程收集数据,然后在所有数据收集完毕后,进行统一处理。
基本使用
以下是使用 CyclicBarrier 的一个基本示例:
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
public class CyclicBarrierExample {
public static void main(String[] args) {
int numberOfThreads = 3;
CyclicBarrier barrier = new CyclicBarrier(numberOfThreads, () -> {
System.out.println("所有线程都已经到达屏障,现在执行下一步...");
});
for (int i = 0; i < numberOfThreads; i++) {
new Thread(() -> {
System.out.println("线程 " + Thread.currentThread().getName() + " 正在执行...");
try {
// 模拟一些耗时操作
Thread.sleep(1000);
barrier.await(); // 等待所有线程到达屏障
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println("线程 " + Thread.currentThread().getName() + " 已经通过屏障,继续执行...");
}).start();
}
}
}
在这个示例中,我们创建了一个 CyclicBarrier,并指定了有三个线程需要参与。当所有三个线程都到达屏障点时,会执行一个屏障动作,输出一条信息,然后所有线程被释放,继续执行后续操作。
总结
CyclicBarrier 是 Java 并发编程中的一个强大工具,它允许我们设计出高效、优雅的多线程协作模式,特别是在需要多个线程同步执行某些操作的场景下。通过合理使用 CyclicBarrier,可以大大简化多线程编程的复杂度,提高程序的效率和可维护性。
CyclicBarrier源码剖析 如何基于AQS实现任务分而治之
CyclicBarrier源码剖析:基于AQS实现任务分而治之
CyclicBarrier 是 Java 并发库中一个用于多线程协作的重要工具,它允许一组线程相互等待,直到到达某个公共屏障点。CyclicBarrier 的实现基于 AbstractQueuedSynchronizer (AQS),这是 Java 并发框架的核心组件之一,用于构建各种同步工具。
CyclicBarrier 的结构
CyclicBarrier 的核心是由 Sync 类实现的,这是一个内部类,继承自 AbstractQueuedSynchronizer。Sync 类的主要作用是维护一个状态变量,用于控制线程的等待和释放。
AQS 在 CyclicBarrier 中的角色
AQS 为 CyclicBarrier 提供了以下关键功能:
状态管理:AQS 通过一个
volatile int state变量来管理同步状态。在CyclicBarrier中,这个状态被用来表示到达屏障的线程数量和当前的屏障生成代数。线程等待队列:AQS 维护了一个 FIFO 等待队列,用于存放因未达到屏障条件而被阻塞的线程。
线程唤醒机制:当所有线程都到达屏障时,AQS 能够唤醒所有等待中的线程,使其继续执行。
CyclicBarrier 的关键方法
CyclicBarrier(int parties, Runnable barrierAction):构造函数,初始化parties参数表示参与的线程数量,barrierAction是所有线程到达屏障后执行的回调动作。await():线程调用此方法等待其他线程到达屏障。如果所有线程都到达了,那么所有线程都会被释放,并且如果设置了barrierAction,则会执行这个动作。
核心源码解析
Sync类的实现private static final class Sync extends AbstractQueuedSynchronizer { private static final long serialVersionUID = 4982264981921886391L; private final int parties; // 参与线程数 private transient int generation = 0; // 当前屏障的代数 private transient int count; // 到达屏障的线程数 Sync(int parties, Runnable barrierCommand) { if (parties <= 0) throw new IllegalArgumentException(); this.parties = parties; this.count = parties; this.barrierCommand = barrierCommand; } int getGeneration() { return generation; } protected int tryAcquireShared(int arg) { return (isBroken() || compareAndSetState(0, 1)) ? 1 : -1; } protected boolean tryReleaseShared(int arg) { if (isBroken()) return false; int c = --count; if (c > 0) return true; boolean broken = false; do { int g = generation; if (c == 0) { // 所有线程到达屏障 // 执行屏障动作 barrierCommand.run(); ++generation; firstThread = null; count = parties; } else if (g != generation) { // 有线程破坏了屏障 broken = true; break; } } while (!compareAndSetState(1, 0)); if (broken) breakBarrier(); return true; } // ... 其他方法 ... }await()方法的实现await()方法最终会调用AQS的acquireSharedInterruptibly()方法,尝试获取共享模式下的资源。如果当前线程是最后一个到达屏障的线程,那么它会负责执行barrierAction,并且重置count和generation。
总结
CyclicBarrier 通过 AQS 的共享同步模式实现了线程的等待和释放机制。线程在调用 await() 方法时,会尝试获取共享资源,如果所有线程都到达了屏障,那么最后到达的线程会负责唤醒所有等待中的线程,并执行屏障动作。这种机制使得 CyclicBarrier 成为一种高效且灵活的多线程协作工具。
Semaphore
Semaphore 等待指定数量的线程完成任务的并发组件
Semaphore 在 Java 并发编程中主要用于控制对共享资源的访问,通过信号量机制来管理一定数量的许可。虽然 Semaphore 的主要设计目的是用于资源的限流,但它也可以被巧妙地利用来等待指定数量的线程完成任务。这种方式不同于 CountDownLatch 和 CyclicBarrier 的直接等待机制,而是通过许可的发放和回收来间接控制线程的执行。
Semaphore 的基本概念
Semaphore 维护了一系列的许可,线程可以获取这些许可来访问一个共享资源。如果许可的数量为零,则线程将被阻塞,直到其他线程释放许可。Semaphore 提供了 acquire() 和 release() 方法来获取和释放许可。
使用 Semaphore 等待线程完成任务
虽然 Semaphore 的主要用途不是等待线程完成任务,但我们可以通过以下方式将其用于此目的:
- 初始化 Semaphore: 创建一个
Semaphore对象,其初始许可数等于需要等待的线程数量。 - 线程获取许可: 每个线程在开始执行任务前调用
acquire()方法获取一个许可。如果许可数为零,线程将被阻塞,直到有许可可用。 - 线程释放许可: 当线程完成任务后,它应该调用
release()方法释放一个许可。这会增加可用许可的数量,允许其他被阻塞的线程继续执行。
示例代码
下面是一个使用 Semaphore 来等待指定数量的线程完成任务的示例:
import java.util.concurrent.Semaphore;
public class SemaphoreWaitExample {
public static void main(String[] args) {
final int threadCount = 5; // 需要等待的线程数量
Semaphore semaphore = new Semaphore(threadCount);
for (int i = 0; i < threadCount; i++) {
new Thread(() -> {
try {
semaphore.acquire(); // 线程获取许可
System.out.println(Thread.currentThread().getName() + " is processing...");
Thread.sleep(1000); // 模拟任务执行
System.out.println(Thread.currentThread().getName() + " has finished.");
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
semaphore.release(); // 线程释放许可
}
}).start();
}
try {
semaphore.acquire(threadCount); // 主线程等待所有线程释放许可
System.out.println("All threads have finished their tasks.");
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
在这个例子中,Semaphore 被初始化为5个许可,代表需要等待的线程数量。每个线程在开始执行任务前获取一个许可,完成任务后释放许可。主线程通过再次调用 acquire() 方法并传入 threadCount 来等待所有线程释放许可,从而实现等待指定数量的线程完成任务的功能。
总结
虽然使用 Semaphore 来等待线程完成任务不如 CountDownLatch 或 CyclicBarrier 直观,但在某些特定场景下,尤其是需要同时限制线程数量和等待线程完成的情况下,Semaphore 提供了一个灵活的解决方案。通过合理利用许可的获取和释放,我们可以实现对线程执行的精确控制。
源码剖析之如何基于AQS等待指定数量的线程
Semaphore源码剖析:基于AQS的线程等待机制
Semaphore是Java并发工具包中的一个类,用于控制对共享资源的访问次数,即限制同时访问的线程数量。其内部实现基于AbstractQueuedSynchronizer(AQS),AQS是一个用于构建锁和同步器的框架。下面我们将深入分析Semaphore是如何基于AQS实现等待指定数量的线程完成任务的。
Semaphore的基本原理
Semaphore维护一个整型的同步状态,代表可用的许可证数量。当线程尝试获取许可证时,如果当前状态大于0,线程可以直接获取并减少状态值;否则,线程将被加入到AQS的等待队列中,等待其他线程释放许可证。
Semaphore的AQS实现
Semaphore内部实现了一个Sync类,该类继承自AbstractQueuedSynchronizer,并通过构造函数初始化同步状态。
private static final class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 7373984972572414691L;
Sync(int permits) {
setState(permits);
}
int tryAcquireShared(int reduceCount) {
for (;;) {
int current = getState();
int newCount = current - reduceCount;
if (newCount < 0 || // 不足
compareAndSetState(current, newCount))
return newCount;
}
}
boolean tryReleaseShared(int returnCount) {
for (;;) {
int current = getState();
int newCount = current + returnCount;
if (compareAndSetState(current, newCount))
return true;
}
}
}
Semaphore的构造方法
Semaphore的构造方法接受一个permits参数,表示初始的许可证数量。
public Semaphore(int permits) {
sync = new Sync(permits);
}
Semaphore的关键方法
acquire(int permits):线程尝试获取指定数量的许可证。如果没有足够的许可证,线程将被阻塞,直到有足够的许可证被释放。release(int permits):线程释放指定数量的许可证,可能允许其他等待的线程继续执行。
AQS的作用
AQS提供了tryAcquireShared和tryReleaseShared两个方法,用于获取和释放共享资源。在Semaphore中,这两个方法被重写以实现许可证的获取和释放。
tryAcquireShared:尝试获取共享资源。如果当前状态大于或等于请求的许可证数量,减少状态值并返回当前状态,否则将线程放入等待队列。tryReleaseShared:尝试释放共享资源。增加状态值,表示释放了许可证。
总结
Semaphore通过AQS的框架,利用状态值来控制许可证的获取和释放,从而实现了对线程访问共享资源的控制。当线程尝试获取许可证时,如果没有足够的许可证,线程会被放入等待队列,直到其他线程释放许可证。这种机制确保了线程的有序执行,避免了资源的竞争和冲突。
Exchange如何支持两个线程之间进行数据交换
在多线程编程中,Exchange通常指的是Java并发包中的Exchanger类,这是一个用于线程间数据交换的同步工具。Exchanger允许两个线程在一个交汇点上交换数据。当一个线程调用exchange方法时,它会等待另一个线程也在相同Exchanger实例上调用exchange方法。一旦两个线程都到达交汇点,它们就会交换数据并继续执行。
Exchanger的使用
下面是一个使用Exchanger在两个线程之间交换数据的简单示例:
import java.util.concurrent.Exchanger;
import java.util.concurrent.TimeUnit;
public class ExchangerDemo {
public static void main(String[] args) {
Exchanger<String> exchanger = new Exchanger<>();
Thread t1 = new Thread(() -> {
String data = "Thread 1's Data";
try {
System.out.println("Thread 1 is waiting to exchange data.");
String exchangedData = exchanger.exchange(data);
System.out.println("Thread 1 received data from Thread 2: " + exchangedData);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Thread t2 = new Thread(() -> {
String data = "Thread 2's Data";
try {
System.out.println("Thread 2 is waiting to exchange data.");
String exchangedData = exchanger.exchange(data);
System.out.println("Thread 2 received data from Thread 1: " + exchangedData);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
在这个示例中,两个线程T1和T2各自生成了一些数据,然后调用exchanger.exchange()方法。当两个线程都到达exchanger时,它们会交换数据。在交换完成后,每个线程都会打印出从对方线程接收到的数据。
Exchanger的高级用法
除了最基本的交换功能,Exchanger还提供了更高级的用法,如:
带超时的交换:如果希望在等待交换时设置一个超时时间,可以使用
exchanger.exchange(Object obj, long timeout, TimeUnit unit)方法。如果在指定时间内没有其他线程到达交汇点,该方法将抛出TimeoutException。批量交换:如果需要在多个线程之间进行数据交换,可以使用
Exchanger的批量交换模式。这需要创建多个Exchanger实例,并使用适当的同步机制确保所有线程都在正确的时机进行交换。
总结
Exchanger是Java并发工具包中一个非常有用且强大的工具,它允许线程间进行数据交换,这对于实现复杂的多线程协作模式非常有帮助。通过合理使用Exchanger,你可以构建出高效且线程安全的数据交换机制,适用于各种需要线程间通信的场景。然而,要注意Exchanger的主要作用是数据交换,而不是数据存储或缓存,因此在设计解决方案时,要确保它的使用符合预期的并发和数据交换需求。
案例实战
CyclicBarrier如何实现API服务中对多个接口并发调用后统一合并数据再返回
在Java中实现API服务中对多个接口并发调用并统一合并数据再返回,可以使用CompletableFuture结合ExecutorService来达到目的。CompletableFuture提供了异步编程的能力,非常适合处理并发调用和数据聚合的场景。下面是一个详细的示例:
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.*;
import java.util.stream.Collectors;
public class MultiApiCallService {
private static final ExecutorService executor = Executors.newFixedThreadPool(10);
public static void main(String[] args) throws ExecutionException, InterruptedException {
List<String> apiUrls = Arrays.asList(
"http://api1.example.com",
"http://api2.example.com",
"http://api3.example.com"
);
List<CompletableFuture<String>> futures = apiUrls.stream()
.map(url -> CompletableFuture.supplyAsync(() -> callApi(url), executor))
.collect(Collectors.toList());
CompletableFuture<Void> combinedFuture = CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]));
combinedFuture.thenRun(() -> {
try {
List<String> responses = futures.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList());
String mergedResponse = mergeResponses(responses);
System.out.println("Merged Response: " + mergedResponse);
} catch (CompletionException e) {
e.getCause().printStackTrace();
}
});
// shutdown the executor service when no longer needed
executor.shutdown();
}
private static String callApi(String url) {
// Simulate an API call
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new IllegalStateException("Interrupted during API call", e);
}
return "Response from " + url;
}
private static String mergeResponses(List<String> responses) {
// Merge the responses here
return responses.stream().collect(Collectors.joining(", "));
}
}
在这个示例中,我们首先创建了一个ExecutorService,用于执行并发的API调用。接着,我们使用CompletableFuture.supplyAsync方法异步调用callApi方法,该方法模拟了API调用。supplyAsync方法会返回一个CompletableFuture,我们可以将其收集到一个列表中。
然后,我们使用CompletableFuture.allOf方法来等待所有异步调用的完成。一旦所有调用都完成,我们就可以在thenRun方法中合并所有响应。thenRun方法会在所有依赖的CompletableFuture完成后执行指定的Runnable。
最后,我们通过executor.shutdown()来关闭ExecutorService,确保所有线程最终会终止。
这种方法的好处是,它可以有效地处理并发调用,并在所有调用完成后立即合并数据,无需显式地同步线程或使用阻塞调用。CompletableFuture的链式调用和流式处理使得代码更加清晰和简洁。
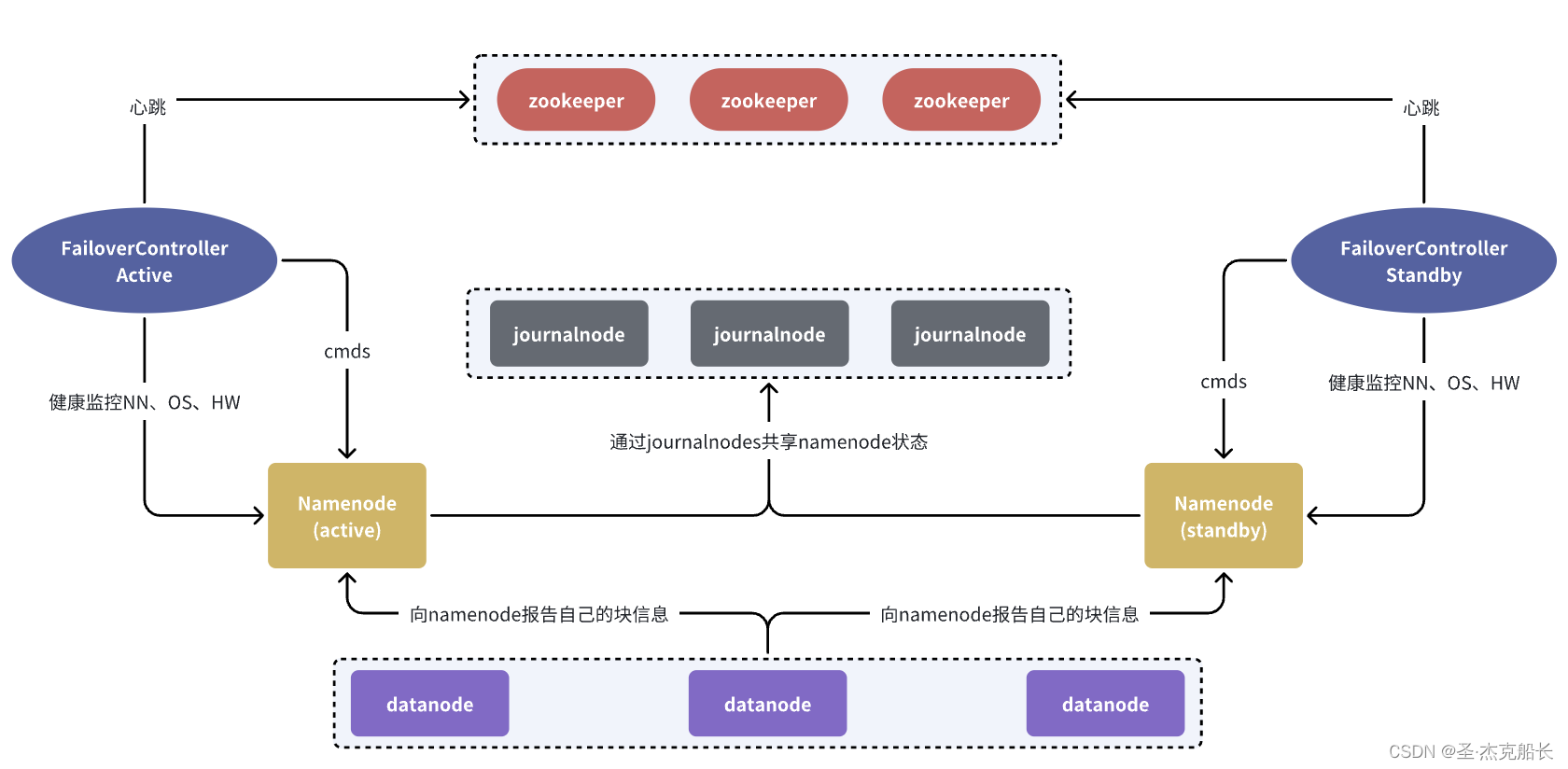
分布式存储系统的HA高可用架构原理介绍
分布式存储系统的高可用(High Availability,简称HA)架构设计是为了确保在部分组件故障的情况下,系统仍能持续提供服务,即具有自我恢复和容错的能力。在分布式环境中,HA架构的重要性尤为突出,因为节点故障、网络分区等问题几乎是不可避免的。下面将详细介绍分布式存储系统HA架构的一些核心原理和常见技术。
1. 数据冗余与复制
数据冗余是HA架构的基础。通过在多个节点上存储数据的多个副本,即使部分节点发生故障,数据仍然可以从其他节点上读取,从而确保服务的连续性和数据的完整性。常见的数据冗余策略包括:
- 副本复制:为每份数据创建多个完全一致的副本,分布在不同的节点上。例如,HDFS(Hadoop Distributed File System)默认为每个文件块创建3个副本。
- 纠删码(Erasure Coding):相比于简单的副本复制,纠删码在存储效率上更高。它将数据切分为多个片段,并计算出校验码,存储时既包含原始数据也包含校验信息。当部分数据丢失时,可以利用剩余数据和校验信息重构缺失的部分。
2. 分布式一致性协议
分布式一致性协议确保了在分布式系统中,所有节点对于数据的一致性感知。常见的协议包括:
- Raft:简化版的Paxos协议,更易于理解和实现。Raft通过选举产生领导者,由领导者统一管理数据的写入和复制,确保所有节点最终达到一致状态。
- Paxos:经典的分布式一致性算法,通过提案和投票机制来达成一致决策。
- ZAB(ZooKeeper Atomic Broadcast):ZooKeeper使用的协议,结合了Fast Paxos和传统Paxos的优点,适用于高吞吐量的场景。
3. 故障检测与恢复
在分布式系统中,及时准确地检测节点故障并进行恢复是HA的关键。常见的故障检测机制包括:
- 心跳监测:节点定期向集群发送心跳消息,如果超过一定时间没有收到某节点的心跳,系统将认为该节点已故障。
- 故障恢复:一旦检测到节点故障,系统需要自动将该节点上的任务迁移到其他健康节点上,或者从其他节点恢复数据副本。
4. 负载均衡与资源调度
为了提高系统的整体性能和可用性,分布式存储系统还需要实现负载均衡和资源的有效调度。这包括:
- 动态负载均衡:根据各节点的实时负载情况,动态调整数据和任务的分布,避免热点问题。
- 资源调度:合理分配计算和存储资源,确保资源的有效利用,同时避免资源争抢。
5. 弹性伸缩
分布式存储系统应具备根据业务需求自动调整规模的能力,即弹性伸缩。这涉及到:
- 水平扩展:通过增加更多的节点来提升系统容量和性能。
- 垂直扩展:通过增加单个节点的硬件配置来提升性能。
结论
构建高可用的分布式存储系统是一个复杂的过程,涉及数据冗余、一致性保障、故障检测与恢复、负载均衡以及弹性伸缩等多个方面。通过综合运用上述技术和策略,可以显著提升系统的可靠性和性能,确保在面对各种故障和挑战时,系统仍能提供稳定的服务。
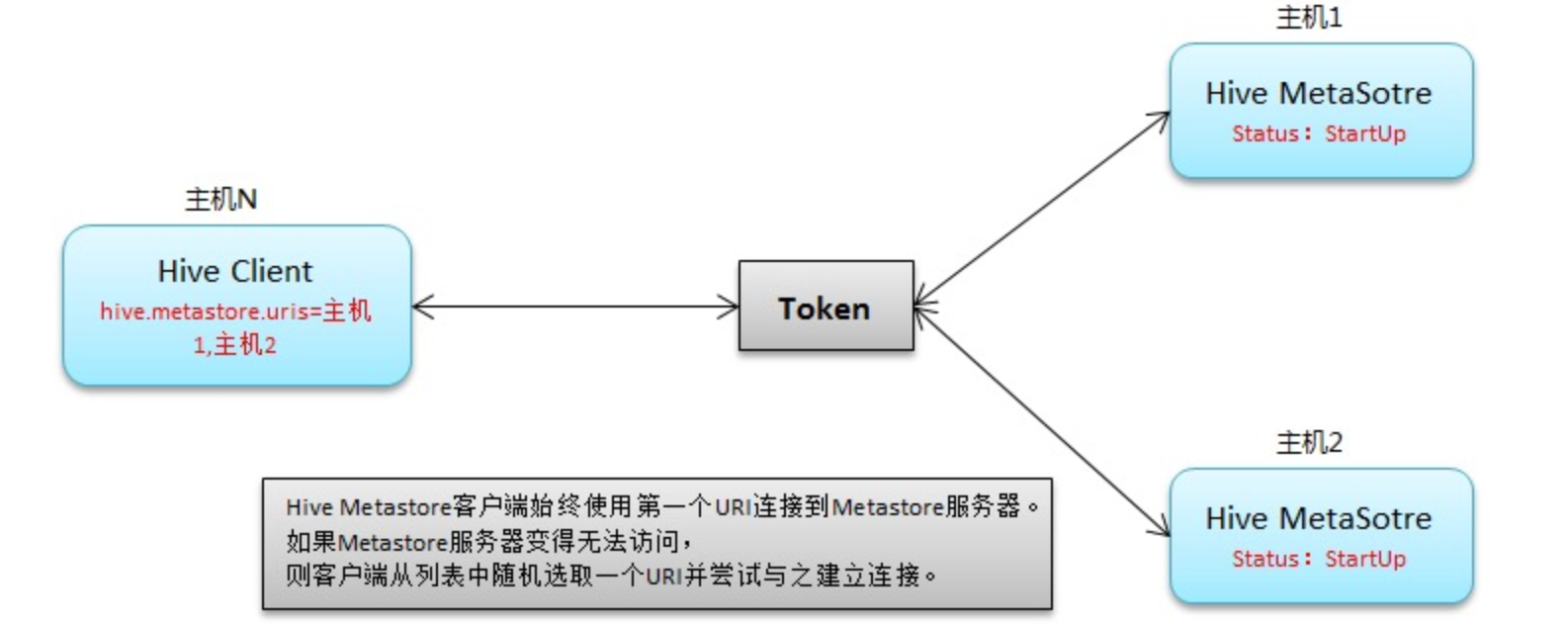
slave节点向主备两个master节点注册的机制介绍
在分布式系统中,为了增强系统的高可用性和容错能力,通常会采用主备(Master-Slave)架构,其中包含一个主节点(Master)和一个或多个备用节点(Backup)。在这种架构下,slave节点向主备两个master节点注册的机制是确保系统健壮性和数据一致性的重要组成部分。下面详细介绍一下这种机制的工作原理和关键步骤。
1. 注册流程概述
slave节点向主备两个master节点注册的过程主要包括以下几个步骤:
初始化连接:slave节点启动时,会尝试建立与预设的主节点和备用节点的通信连接。这些节点的信息(如IP地址和端口号)通常在配置文件中预先定义。
注册请求:连接成功后,slave节点向主节点发送注册请求,该请求包含了slave节点的标识信息(如ID、版本号、当前状态等),以便主节点能够识别和管理。
注册确认:主节点收到注册请求后,会检查slave节点的信息是否合法,并在系统状态中更新slave节点的状态。如果注册成功,主节点会向slave节点发送确认信息。
同步备用节点:在主节点确认注册后,它会将slave节点的信息同步到备用节点,确保备用节点也知晓slave节点的存在和状态。这样做的目的是在主节点出现故障时,备用节点可以迅速接管,而不会丢失对slave节点的管理。
心跳机制:为了维持连接的活跃性和检测节点的健康状况,slave节点会定期向主节点和备用节点发送心跳信息。如果一段时间内未收到心跳,节点将被视为离线或故障,系统会采取相应的措施(如重新注册或从系统中移除)。
2. 故障切换
在主节点发生故障时,备用节点会升级为主节点,继续接收和管理slave节点的注册和心跳信息。这一过程通常是自动的,且尽可能快地完成,以减少系统不可用的时间。
3. 数据同步
在slave节点向主备两个master节点注册的过程中,还涉及到数据的同步。通常,slave节点会从主节点拉取最新的数据和状态信息,以保持与主节点的一致性。在主节点故障切换后,新的主节点也会确保slave节点的数据是最新的。
4. 优化和挑战
在实际部署中,这种注册机制需要考虑网络延迟、节点故障率、数据一致性等多种因素,以优化整个系统的性能和可靠性。例如,可以采用更高级的同步算法(如Raft或Paxos)来提高数据一致性,或者使用负载均衡技术来分散注册和心跳请求的压力。
总之,slave节点向主备两个master节点注册的机制是分布式系统中一项重要的功能,它不仅确保了系统的高可用性,还提高了数据的一致性和安全性。通过精心设计和优化,这种机制可以有效支撑大规模分布式系统的稳定运行。
slave节点注册时同步阻塞等待多个master注册完毕
在分布式系统中,slave节点注册到多个master节点(通常是一个主master和一个或多个备用master)时,确保所有注册操作都完成后再继续后续操作是非常重要的,特别是在要求强一致性的场景下。当slave节点需要同步阻塞等待多个master注册完毕时,可以采用以下几种策略:
1. 使用CountDownLatch或类似机制
在Java等语言中,可以使用CountDownLatch来同步阻塞等待所有注册操作完成。CountDownLatch是一个线程同步辅助类,它允许一个或多个线程等待其他线程完成操作。slave节点在向每个master节点注册时,可以减少CountDownLatch的计数,当计数归零时,表示所有注册操作已完成。
import java.util.concurrent.CountDownLatch;
public class SlaveRegistration {
private final CountDownLatch latch = new CountDownLatch(masterNodes.size());
public void registerToMasters(List<String> masterNodes) {
masterNodes.forEach(master -> {
new Thread(() -> {
try {
// 执行注册操作
registerToMaster(master);
} finally {
// 减少计数
latch.countDown();
}
}).start();
});
try {
// 等待所有注册操作完成
latch.await();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
private void registerToMaster(String masterUrl) {
// 实现向master节点注册的逻辑
}
}
2. 使用CompletableFuture
在Java中,CompletableFuture可以用于处理异步操作,并且可以方便地组合多个CompletableFuture实例来等待所有操作完成。
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
import java.util.stream.Collectors;
public class SlaveRegistration {
public void registerToMasters(List<String> masterNodes) throws ExecutionException, InterruptedException {
List<CompletableFuture<Void>> futures = masterNodes.stream()
.map(this::registerToMasterAsync)
.collect(Collectors.toList());
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).get();
}
private CompletableFuture<Void> registerToMasterAsync(String masterUrl) {
return CompletableFuture.runAsync(() -> {
// 实现向master节点注册的逻辑
});
}
}
3. 利用数据库或中间件的事务机制
在一些场景下,可以利用数据库的事务机制或消息队列等中间件来确保注册操作的原子性。比如,slave节点可以先向所有master节点发起注册请求,但不立即确认,而是将这些操作打包成一个事务,只有当所有注册请求都得到确认后,才提交事务,正式完成注册。
4. 分布式协调服务
利用如Zookeeper、Etcd等分布式协调服务,可以在多个master节点之间实现一致性。slave节点可以先向协调服务注册,协调服务负责将注册信息同步到所有master节点,确保一致性。
注意事项
- 在实现阻塞等待时,需要注意超时处理,避免因个别master节点长时间无响应导致整个注册流程挂起。
- 应考虑到网络延迟和master节点的故障可能性,设计相应的重试机制和故障转移策略。
- 在高并发场景下,需要关注注册操作的性能和资源消耗,避免成为系统瓶颈。
通过上述策略之一或组合使用,可以有效地实现slave节点在注册时同步阻塞等待多个master注册完毕,从而保证系统的稳定性和一致性。
数据分布式存储场景下的分布式计算架构介绍
数据分布式存储场景下的分布式计算架构设计,旨在解决大数据量下高效处理和分析的需求。这种架构通常涉及到数据的分布式存储、分布式计算框架、数据分片、任务调度、容错机制等多个关键组件。下面将详细介绍这些组件及其工作原理:
1. 分布式存储系统
分布式存储系统是分布式计算架构的基础,用于存储海量数据。常见的分布式存储系统包括:
- Hadoop HDFS:Hadoop的分布式文件系统,适合存储大量半结构化或非结构化数据。
- Google Cloud Storage:云存储服务,提供了大规模数据的存储和访问能力。
- Ceph:一种分布式存储系统,支持块存储、对象存储和文件系统,具有高可扩展性和高性能。
- Apache Cassandra:分布式NoSQL数据库,特别适合处理大量结构化数据,具有高可用性和线性可扩展性。
2. 数据分片与分区
为了提高数据处理效率,分布式存储系统通常会对数据进行分片或分区,将数据均匀分布到多个节点上。这样可以实现数据的并行处理,减少单一节点的负载。数据分片可以基于哈希、范围、列表等方式进行。
3. 分布式计算框架
分布式计算框架提供了并行处理数据的抽象层,使开发者能够编写分布式应用程序,而无需深入了解底层的分布式细节。常见的分布式计算框架包括:
- Apache MapReduce:最早期的分布式计算框架,通过Map和Reduce两个阶段实现数据的并行处理。
- Apache Spark:提供了内存计算能力,支持多种计算模型,如批处理、流处理和机器学习,性能优于MapReduce。
- Apache Flink:专注于流处理,同时也支持批处理,具有低延迟和高吞吐量的特点。
- Apache Storm:专门用于实时流处理的框架,支持持续查询和事件驱动的应用。
4. 任务调度与资源管理
分布式计算框架通常包含任务调度器和资源管理器,如YARN(Yet Another Resource Negotiator)在Hadoop中用于资源管理和任务调度,Mesos和Kubernetes也常用于容器化环境下的资源管理和任务调度。
5. 容错机制
在分布式系统中,容错机制至关重要,以确保在节点故障或网络分区的情况下,系统仍能正常运行。容错机制通常包括数据冗余、任务重试、心跳检测和故障恢复等策略。
6. 数据一致性与事务
在分布式计算中,数据一致性是一个挑战。CAP定理(Consistency, Availability, Partition tolerance)指出,在分布式系统中,无法同时保证一致性、可用性和分区容忍性。因此,分布式计算架构需要根据具体应用场景选择合适的一致性模型,如强一致性、最终一致性或弱一致性。
7. 安全性与隐私
在分布式计算架构中,数据安全和用户隐私是不可忽视的问题。需要实施适当的安全措施,如数据加密、访问控制和审计日志,以保护数据免受未经授权的访问和篡改。
综上所述,数据分布式存储场景下的分布式计算架构是一个复杂的系统,需要综合考虑存储、计算、调度、容错、一致性等多个方面,以满足高可用性、高性能和安全性的要求。
基于Semaphore实现分布式计算系统的推测执行机制
在分布式计算中,推测执行(Speculative Execution)是一种优化策略,用于加速任务完成时间。当系统检测到某个任务执行缓慢时,它会在另一个节点上启动同样的任务副本,以期望其中一个更快完成。基于Semaphore实现推测执行机制,虽然不是常规做法,但可以作为一种思路来探讨。Semaphore通常用于控制对共享资源的访问,但在分布式环境下,我们可以利用其控制并发任务执行的概念来实现某种形式的资源或任务管理,进而支持推测执行机制。以下是基于Semaphore的推测执行机制的一个简化示例,主要聚焦于如何使用Semaphore来控制和监控任务执行,从而触发推测执行:
步骤 1: 设计Semaphore控制器
首先,我们需要一个Semaphore控制器,它能够跟踪正在执行的任务数量,以及每个任务的预期完成时间。这个控制器将用于决定何时启动推测执行。
import java.util.concurrent.Semaphore;
import java.util.concurrent.TimeUnit;
public class SpeculativeExecutionController {
private Semaphore semaphore;
private long speculativeThreshold; // 触发推测执行的阈值时间
public SpeculativeExecutionController(int permits, long speculativeThreshold) {
this.semaphore = new Semaphore(permits);
this.speculativeThreshold = speculativeThreshold;
}
public boolean acquireForTask() {
try {
return semaphore.tryAcquire(speculativeThreshold, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return false;
}
}
public void releaseForTask() {
semaphore.release();
}
}
步骤 2: 实现任务执行和监控
接下来,我们实现一个任务执行器,它使用上面的SpeculativeExecutionController来控制任务的执行,并监控任务的执行时间。如果任务执行时间超过了阈值,将触发推测执行。
public class TaskExecutor {
private SpeculativeExecutionController controller;
public TaskExecutor(SpeculativeExecutionController controller) {
this.controller = controller;
}
public void executeTask(Runnable task) {
if (!controller.acquireForTask()) {
// 触发推测执行
startSpeculativeTask(task);
} else {
try {
task.run();
} finally {
controller.releaseForTask();
}
}
}
private void startSpeculativeTask(Runnable task) {
// 在另一个节点上启动同样的任务
// 这里假设我们有一个方法可以做到这一点
// 这个方法的具体实现将依赖于你的分布式计算框架
speculativeTaskLauncher.launch(task);
}
}
步骤 3: 集成到分布式计算框架
最后一步是将这个SpeculativeExecutionController和TaskExecutor集成到你的分布式计算框架中,例如Apache Spark或Hadoop。每个任务在执行前都应该通过TaskExecutor来获取执行许可,如果未能在规定时间内获取,将触发推测执行。
注意事项
- 这个示例是一个简化的概念证明,实际应用中需要考虑更多细节,如如何确保推测执行任务的正确性,避免资源浪费,以及如何处理任务结果的一致性问题。
Semaphore的使用在这里主要是为了演示如何控制并发任务执行,实际上在分布式系统中,更推荐使用更高级别的协调服务(如Apache Zookeeper或Etcd)来实现任务控制和状态同步。- 推测执行的阈值时间和并发许可数量需要根据具体的任务特性和资源状况进行调优。
通过上述步骤,你可以基于Semaphore的概念来实现一种形式的推测执行机制,但这并不是标准或推荐的做法,因为Semaphore本身并没有为分布式环境下的任务调度和监控提供直接的支持。在实际项目中,应该考虑使用更成熟和专为分布式计算设计的框架和工具。