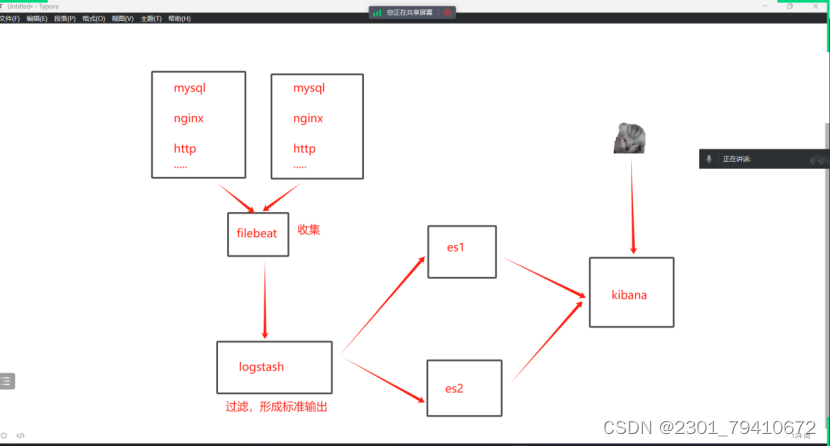
ELK是ElasticSerach、Logstash、Kina
Logstash负责采集数据,Logstash有三个插件,input、filter、output,filter插件作用是对采集的数据进行处理,过滤的,因此filter插件可以选,可以不用配置。
ElasticSearch负责存储数据和检索数据。
Kina负责展示数据。
这三个补充配置样例:
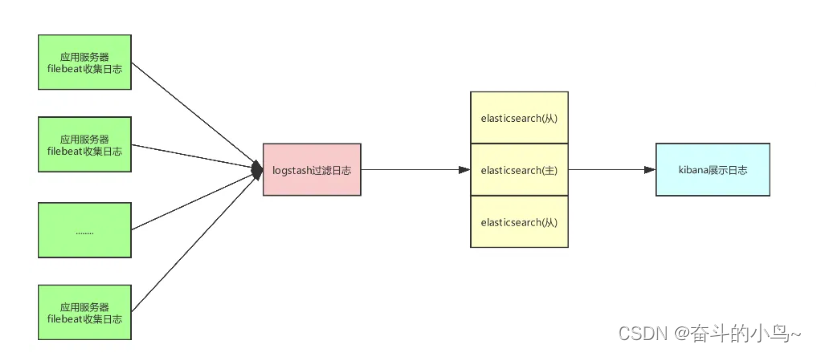
一个常见的部署方案,如下图所示,部署思路是:
(1)在每台生成日志文件的机器上,部署Logstash,作为Shipper的角色,负责从日志文件中提取数据,但是不做任何处理,直接将数据输出到Redis队列(list)中;
(2)需要一台机器部署Logstash,作为Indexer的角色,负责从Redis中取出数据,对数据进行格式化和相关处理后,输出到Elasticsearch中存储;
(3)部署Elasticsearch集群,当然取决于你的数据量了,数据量小的话可以使用单台服务,如果做集群的话,最好是有3个以上节点,同时还需要部署相关的监控插件;
(4)部署Kibana服务,提供Web服务。

在前期部署阶段,主要工作是Logstash节点和Elasticsearch集群的部署,而在后期使用阶段,主要工作就是Elasticsearch集群的监控和使用Kibana来检索、分析日志数据了,当然也可以直接编写程序来消费Elasticsearch中的数据。
在上面的部署方案中,我们将Logstash分为Shipper和Indexer两种角色来完成不同的工作,中间通过Redis做数据管道,为什么要这样做?为什么不是直接在每台机器上使用Logstash提取数据、处理、存入Elasticsearch?
首先,采用这样的架构部署,有三点优势:第一,降低对日志所在机器的影响,这些机器上一般都部署着反向代理或应用服务,本身负载就很重了,所以尽可能的在这些机器上少做事;第二,如果有很多台机器需要做日志收集,那么让每台机器都向Elasticsearch持续写入数据,必然会对Elasticsearch造成压力,因此需要对数据进行缓冲,同时,这样的缓冲也可以一定程度的保护数据不丢失;第三,将日志数据的格式化与处理放到Indexer中统一做,可以在一处修改代码、部署,避免需要到多台机器上去修改配置。
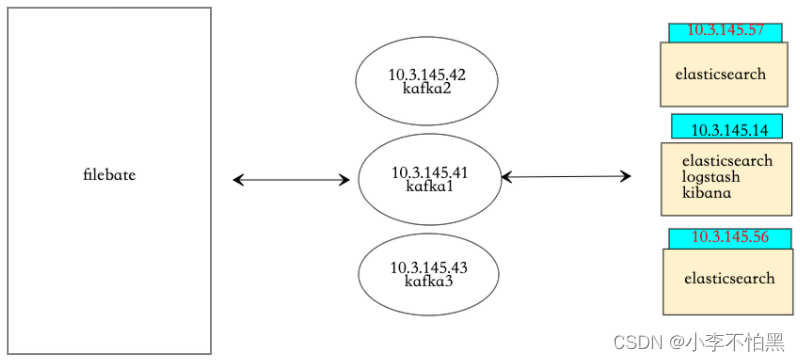
其次,我们需要做的是将数据放入一个消息队列中进行缓冲,所以Redis只是其中一个选择,也可以是RabbitMQ、Kafka等等,在实际生产中,Redis与Kafka用的比较多。由于Redis集群一般都是通过key来做分片,无法对list类型做集群,在数据量大的时候必然不合适了,而Kafka天生就是分布式的消息队列系统。

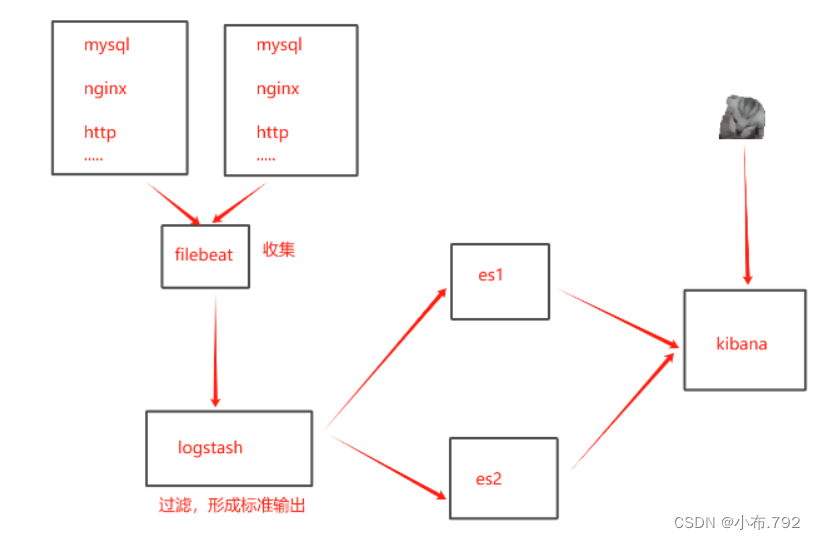
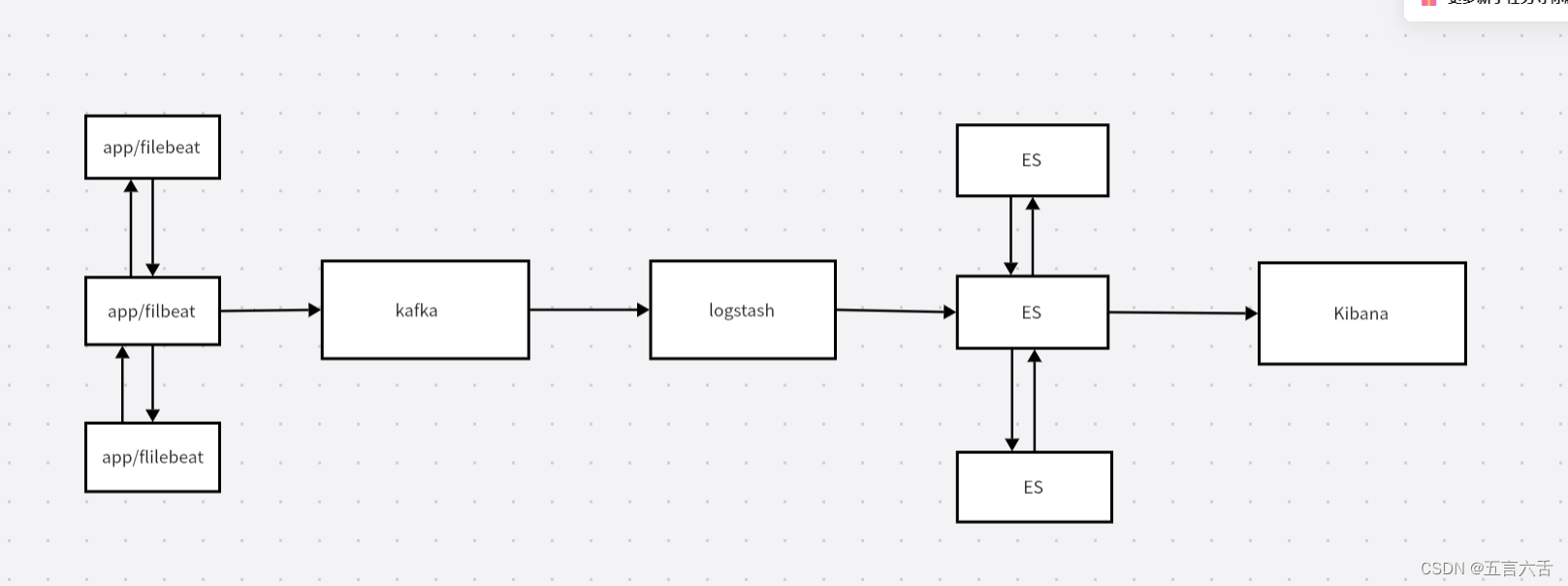
基本思路是:在服务器上装logstash(这个是filebeat也有的),这个logstash只配置input和output,采集数据,往kakfa中写,然后在部署一个logstash读取kafka的数据进行处理,然后往ElasticSearch中写数据。然后用Kibana读取ElasticSearch中的数据进行展示。
也有的思路是这样的:
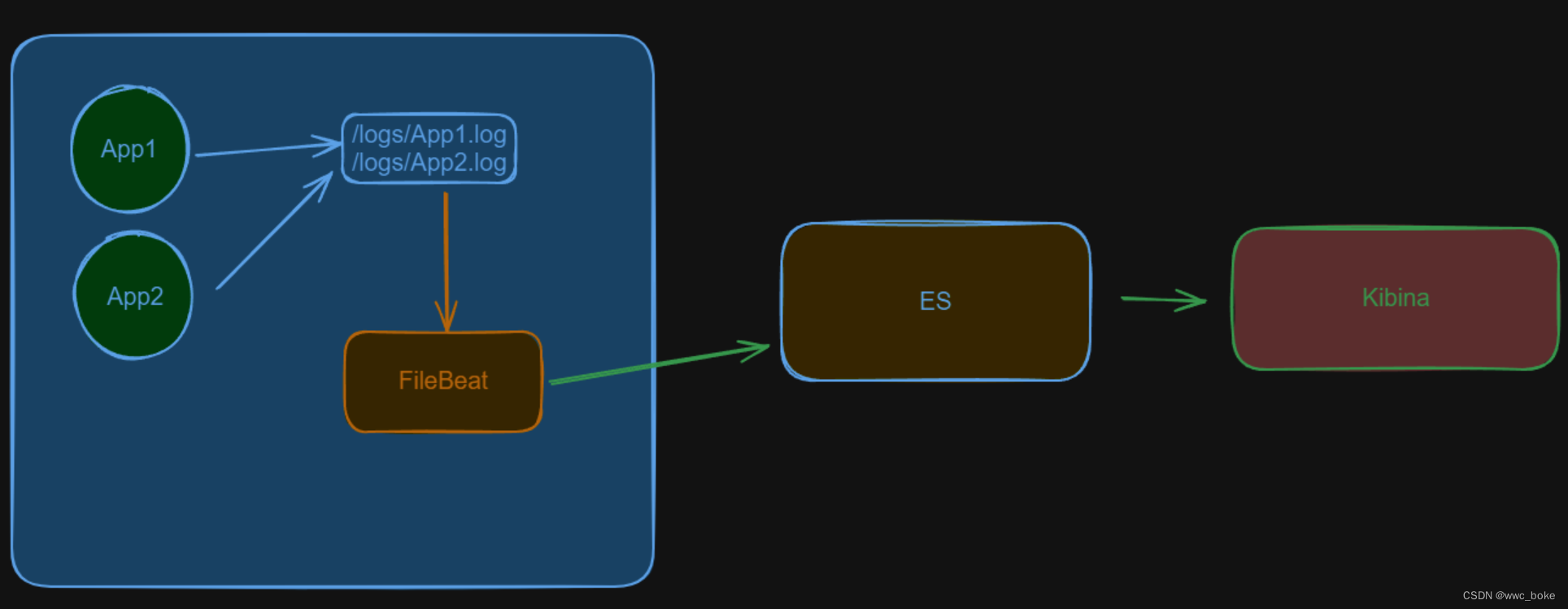
在web服务器上面安装耗费资源较小的filebeat,然后配置filebeat文件,通过filebeat将日志文件,推送到logstash,经过logstash收集分析,存放到es中,在通过kibana展现出来。
因为logstash是及其耗费服务器资源的,所以在每台需要收集信息的服务器上面安装logstash是及其耗费资源,因此安装filebeat。
参考资料:https://www.cnblogs.com/WUXIAOCHANG/p/11024092.html
Logstash介绍 - 墨天轮更多精彩,请点击上方蓝字关注我们!1 Logstash简介1.1 Logstash是什么?Logstash是![]() https://www.modb.pro/db/456495
https://www.modb.pro/db/456495
filebeat的总结:
为什么要用Filebeat?
当面对成百上千、甚至成千上万的服务器、虚拟机和容器生成的日志时,Filebeat可以提供一种轻量型方法,用于转发和汇总日志与文件,关于Filebeat的记住以下两点:
轻量级日志采集器
输送至ElasticSearch或者Logstash,在Kibana中实现可视化
架构
用于监控、收集服务器日志文件.
流程如下:
首先是input(input是filebeat的新版本,老版本的filebeat用prospector)输入,可以指定多个数据输入源,然后通过通配符进行日志文件的匹配
匹配到日志后,就会使用Harvester(收割机),将日志源源不断的读取到来
然后收割机收割到的日志,就传递到Spooler(卷轴),然后卷轴就在将他们传到对应的地方。
input和prospector负责管理harvester,并找到所有要读取的文件来源。
filebeat.inputs 与 filebeat.prospectors区别
Filebeat 从 7.x 版本开始引入了新的配置方式 filebeat.inputs,以提供更灵活的输入配置选项,同时保留了向后兼容性。以下是 filebeat.inputs 和 filebeat.prospectors 之间的主要区别:
filebeat.inputs:
filebeat.inputs 是较新版本的配置方式,用于定义输入配置。
允许您以更灵活的方式配置不同类型的输入。您可以在配置文件中定义多个独立的输入块,每个块用于配置不同类型的输入。
每个输入块可以包含多个字段,用于定制不同输入类型的配置,如 type、enabled、paths、multiline 等。
使配置更具可读性,因为每个输入类型都有自己的配置块。
参考资料:
Filebeat详细介绍,下载和启动,日志读取和模块设置等-CSDN博客文章浏览阅读7.7k次,点赞2次,收藏27次。Filebeat是一个轻量级的日志采集器当我们的元数据没办法支撑我们的业务时,我们还可以自定义添加一些字段tags: [ "web" , "test" ] #添加自定义tag,便于后续的处理 fields: #添加自定义字段 from: web-testfields_under_root: true #true为添加到根节点,false为添加到子节点中 setup.template.settings:添加完成后,重启 filebeat然后添加新的数据到 test.log中。_filebeathttps://blog.csdn.net/qq_52589631/article/details/131216188轻量级的日志采集组件 Filebeat_filebeat 采集的日志类型有那些-CSDN博客文章浏览阅读390次。Filebeat是一个轻量级的日志数据收集工具,属于Elastic公司的Elastic Stack(ELK Stack)生态系统的一部分。它的主要功能是从各种来源收集日志数据,将数据发送到Elasticsearch、Logstash或其他目标,以便进行搜索、分析和可视化。轻量级:Filebeat是一个轻量级的代理,对系统资源的消耗非常低。它设计用于高性能和低延迟,可以在各种环境中运行,包括服务器、容器和虚拟机。多源收集。_filebeat 采集的日志类型有那些
https://blog.csdn.net/ststcheung/article/details/133381507
Filebeat和Logstash是用于收集、过滤和传输日志数据的工具,它们的主要区别如下:
功能定位:Filebeat是一个轻量级的日志收集器,主要用于从文件中读取日志行并将其传输到其他地方,如Elasticsearch或Logstash。Logstash是一个功能强大的数据处理管道,可以从多种来源接收数据,并进行复杂的转换和过滤,然后将数据发送到许多不同的目标。
处理能力:虽然Filebeat可以对日志进行基本的解析和过滤,但是它的处理能力相对较弱。相比之下,Logstash提供了更多的过滤插件和处理选项,可以进行更复杂的数据转换和处理操作。
资源消耗:由于其轻量级的设计,Filebeat占用的系统资源较少,适用于在较小的环境中部署。而Logstash由于其更强大的功能和灵活性,需要更多的系统资源来运行,适用于大规模的日志处理任务。
插件生态系统:Logstash有一个庞大的插件生态系统,可以方便地扩展其功能和支持更多的数据源和目标。Filebeat的插件生态系统相对较小,主要集中在输出插件方面。
总的来说,Filebeat适用于简单的日志收集和传输任务,而Logstash适用于更复杂的数据处理和转换任务。选择使用哪个工具应根据实际需求和系统资源的可用性来决定。