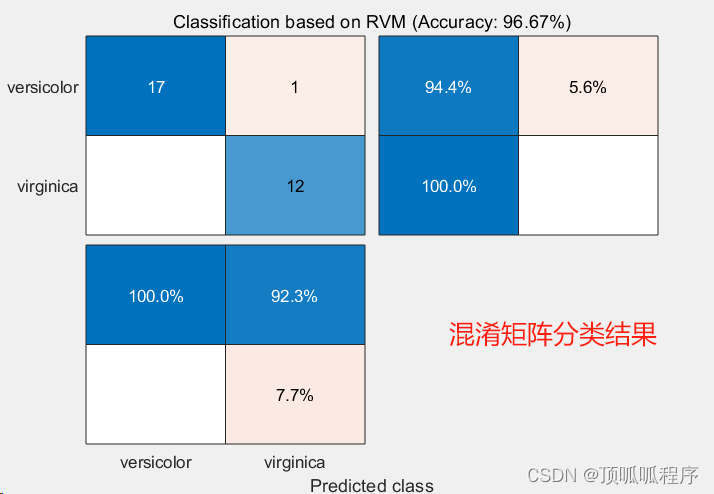
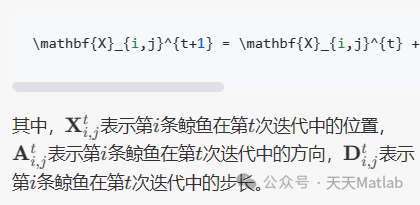
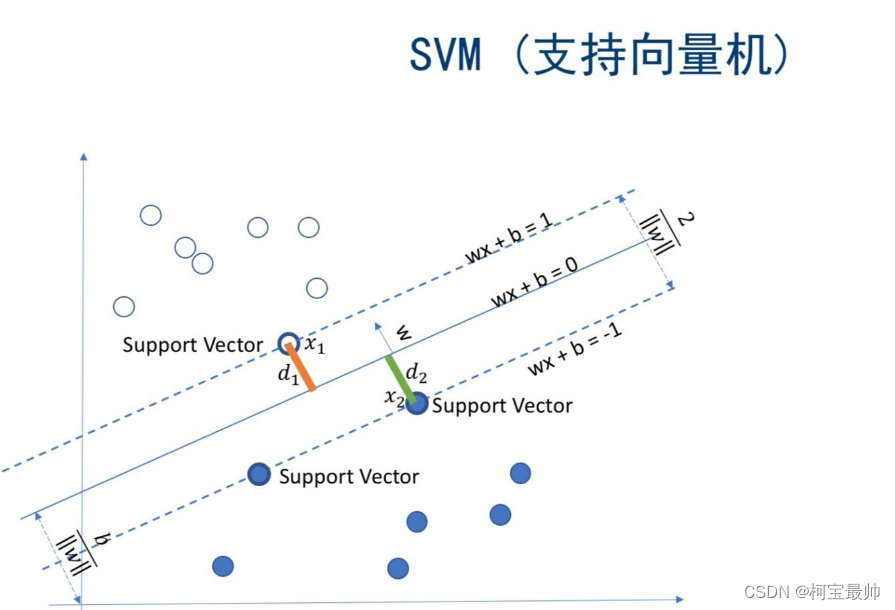
一、相关向量机RVM与支持向量机SVM对比
1、相关向量机(RVM)
①定义与原理
相关向量机(Relevance Vector Machine, RVM)是一种基于概率模型的机器学习算法,主要用于分类和回归分析。基于稀疏贝叶斯学习框架,通过自动选择一小部分相关向量来进行回归或分类任务。RVM使用贝叶斯公式对权重进行更新和调整,通过最大化似然函数来更新权重,并利用高斯过程进行建模。这种方法可以在训练时自动调整权重,以适应数据的变化和不确定性。
常用的核函数有rbf(高斯)径向基核函数、liner线性核函数、poly多项式核函数。高斯核函数是径向基核函数的一种,但在RVM中rbf径向基核函数特指高斯核函数。
②结构与组成
RVM由输入层、隐含层和输出层组成。输入层负责接收外部数据,隐含层负责数据计算和加工,输出层负责输出结果。其中,隐含层中的权重和偏置可以通过训练得到,以实现最优的分类或回归效果。
③优势与应用
RVM高效、灵活、易于理解!与传统的支持向量机(SVM)相比,RVM需要的训练时间更短,且可以在处理高维数据时表现更优秀。此外,RVM还具有很好的可解释性,可以帮助用户理解模型的决策过程。
RVM可以应用于各种领域,如金融、医疗、图像处理等。例如,在金融领域中,RVM可以用于信用评级和风险评估;在医疗领域中,RVM可以用于疾病诊断和预测;在图像处理领域中,RVM可以用于图像分类和识别。
2、支持向量机(SVM)
①定义与原理
支持向量机(Support Vector Machine, SVM)是一种二分类模型,其目标是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化。SVM通过引入核函数方法,克服了维数灾难和非线性可分的问题,向高维空间映射时没有增加计算的复杂性。SVM的最终决策函数只由少数的支持向量所确定,因此计算的复杂性取决于支持向量的数目,而不是样本空间的维数。
②优势与局限
SVM算法具有在小样本情况下表现优异、泛化能力强等优点。然而,SVM对于大规模训练样本难以实施,因为SVM算法借助二次规划求解支持向量,这其中会涉及m阶矩阵的计算,当矩阵阶数很大时将耗费大量的机器内存和运算时间。此外,经典SVM算法只给出了二分类的算法,对于多分类问题解决效果并不理想。
3、RVM与SVM的对比
- 优化目标:
- RVM:基于贝叶斯框架,通过最大化边缘似然函数来选择相关向量,实现稀疏化。
- SVM:寻找最大间隔的超平面进行样本分割。
- 计算复杂度:
- RVM:在处理高维数据时表现更优秀,训练时间相对较短。
- SVM:对于大规模训练样本,计算复杂度较高,特别是在高维空间中。
- 模型稀疏性:
- RVM:通过自动选择相关向量,模型更加稀疏。
- SVM:虽然决策函数由支持向量决定,但支持向量的数量可能较多,不一定总是稀疏的。
- 输出类型:
- RVM:可以给出概率型的输出,具有更好的可解释性。
- SVM:输出为分类标签或回归值,不直接提供概率信息。
- 适用场景:
- RVM:由于其高效、灵活和稀疏性,适用于需要快速训练和解释的场景。
- SVM:在小样本情况下表现优异,广泛应用于各种分类和回归问题。
二、Python算例——RVM回归预测&分类
1、定义RVM基类——BaseRVM
由于sklearn中没现成的相关向量机库,可以借助sklearn-SVM库的API(继承它一些功能),再根据需要编写一些独属RVM的类,即可实现RVM模型。由于自己学习笔记的特征,博主特地加了详细注释:
import numpy as np
from scipy.optimize import minimize
from scipy.special import expit
from sklearn.base import BaseEstimator, RegressorMixin, ClassifierMixin
from sklearn.metrics.pairwise import (
linear_kernel,
rbf_kernel,
polynomial_kernel
)
from sklearn.multiclass import OneVsOneClassifier
from sklearn.utils.validation import check_X_y
#sklearn中不存在标准的RVM需要的类,属于SVM的变种。需要自己定义RVM的类,回归和分类都有。(对象的三大属性:封装、继承、多态)
class BaseRVM(BaseEstimator):
"""提供RVM共通的方法或属性——无论分类还是回归都会用到
继承了scikit-learn API中的BaseEstimator类。添加后验加权方法和预测,用于分类或回归的子类。
"""
def __init__(
self,
kernel='rbf',
degree=3,
coef1=None,
coef0=0.0,
n_iter=3000,
tol=1e-3,
alpha=1e-6,
threshold_alpha=1e9,
beta=1.e-6,
beta_fixed=False,
bias_used=True,
verbose=False
): #定义属性变量时,已经设置好了默认值
"""类定义的一般格式。使用时通过对象.属性名的方式访问,如BaseRVM.kernel(类中的函数也是:对象.函数名方式访问使用)"""
self.kernel = kernel #基函数(核函数),一般rbf为径向基函数,poly为多项式核
self.degree = degree #当kernel为'poly'时,此参数指定多项式的度。对于其他类型的核,此参数将被忽略。
self.coef1 = coef1 #当使用'rbf'或'poly'核时,此参数用于指定核函数的第一个系数。对于'rbf',影响径向基函数的宽度或平滑度。对于'poly',影响多项式核的系数。如果设置为None,则使用默认的核函数参数
self.coef0 = coef0 #当使用'poly'(多项式)核时,此参数指定多项式核的常数项。对于其他类型的核,此参数将被忽略
self.n_iter = n_iter #迭代的最大次数。RVM通过迭代优化过程来找到最佳的相关性向量
self.tol = tol #收敛容差。当算法连续迭代中alpha值的变化小于此容差时,认为算法已经收敛,停止迭代
self.alpha = alpha #所有基础函数的初始alpha值(即每个基础函数的先验精度)。在RVM中,alpha值越大,对应的基础函数越有可能成为相关性向量。
self.threshold_alpha = threshold_alpha #用于裁剪(prune)过程的阈值。alpha值大于此阈值的基础函数将被保留为相关性向量
self.beta = beta #噪声精度的初始值。在RVM中,beta值控制了对观测噪声的估计
self.beta_fixed = beta_fixed #指定beta值是否在整个训练过程中保持不变。如果为True,则beta值在训练过程中不会更新
self.bias_used = bias_used #指定是否在模型中包含偏置项(即常数项)。对于许多实际问题,包含偏置项可以提高模型的灵活性
self.verbose = verbose #控制是否打印训练过程中的额外信息。如果为True,则训练过程中会打印迭代次数、alpha值、beta值等信息.
def get_params(self, deep=True):
"""将类的所有参数(即属性)以字典的形式返回。这是遵循scikit-learn API的一种常见做法,使得模型的参数可以很容易地被获取和检查。
deep参数通常用于控制是否递归地获取嵌套对象(例如,如果模型的某些属性也是具有get_params方法的scikit-learn兼容对象)的参数。
然而,在这个例子中,BaseRVM类并没有这样的嵌套对象,因此deep参数没有被用到。
"""
params = {
'kernel': self.kernel,
'degree': self.degree,
'coef1': self.coef1,
'coef0': self.coef0,
'n_iter': self.n_iter,
'tol': self.tol,
'alpha': self.alpha,
'threshold_alpha': self.threshold_alpha,
'beta': self.beta,
'beta_fixed': self.beta_fixed,
'bias_used': self.bias_used,
'verbose': self.verbose
}
return params
def set_params(self, **parameters):
"""set_params方法也是scikit-learn API中的一部分,用于通过关键字参数(kwargs)设置对象的参数(即属性)。
set_params方法使得用户可以一次性地更新模型的多个参数,而不需要单独调用每个属性的setter方法。
**parameters可变关键字参数允许传入任意数量的关键字参数。
通过遍历parameters字典的项(即参数名和对应的值),使用setattr函数动态地将每个参数名(parameter)作为属性名,将对应的值(value)作为属性值,设置到当前对象(self)上。
"""
for parameter, value in parameters.items():
setattr(self, parameter, value) #setattr函数设置对象的属性值。第一个参数是要设置属性的对象,第二个参数是属性名(作为字符串),第三个参数是要设置的新属性值。
return self #set_params方法返回当前对象(self),这允许链式调用,即可以在一个表达式中连续调用多个方法。例如有一个模型对象model想要一次性设置kernel和degree参数:model.set_params(kernel='rbf', degree=3)
def _apply_kernel(self, x, y):
"""根据选择的核函数,进行对应的运算。线性、径向基、多项式、自定义核"""
if self.kernel == 'linear':
phi = linear_kernel(x, y)
elif self.kernel == 'rbf':
phi = rbf_kernel(x, y, self.coef1)
elif self.kernel == 'poly':
phi = polynomial_kernel(x, y, self.degree, self.coef1, self.coef0)
elif callable(self.kernel):
phi = self.kernel(x, y)
if len(phi.shape) != 2:
raise ValueError(
"Custom kernel function did not return 2D matrix"
)
if phi.shape[0] != x.shape[0]:
raise ValueError(
"Custom kernel function did not return matrix with rows"
" equal to number of data points."""
)
else:
raise ValueError("Kernel selection is invalid.")
if self.bias_used: #如果self.bias_used为True,则在返回的核函数结果phi上添加一个偏置项。
phi = np.append(phi, np.ones((phi.shape[0], 1)), axis=1) #通过在phi矩阵的末尾添加一列全1来实现的,使用np.append函数沿着列方向(axis=1)添加
return phi
def _prune(self):
"""根据 alpha 值的阈值来移除基础函数"""
# 根据alpha值是否小于阈值threshold_alpha来确定哪些基础函数需要保留
keep_alpha = self.alpha_ < self.threshold_alpha
# 如果没有任何alpha值小于阈值,则至少保留第一个基础函数
# 如果模型中使用了偏置项(bias_used为True),则也保留最后一个基础函数(通常是偏置项)
if not np.any(keep_alpha):
keep_alpha[0] = True
if self.bias_used:
keep_alpha[-1] = True
# 如果模型中使用了偏置项
if self.bias_used:
# 如果最后一个基础函数(偏置项)不在保留列表中,则设置bias_used为False
if not keep_alpha[-1]:
self.bias_used = False
# 更新relevance_数组,移除不需要的基础函数的相关性信息
# 注意这里使用keep_alpha[:-1]来排除偏置项(如果存在且不需要保留)
self.relevance_ = self.relevance_[keep_alpha[:-1]]
else:
# 如果模型中没有使用偏置项,则直接根据keep_alpha来更新relevance_数组
self.relevance_ = self.relevance_[keep_alpha]
# 更新alpha_数组,只保留需要的基础函数的alpha值
self.alpha_ = self.alpha_[keep_alpha]
# 更新alpha_old数组,与alpha_相同,只保留需要的值
self.alpha_old = self.alpha_old[keep_alpha]
# 更新gamma数组,只保留与保留的基础函数相关的值
self.gamma = self.gamma[keep_alpha]
# 更新phi矩阵,只保留与保留的基础函数相关的列
self.phi = self.phi[:, keep_alpha]
# 更新sigma_矩阵,这是一个协方差矩阵,只保留与保留的基础函数相关的行和列
self.sigma_ = self.sigma_[np.ix_(keep_alpha, keep_alpha)]
# 更新m_数组,只保留需要的基础函数的m值(可能是某种均值或参数)
self.m_ = self.m_[keep_alpha]
"""通过修改与这些基础函数相关的各种属性(如 alpha_, gamma, phi, sigma_, m_ 等)来实现对基础函数的剪枝(即移除不重要的基础函数)
贝叶斯学习的特性:通过自动确定哪些输入特征(基础函数)对模型预测最为重要,从而实现模型的稀疏性"""
def fit(self, X, y):
"""Fit the RVR to the training data."""
# 检查输入数据X和y是否符合要求
X, y = check_X_y(X, y)
# 获取样本数量和特征数量
n_samples, n_features = X.shape
# 应用核函数计算phi矩阵,phi矩阵是输入数据X通过核函数转换后的结果
# 在RVM中,phi矩阵通常用于表示基础函数的激活程度
self.phi = self._apply_kernel(X, X)
# 获取基础函数的数量,即phi矩阵的列数
n_basis_functions = self.phi.shape[1]
# 初始化relevance_为X(这里可能是个错误,通常relevance_应该用于存储与基础函数相关性的某种度量)
# 在实际实现中,relevance_可能需要在后续步骤中根据alpha值或其他标准来更新
self.relevance_ = X
self.y = y # 存储目标变量
# 初始化alpha_(基础函数的权重或重要性度量)为alpha(一个超参数)乘以全1向量
self.alpha_ = self.alpha * np.ones(n_basis_functions)
self.beta_ = self.beta # 初始化beta_(噪声精度或噪声方差的倒数)
# 初始化m_(基础函数的均值或参数)为零向量
self.m_ = np.zeros(n_basis_functions)
# 保存旧的alpha_值以便后续比较
self.alpha_old = self.alpha_
# 执行迭代优化过程
for i in range(self.n_iter):
# 执行后验更新步骤,通常涉及计算m_和sigma_(协方差矩阵)
self._posterior()
# 更新gamma,它可能与alpha_和sigma_的对角线元素有关
self.gamma = 1 - self.alpha_ * np.diag(self.sigma_)
# 更新alpha_,通常基于gamma和m_的平方
self.alpha_ = self.gamma / (self.m_ ** 2)
# 如果beta_不是固定的,则更新beta_
if not self.beta_fixed:
# beta_的更新公式通常涉及样本数量、gamma的总和以及残差平方和
self.beta_ = (n_samples - np.sum(self.gamma)) / (
np.sum((y - np.dot(self.phi, self.m_)) ** 2))
# 执行剪枝步骤,移除不重要的基础函数
self._prune()
# 如果启用了详细输出,则打印当前迭代的信息
if self.verbose:
print("Iteration: {}".format(i))
print("Alpha: {}".format(self.alpha_))
print("Beta: {}".format(self.beta_))
print("Gamma: {}".format(self.gamma))
print("m: {}".format(self.m_))
print("Relevance Vectors: {}".format(self.relevance_.shape[0]))
print()
# 检查alpha_的变化是否小于容忍度tol,并且迭代次数大于1,如果是,则提前终止迭代
delta = np.amax(np.absolute(self.alpha_ - self.alpha_old))
if delta < self.tol and i > 1:
break
# 更新alpha_old为当前alpha_的值,以便下一次迭代比较
self.alpha_old = self.alpha_
# 如果模型中使用了偏置项,则将偏置项的值存储在self.bias中
if self.bias_used:
self.bias = self.m_[-1]
else:
self.bias = None
return self # 返回拟合后的模型实例2、定义RVM-回归Regression类——RVR
继承BaseRVM基类功能,实现RVM的回归预测功能。
class RVR(BaseRVM, RegressorMixin):
"""相关向量机RVM回归问题Regression——RVR
Implementation of Mike Tipping's Relevance Vector Machine for regression
借助scikit-learn API
"""
def _posterior(self):
"""计算权重(或基础函数参数)的后验分布。通过求解后验均值(m_)和后验协方差(sigma_)来实现"""
i_s = np.diag(self.alpha_) + self.beta_ * np.dot(self.phi.T, self.phi) #中间变量i_s
self.sigma_ = np.linalg.inv(i_s) #通过中间变量i_s计算后验协方差矩阵sigma_
self.m_ = self.beta_ * np.dot(self.sigma_, np.dot(self.phi.T, self.y)) #计算后验均值向量m_ ,其中 self.y 是目标变量。
def predict(self, X, eval_MSE=False):
"""对新的输入数据 X 进行预测,并可选地计算预测的均方误差(MSE)"""
phi = self._apply_kernel(X, self.relevance_) #计算新的输入数据 X 与当前相关性向量(self.relevance_)之间的核函数值,存储在 phi 中
y = np.dot(phi, self.m_) #预测y值
if eval_MSE:
MSE = (1 / self.beta_) + np.dot(phi, np.dot(self.sigma_, phi.T))
return y, MSE[:, 0] #返回预测值 y 和MSE的每一行的第一个元素(假设MSE是一个二维数组,每行对应一个输入样本的MSE)
else:
return y3、定义RVM-分类Classification类——RVC
继承BaseRVM基类功能,实现RVM的分类功能。
class RVC(BaseRVM, ClassifierMixin):
"""相关向量机RVM分类问题——简称RVC
Implementation of Mike Tipping's Relevance Vector Machine for
借助 scikit-learn API.
"""
def __init__(self, n_iter_posterior=50, **kwargs):
"""Copy params to object properties, no validation."""
self.n_iter_posterior = n_iter_posterior
super(RVC, self).__init__(**kwargs)
def get_params(self, deep=True):
"""Return parameters as a dictionary."""
params = super(RVC, self).get_params(deep=deep)
params['n_iter_posterior'] = self.n_iter_posterior
return params
def _classify(self, m, phi):
return expit(np.dot(phi, m))
def _log_posterior(self, m, alpha, phi, t):
y = self._classify(m, phi)
log_p = -1 * (np.sum(np.log(y[t == 1]), 0) +
np.sum(np.log(1 - y[t == 0]), 0))
log_p = log_p + 0.5 * np.dot(m.T, np.dot(np.diag(alpha), m))
jacobian = np.dot(np.diag(alpha), m) - np.dot(phi.T, (t - y))
return log_p, jacobian
def _hessian(self, m, alpha, phi, t):
y = self._classify(m, phi)
B = np.diag(y * (1 - y))
return np.diag(alpha) + np.dot(phi.T, np.dot(B, phi))
def _posterior(self):
result = minimize(
fun=self._log_posterior,
hess=self._hessian,
x0=self.m_,
args=(self.alpha_, self.phi, self.t),
method='Newton-CG',
jac=True,
options={
'maxiter': self.n_iter_posterior
}
)
self.m_ = result.x
self.sigma_ = np.linalg.inv(
self._hessian(self.m_, self.alpha_, self.phi, self.t)
)
def fit(self, X, y):
"""Check target values and fit model."""
self.classes_ = np.unique(y)
n_classes = len(self.classes_)
if n_classes < 2:
raise ValueError("Need 2 or more classes.")
elif n_classes == 2:
self.t = np.zeros(y.shape)
self.t[y == self.classes_[1]] = 1
return super(RVC, self).fit(X, self.t)
else:
self.multi_ = None
self.multi_ = OneVsOneClassifier(self)
self.multi_.fit(X, y)
return self
def predict_proba(self, X):
"""Return an array of class probabilities."""
phi = self._apply_kernel(X, self.relevance_)
y = self._classify(self.m_, phi)
return np.column_stack((1 - y, y))
def predict(self, X):
"""Return an array of classes for each input."""
if len(self.classes_) == 2:
y = self.predict_proba(X)
res = np.empty(y.shape[0], dtype=self.classes_.dtype)
res[y[:, 1] <= 0.5] = self.classes_[0]
res[y[:, 1] >= 0.5] = self.classes_[1]
return res
else:
return self.multi_.predict(X)4、RVR算例——boston房价数据回归预测
boston数据包含10+个特征变量X和一个目标变量y(房价)。代码只能输入多维特征X(二维矩阵),不能输入一个特征x。
对比了SVM和RVM分别使用不同核函数的回归预测效果,评价指标是R^2。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold, StratifiedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import plot_confusion_matrix
from sklearn.svm import SVC
from sklearn.svm import SVR
from sklearn.datasets import load_boston
from sklearn.datasets import load_breast_cancer
plt.rcParams['font.sans-serif'] = ['SimSun'] # 指定默认字体为宋体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
#回归测试——波士顿房价数据集(多个特征变量X构成一个二维矩阵,目前不支持单一的特征变量;一个目标变量y房价)
X, y = load_boston(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
scaler = StandardScaler()
scaler.fit(X_train)
X_train_s = scaler.transform(X_train)
X_test_s = scaler.transform(X_test)
#支持向量机SVM效果:(不同核函数)
#线性核函数
model = SVR(kernel="linear")
model.fit(X_train_s, y_train)
print(f"SVM-线性核函数R^2 score:{model.score(X_test_s, y_test)}")
#二次多项式核
model = SVR(kernel="poly", degree=2)
model.fit(X_train_s, y_train)
print(f"SVM-二次多项式核函数R^2 score:{model.score(X_test_s, y_test)}")
#三次多项式
model = SVR(kernel="poly", degree=3)
model.fit(X_train_s, y_train)
print(f"SVM-三次多项式核函数R^2 score:{model.score(X_test_s, y_test)}")
##(高斯)径向基核函数
model = SVR(kernel="rbf")
model.fit(X_train_s, y_train)
print(f"SVM-径向基核函数R^2 score:{model.score(X_test_s, y_test)}")
#S核
model = SVR(kernel="sigmoid")
model.fit(X_train_s, y_train)
print(f"SVM-sigmoid核函数R^2 score:{model.score(X_test_s, y_test)}")
# 相关向量机(RVM)效果:
#线性核函数
model = RVR(kernel="linear")
model.fit(X_train_s, y_train)
print(f"RVM-线性核函数R^2 score:{model.score(X_test_s, y_test)}")
#(高斯)径向基核函数
model = RVR(kernel="rbf")
model.fit(X_train_s, y_train)
print(f"RVM-径向基核函数R^2 score:{model.score(X_test_s, y_test)}")
#多项式核函数,上面基类中默认时3次多项式)
model = RVR(kernel="poly")
model.fit(X_train_s, y_train)
print(f"RVM-三次多项式核函数R^2 score:{model.score(X_test_s, y_test)}")
运行结果如下,可见RVM使用径向基核函数时0.92302表现最佳,选用RVM-rbf核函数做最终预测。

5、选定得分最高的RVR-rbf核函数作为最终预测
并加入可视化方式:实际值-预测值图&残差图。并输入新的X特征,预测得到房价。
#(高斯)径向基核函数
model = RVR(kernel="rbf")
model.fit(X_train_s, y_train)
print(f"RVM-径向基核函数R^2 score:{model.score(X_test_s, y_test)}")
#结果可视化:实际值-预测值散点图,越接近y=x直线说明越好。残差图:预测值与实际值的差异
y_pred = model.predict(X_test_s)
plt.scatter(y_test, y_pred)
plt.xlabel('Actual Price')
plt.ylabel('Predicted Price')
plt.title('Actual vs Predicted Prices')
plt.show() #实际值-预测值散点图
plt.scatter(y_pred, y_test - y_pred)
plt.xlabel('Predicted Price')
plt.ylabel('Residuals')
plt.title('Residual Plot')
plt.axhline(y=0, color='black', lw=1) # 添加水平线表示0残差
plt.show() #残差图
#利用模型预测新的房价y值
X_new = np.array([[
0.00632, # 假设的CRIM值
18.0, # 假设的ZN值
2.31, # 假设的INDUS值
0, # 假设的CHAS值(0表示不在查尔斯河边)
0.538, # 假设的NOX值
6.575, # 假设的RM值
65.2, # 假设的AGE值
4.0900, # 假设的DIS值
1, # 假设的RAD值
296.0, # 假设的TAX值
15.3, # 假设的PTRATIO值
396.90, # 假设的B值(根据公式计算或从某处获得)
4.98 # 假设的LSTAT值
]])
X_new_s = scaler.transform(X_new)
predicted_price = model.predict(X_new_s)
print(f"Predicted Price: {predicted_price[0]}")
实际价格与预测价格关系图如下,理论上应该接近y=x这条直线:

预测价格与残差的关系图,理论上应该接近0:

输入X特征向量二维数组,利用拟合的模型预测的价格结果如下: