t-sne
t-SNE(t-分布随机邻域嵌入,t-distributed Stochastic Neighbor Embedding)是由 Laurens van der Maaten 和 Geoffrey Hinton 于 2008 年提出的一种非线性降维技术。它特别适合用于高维数据的可视化。t-SNE 的主要目标是将高维数据映射到低维空间(通常是二维或三维),同时尽可能地保留高维数据中的局部结构。这使得我们可以在低维空间中更直观地观察数据的结构和分布。
t-SNE 能很好地保留高维数据的局部结构,适用于各种类型的数据,尤其是复杂的非线性数据。但它的计算复杂度较高,不适合非常大规模的数据集,对超参数(如 perplexity)较为敏感,需要仔细调参。低维空间中的全局结构不一定可靠。
可视化
要使用 t-SNE 进行数据可视化,可以使用 Python 的 scikit-learn 库。随机生成两个数据集:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.manifold import TSNE
# 假设这里有两个数据集,分别是 dataset1 和 dataset2
dataset1 = np.random.randn(100, 10) # 生成随机数据作为示例
dataset2 = np.random.randn(80, 10)
# 合并数据集
merged_data = np.concatenate((dataset1, dataset2))
# 对合并后的数据应用 t-SNE 进行降维
tsne = TSNE(n_components=2, random_state=0)
tsne_data = tsne.fit_transform(merged_data)
# 将降维后的数据按照原来的数据集进行划分
tsne_data_1 = tsne_data[:len(dataset1)]
tsne_data_2 = tsne_data[len(dataset1):]
# 绘制散点图
plt.scatter(tsne_data_1[:, 0], tsne_data_1[:, 1], color='b', label='Dataset 1')
plt.scatter(tsne_data_2[:, 0], tsne_data_2[:, 1], color='r', label='Dataset 2')
plt.legend()
plt.show()

根据数据集中不同的标签使用不同的颜色:
import numpy as np
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from utils.feature import features18_
df = pd.read_csv('68.csv')
X = df[features18_] # 选择需要的特征
y = df["fs"] # 根据fs标签选择不同的颜色画图
# 初始化 t-SNE 模型,设置降维后的维度为 2 维
tsne = TSNE(n_components=2, perplexity=min(10, len(X)-1))
# 对数据进行降维
X_tsne = tsne.fit_transform(X)
# 绘制结果
plt.figure(figsize=(10, 10))
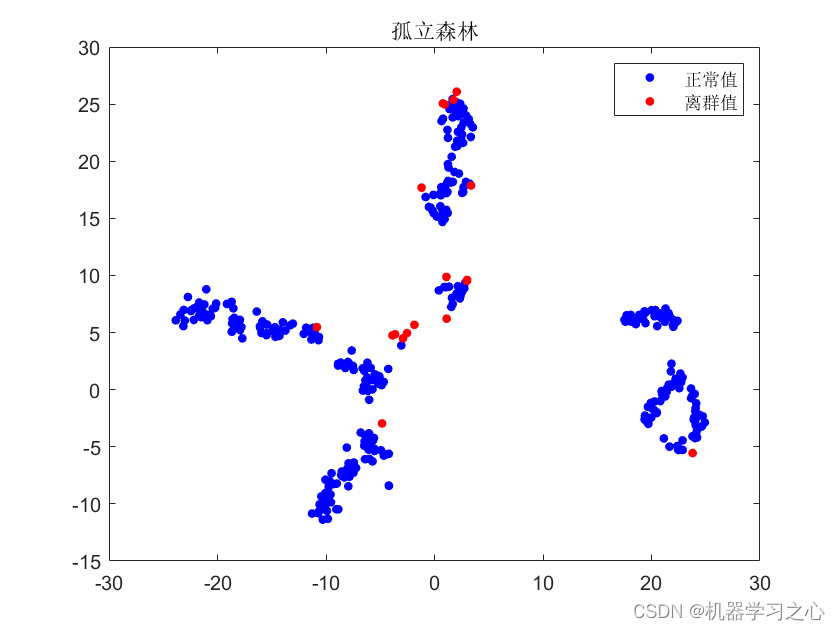
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y.astype(int), cmap='jet')
plt.colorbar()
plt.show()

t-SNE的参数
t-SNE 类的 init 方法定义了用于初始化 t-SNE 对象的参数。下面是这些参数的详细介绍:
n_components:int, 默认值=2
要降维到的维度数。通常设为2或3,用于可视化。
perplexity:float, 默认值=30.0
衡量数据局部结构的一个超参数。较大的 perplexity 使 t-SNE 关注更大范围的邻居数。有效范围通常在5到50之间。
early_exaggeration:float, 默认值=12.0
在早期阶段,增加距离以便于更好地形成群体结构。较高的值使得群体更加分离。
learning_rate:float 或 “auto”, 默认值=“auto”
学习率。学习率过低可能导致优化停滞,学习率过高可能导致嵌入结构被破坏。当设为 “auto” 时,学习率为 max(N / early_exaggeration / 4, 50),其中 N 是样本数。
n_iter:int, 默认值=1000
梯度下降迭代次数。增大此值可能会提升嵌入的质量。
n_iter_without_progress:int, 默认值=300
在没有进展的情况下提前终止的迭代次数。用于防止无效计算。
min_grad_norm:float, 默认值=1e-7
最小梯度范数,用于判断是否收敛。
metric:string 或 callable, 默认值=“euclidean”
用于计算高维空间距离的度量标准。默认是欧几里得距离。
metric_params:dict 或 None, 默认值=None
用于度量的额外关键字参数。
init:string 或 ndarray, 默认值=“pca”
低维嵌入的初始化方法。可以是 ‘random’ 或 ‘pca’,也可以提供一个初始位置的数组。
verbose:int, 默认值=0
控制输出的详细程度。0 表示不输出,1 或更高的值表示输出更多信息。
random_state:int, RandomState 实例或 None, 默认值=None
随机数生成器的种子。设置此参数以获得可重复的结果。
method:string, 默认值=“barnes_hut”
用于计算嵌入的算法。可选值有 ‘barnes_hut’(适用于较大数据集)和 ‘exact’(适用于较小数据集)。
angle:float, 默认值=0.5
仅在 method=‘barnes_hut’ 时使用。控制 Barnes-Hut 近似的精度,值越小精度越高,计算时间越长。
n_jobs:int 或 None, 默认值=None
并行计算的 CPU 核心数。None 表示 1,-1 表示使用所有可用的核心。
生成excel文件
用python的matplotlib库作出的图可以看,但并不完美,虽然可以通过调matplotlib的参数来使图画得更完美,但是不如使用专业的画图软件方便,比如微软的visio,爱不释手,所以我们需要将t-SNE降维的坐标点生成一个excel文件,在画图软件中倒入这个excel文件,使可视化变得更完美。将t-SNE降维后的数据保存到Excel文件中,可以使用 pandas 库中的 to_excel 方法。
df = pd.DataFrame(X_tsne)
writer = pd.ExcelWriter('arr.xlsx')
df.to_excel(writer)
writer.close()