简介
主成分分析(Principal Component Analysis, PCA)是一种统计技术,用于简化数据集,将原来具有多个变量的数据降维到较少的主要成分上。主成分分析是一种降维算法,它能将多个指标转换为少数几个主成分,这些主成分是原始变量的线性组合,且彼此之间 互不相关,其能反映出原始数据的大部分信息。一般来说, 当研究的问题涉及到多变量且变量之间存在很强的相关性时, 我们可考虑使用主成分分析的方法来对数据进行简化.
- 降维:减少数据集中变量的数量,同时尽量保持数据的方差。
- 特征提取:识别和提取数据中的重要特征,有助于理解数据的结构。
原理
PCA通过线性变换将原始数据转换为新的坐标系,使得:
- 第一主成分(PC1)在新坐标系中具有最大方差。
- 第二主成分(PC2)是与第一主成分正交,并且具有次大方差。
- 依此类推。
这些主成分是数据中的线性组合,捕获了数据中最大的信息量。
步骤
执行PCA的一般步骤如下:
标准化数据:由于各个变量的量纲可能不同,需要对数据进行标准化处理,使每个变量具有均值为0,方差为1的标准正态分布。
协方差矩阵计算:计算标准化数据的协方差矩阵,衡量变量之间的线性关系。(相关系数矩阵)
特征值分解:对协方差矩阵(相关系数矩阵corrcoef)进行特征值分解或奇异值分解,得到特征值和对应的特征向量。
选取主成分:根据特征值选择前k个主成分,贡献率=特征值/n,要满足贡献率达到80%,这些主成分解释了数据中大部分的方差。
转换数据:使用选取的主成分将原始数据投影到新的低维空间中。
应用
PCA在许多领域广泛应用,包括但不限于:
- 数据预处理和降维、图像压缩、基因表达数据分析、股票市场分析
作为经典算法,在数学建模和机器学习领域有广泛运用。
优缺点
优点:
- 简化数据集,降低维度,提高计算效率。
- 消除变量间的相关性
- 便于可视化高维数据,如聚类分析,通过降维的方法利于画图。
缺点:
- 主成分难以解释,缺乏直观意义。
- 对线性关系敏感,非线性关系处理效果不好。
- 需要对数据进行标准化处理,否则结果可能不准确。
在主成分分析中,我们首先应保证所提取的前几个主成分的累计贡献率达到一个较高的水平,其次对这些被提取的主成分必须都能够给出 符合实际背景和意义的解释。 主成分的解释其含义一般多少带有点模糊性,不像原始变量的含义那么清楚、确切,这是变量降维过程中不得不付出的代价。因此,提取的主成分个数m通常应明显小于原始变量个数p(除非p本身较小),否则维数降低的“利”可能抵不过主成分含义不如原始变量清楚的“弊”。 如果原始变量之间具有较高的相关性,则前面少数几个主成分的累计贡献率通常就能达到一个较高水平,也就是说,此时的累计贡献率通 常较易得到满足。 主成分分析的困难之处主要在于要能够给出主成分的较好解释,所提取的主成分中如有一个主成分解释不了,整个主成分分析也就失败了。
主成分分析是变量降维的一种重要、常用的方法,简单的说,该方 法要应用得成功,一是靠原始变量的合理选取,二是靠“运气”。
——《应用多元统计分析》 王学民
运用
以下是对于数学建模国赛2020C题的数据进行主成分分析的代码,作为小小的运用案例吧:
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
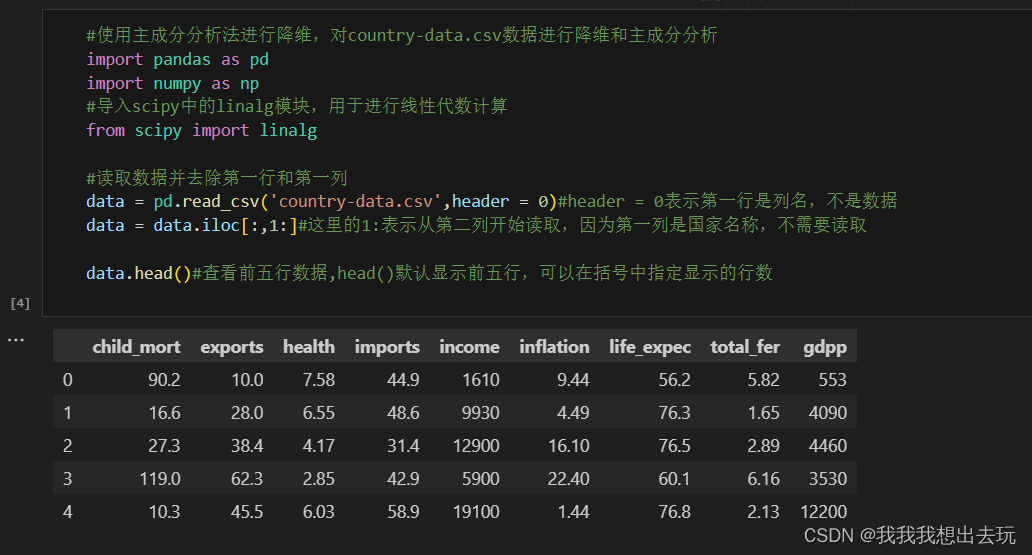
# 1. 读取CSV文件中的数据
data = pd.read_csv('test.csv')
df=pd.DataFrame(data)
print(df.head())
df.drop('id',axis=1,inplace=True)
# 2. 数据标准化处理
features = df.columns # 假设所有列都是特征
x = df.loc[:, features].values
x = StandardScaler().fit_transform(x)
# 3. 创建PCA对象并执行PCA
pca = PCA(n_components=2) # 我们将数据降到2个维度
principalComponents = pca.fit_transform(x)
# 将PCA后的数据转换为DataFrame
principalDf = pd.DataFrame(data=principalComponents, columns=['Principal Component 1', 'Principal Component 2'])
# 如果原始数据中有标签(比如分类标签),可以将其附加到降维后的数据中
# 假设原始数据的最后一列是类标签
if 'label' in data.columns:
finalDf = pd.concat([principalDf, data[['label']]], axis=1)
else:
finalDf = principalDf
# 4. 打印结果
print(finalDf.head())
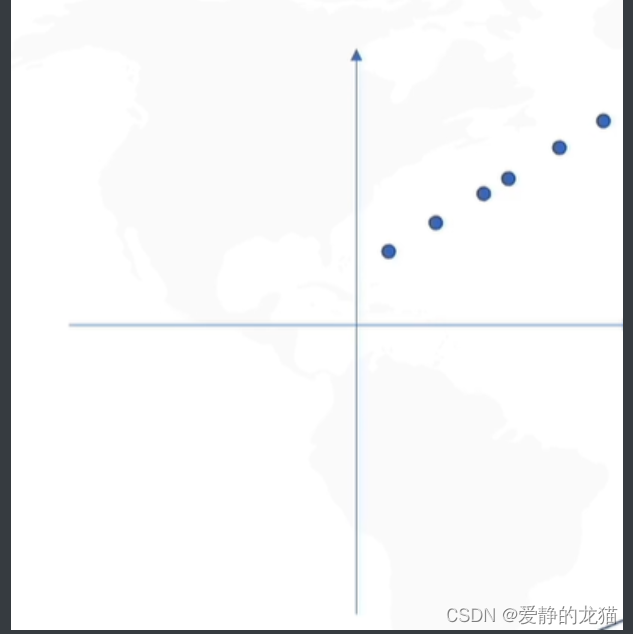
# 5. 可视化
fig, ax = plt.subplots()
ax.scatter(finalDf['Principal Component 1'], finalDf['Principal Component 2'])
if 'label' in data.columns:
for label in finalDf['label'].unique():
indicesToKeep = finalDf['label'] == label
ax.scatter(finalDf.loc[indicesToKeep, '主成分1'],
finalDf.loc[indicesToKeep, '主成分2'],
label=label)
ax.legend()
plt.xlabel('P1')
plt.ylabel('P2')
plt.title('PCA')
plt.show()
结果:




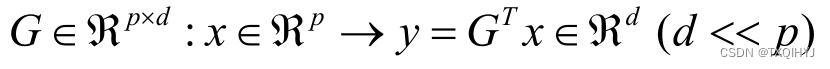



















![[数仓]三、离线数仓(Hive数仓系统)](https://i-blog.csdnimg.cn/direct/3377eadf6b2f4b268494c12afb62198f.png)