文章目录
Hadoop之HDFS重点架构原理
一、什么是Hadoop
分布式系统基础架构,旨在解决海量数据存储和计算分析问题,核心组件:HDFS + MapReduce + Yarn。
二、HDFS简介
Hadoop Distributed File System - 分布式文件存储系统,解决海量数据存储问题。
三、HDFS架构
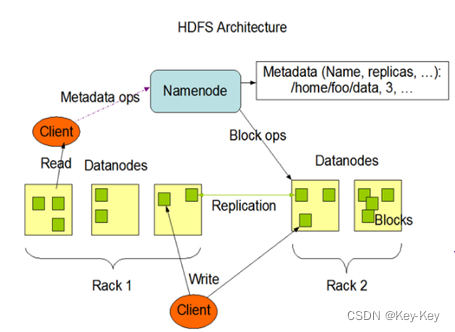
3.1、NameNode
NameNode就是主从架构中的Master,是HDFS中的管理者。HDFS中数据文件分布式存储在各个DataNode节点上,NameNode维护和管理文件系统元数据(空间目录树结构、文件、Block信息、访问权限),随着存储文件的增多,NameNode上存储的信息越来越多,NameNode主要通过两个组件实现元数据管理:fsimage(命名空间镜像文件)和editslog(编辑日志)。
fsimage:HDFS文件系统元数据的镜像文件,其中包含了HDFS文件系统的所有目录和文件相关信息元数据。
editslog:用户操作HDFS的编辑日志文件,存放HDFS文件系统的所有操作事件,文件的所有写操作会被记录到Edits文件中
NameNode作用:
完全基于内存存储文件元数据、目录结构、文件block的映射信息。
提供文件元数据持久化/管理方案。
提供副本放置策略。
处理客户端读写请求。
3.2、SecondaryNameNode
随着操作HDFS的数据变多,久而久之就会造成edits文件变的很大,如果namenode重启后再一条条执行edits日志恢复状态就需要很长时间,导致重启速度慢,所以在NameNode运行的时候就需要将editslog和fsimage定期合并。这个合并操作就由SecondaryNameNode负责。
所以SecondaryNameNode作用就是辅助NameNode定期合并fsimage和editslog,并将合并后的fsimage推送给NameNode。
3.3、DataNode
DataNode是主从架构中的Slave,DataNode存储文件block块,Block在DataNode上以文件形式存储在磁盘上,包括2个文件,一个是数据文件本身,一个是元数据(包括block长度、block校验和、时间戳)。当DataNode启动后会向NameNode进行注册,并汇报block列表信息,后续会周期性(参数dfs.blockreport.intervalMsec决定,默认6小时)向NameNode上报所有的块信息。同时,DataNode会每隔3秒与NameNode保持心跳,如果超过10分钟NameNode没有收到某个DataNode的心跳,则认为该节点不可用。
DataNode作用:
基于本地磁盘存储block数据块。
保存block的校验和数据保证block的可靠性。
与NameNode保持心跳并汇报block列表信息。
3.4、Client
Client是操作HDFS的客户端。
Client作用:
与NameNode交互,获取文件block位置信息。
与DataNode交互,读写文件block数据。
文件上传时,负责文件切分成block并上传。
可以通过client访问HDFS进行文件操作或管理HDFS。
四、fsimage和editslog合并
当HDFS集群首次启动会在NameNode上创建空的fsimage,对HDFS的操作会记录到editslog文件中。
当开始进行editslog和fsimage合并时,SecondaryNameNode请求namenode生成新的editslog文件并向其中写日志。
SecondaryNameNode通过HTTP GET的方式从NameNode下载fsimage和edits文件到本地。
SecondaryNameNode将fsimage加载到自己的内存,并根据editslog更新内存中的fsimage信息,然后将更新完毕之后的fsimage写到磁盘上。
SecondaryNameNode通过HTTP PUT将新的fsimage文件发送到NameNode,NameNode将该文件保存为.ckpt的临时文件备用。
NameNode重命名该临时文件并准备使用,此时NameNode拥有一个新的fsimage文件和一个新的很小的editslog文件(可能不是空的,因为在SecondaryNameNode合并期间可能对元数据进行了读写操作)。
后续SecondaryNameNode会按照以上步骤周期性进行editslog和fsimage的合并。
注意:合并时机默认间隔1小时(3600s)或者每分钟(60s)editslog存储的事务(即操作数)到了1000000个。
五、Block副本放置策略
HDFS中每个block块有3副本。
第一个副本:放置在上传文件的DataNode,也就是Client所在节点上;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
第二个副本:放置在与第一个副本不同的机架的节点上。
第三个副本:与第二个副本相同机架的随机节点。
更多副本:随机节点存放。
六、读写流程
6.1、HDFS写文件流程
客户端会创建DistributedFileSystem对象,DistributedFileSystem会发起对namenode的一个RPC连接,请求创建一个文件,不包含关于block块的请求。namenode会执行各种各样的检查,确保要创建的文件不存在,并且客户端有创建文件的权限。如果检查通过,namenode会创建一个文件(在edits中,同时更新内存状态),否则创建失败,客户端抛异常IOException。
NN在文件创建后,返回给HDFS Client可以开始上传文件块。
DistributedFileSystem返回一个FSDataOutputStream对象给客户端用于写数据。FSDataOutputStream封装了一个DFSOutputStream对象负责客户端跟datanode以及namenode的通信。
客户端中的FSDataOutputStream对象将数据切分为小的packet数据包(64kb,core-default.xml:file.client-write-packet-size默认值65536),并写入到一个内部队列(“数据队列”)。DataStreamer会读取其中内容,并请求namenode返回一个datanode列表来存储当前block副本。列表中的datanode会形成管线,DataStreamer将数据包发送给管线中的第一个datanode,第一个datanode将接收到的数据发送给第二个datanode,第二个发送给第三个,依次类推。
FSDataOutputStream维护着一个数据包的队列,这的数据包是需要写入到datanode中的,该队列称为确认队列。当一个数据包在管线中所有datanode中写入完成,就从ack队列中移除该数据包。
当block传输完成,DN会向NN汇报block信息,同时Client继续传输下一个block,如果有多个block,则会反复从步骤4开始执行。
当客户端完成了数据的传输,调用数据流的close方法。该方法将数据队列中的剩余数据包写到datanode的管线并等待管线的确认。
客户端收到管线中所有正常datanode的确认消息后,通知namenode文件写入成功。
6.2、HDFS读文件流程
客户端通过FileSystem对象的open方法打开希望读取的文件,DistributedFileSystem对象通过RPC调用namenode,以确保文件起始位置。对于每个block,namenode返回存有该副本的datanode地址。这些datanode根据它们与客户端的距离来排序。如果客户端本身就是一个datanode,并保存有相应block一个副本,会从本地读取这个block数据。
DistributedFileSystem返回一个FSDataInputStream对象给客户端读取数据。该对象管理着datanode和namenode的I/O,用于给客户端使用。客户端对这个输入调用read方法,存储着文件起始几个block的datanode地址的DFSInputStream连接距离最近的datanode。通过对数据流反复调用read方法,可以将数据从datnaode传输到客户端。到达block的末端时,DFSInputSream关闭与该datanode的连接,然后寻找下一个block的最佳datanode。客户端只需要读取连续的流,并且对于客户端都是透明的。
客户端从流中读取数据时,block是按照打开DFSInputStream与datanode新建连接的顺序读取的。它也会根据需要询问namenode来检索下一批数据块的datanode的位置。一旦客户端完成读取,就close掉FSDataInputStream的输入流。
在读取数据的时候如果DFSInputStream在与datanode通信时遇到错误,会尝试从这个块的一个最近邻datanode读取数据。同时也记住故障datanode,保证以后不会反复读取该节点上后续的block。DFSInputStream也会通过校验和确认从datanode发来的数据是否完整。如果发现有损坏的块,DFSInputStream会尝试从其他datanode读取其副本并通知namenode。
Client下载完block后会验证DN中的MD5,保证块数据的完整性。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨