梯度下降算法的原理, 如何选择合适的步长和停止条件。
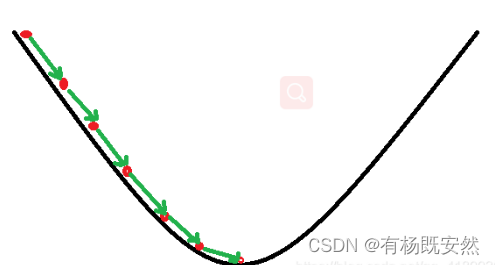
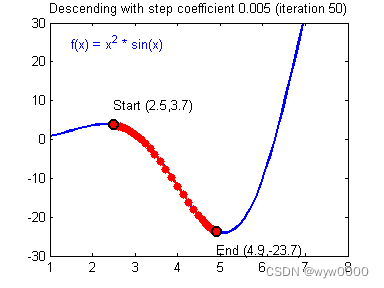
梯度下降算法是一种优化方法,用于寻找函数最小值,常用于机器学习中的模型训练,如线性回归、神经网络等。基本思想是从当前位置开始,沿着目标函数梯度的反方向逐步调整参数,直至达到局部最优解。
步骤如下:
初始化:
随机选取一个初始点作为参数估计值。
计算梯度:
对当前参数估计计算目标函数的梯度,梯度表示了函数值上升最快的方向。
更新参数:
按比例减去梯度乘以一个学习率(也称步长),即 w_new = w_old - learning_rate * gradient,这里 w 是参数,learning_rate 控制更新的大小。
判断停止条件:
通常基于两个标准:
当梯度的绝对值小于某个阈值(比如 1e-6 或者 1e-8),认为已接近极小值,可以停止迭代。
或者当参数变化很小,或者训练损失或验证损失没有明显改善,达到一定的迭代次数(如100次或达到预定的最大迭代次数)。
返回结果:
返回最终找到的参数作为模型的最佳估计。
选择步长(学习率)时需要谨慎,如果太大可能会导致算法震荡不收敛;太小则可能导致收敛速度过慢。一种常见的策略是使用动态调整的学习率,例如学习率衰减,或使用自适应学习率方法如Adagrad、RMSprop或Adam。
怎么防止梯度下降陷入局部最优而非全局最优?
梯度下降是一种常用的优化算法,但它有可能因为初始化随机性、数据特性或学习率设置不当等因素,导致模型陷入局部最优解而不是全局最优解。以下是几种常见的策略来避免这种情况:
随机初始化:
初始参数应该从一个较小的范围随机生成,这有助于探索更广阔的搜索空间。
梯度噪声:
添加一些随机梯度噪声,如Lecun权重初始化或动量法,可以帮助模型跳出局部最优。
学习率衰减:
采用学习率衰减策略,例如学习率随训练进程逐渐减小,可以防止过早停止在某个平坦区域。
使用合适的优化算法:
除了基本的梯度下降,还有牛顿法、Adagrad、RMSprop、Adam等更复杂的优化算法,它们有更好的全局收敛性能。
网格搜索或超参数调整:
通过交叉验证选择最佳的学习率和其他超参数组合,有利于找到全局最优。
模型正则化:
通过L1或L2正则化,可以减少模型对某些特征的过度依赖,防止过拟合,从而提高泛化能力。
早期停止:
监控验证集的表现,在验证误差不再降低时停止训练,可以防止过拟合并帮助找到较好的局部最优。