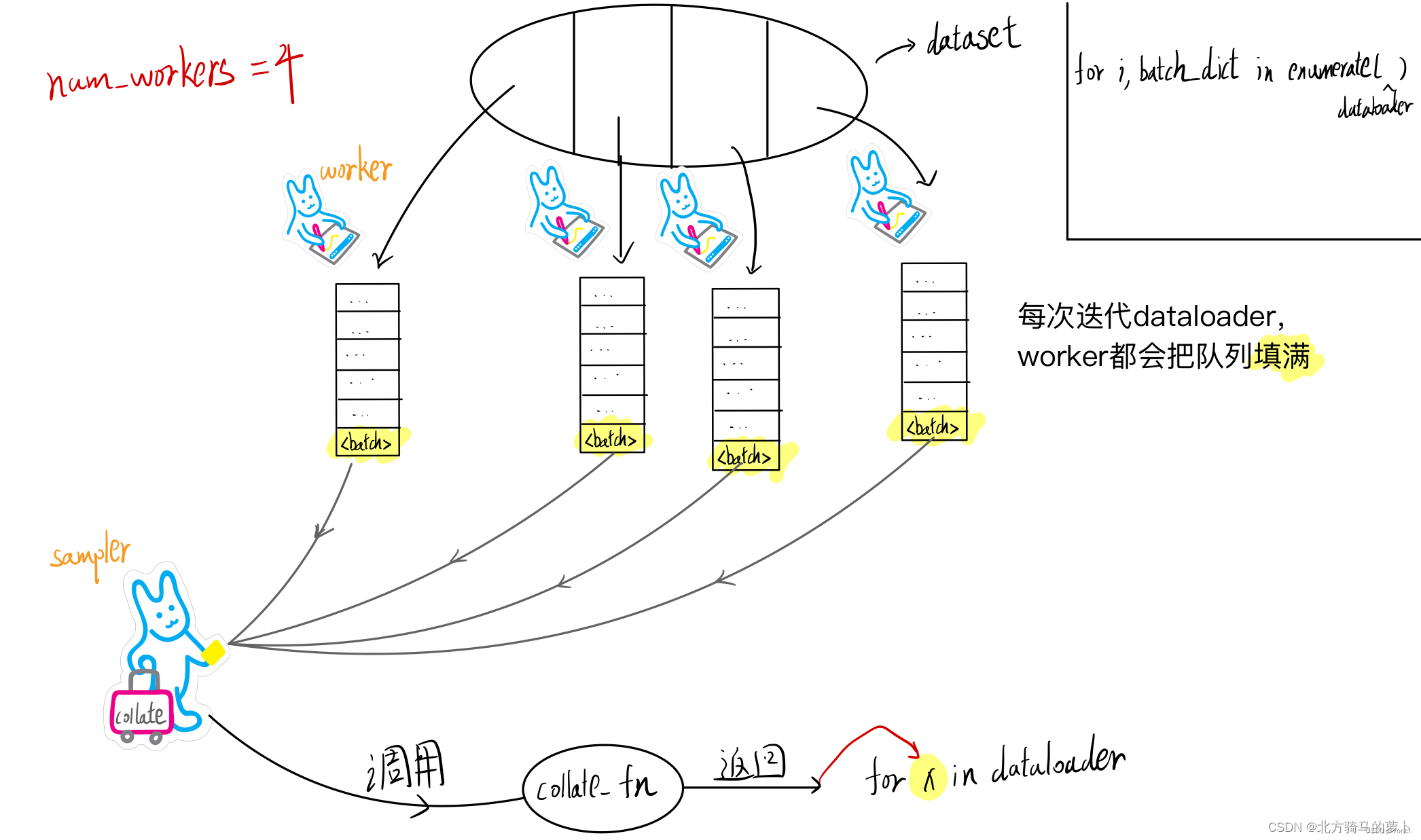
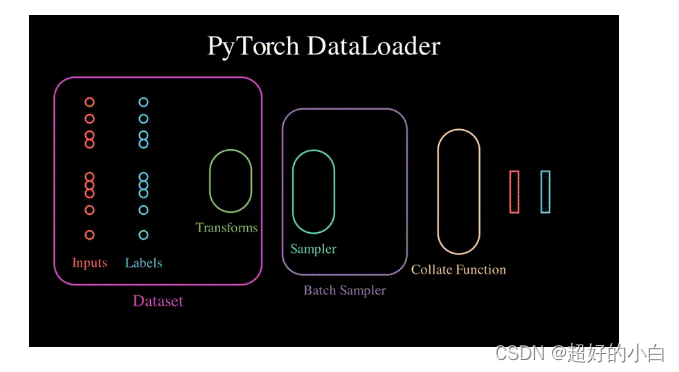
dataloader.dataset
是的,您可以直接访问 train_loader 的数据集来查看数据,而不必通过 enumerate 遍历数据加载器。可以通过 train_loader.dataset 属性来访问数据集,然后直接索引或查看数据集中的数据。
示例代码
以下是一个如何直接查看 train_loader 数据集数据的示例:
使用自定义数据集
import torch
from torch.utils.data import DataLoader, TensorDataset
# 生成一些示例数据
x_data = torch.randn(100, 10) # 100 个样本,每个样本有 10 个特征
y_data = torch.randn(100, 1) # 100 个样本,每个样本有 1 个标签
# 创建 TensorDataset 和 DataLoader
dataset = TensorDataset(x_data, y_data)
train_loader = DataLoader(dataset, batch_size=16, shuffle=True)
# 直接查看 train_loader 中的数据集
print(f'Total samples in dataset: {len(train_loader.dataset)}')
# 查看前 5 个样本
for i in range(5):
x, y = train_loader.dataset[i]
print(f'Sample {i+1}')
print(f'x: {x}')
print(f'y: {y}')
print()
使用 MNIST 数据集
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义数据转换
transform = transforms.Compose([transforms.ToTensor()])
# 下载并加载 MNIST 数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
# 直接查看 train_loader 中的数据集
print(f'Total samples in dataset: {len(train_loader.dataset)}')
# 查看前 5 个样本
for i in range(5):
x, y = train_loader.dataset[i]
print(f'Sample {i+1}')
print(f'x: {x.shape}') # x 是形状为 [1, 28, 28] 的图像张量
print(f'y: {y}') # y 是标签
print()
说明
- 自定义数据集:在第一个示例中,我们生成了随机数据并创建了一个
TensorDataset。然后,我们创建一个DataLoader并直接访问其数据集train_loader.dataset。我们打印了数据集的总样本数,并查看了前 5 个样本。 - MNIST 数据集:在第二个示例中,我们使用了 PyTorch 的
datasets.MNIST来下载和加载 MNIST 数据集。我们同样创建了一个DataLoader并直接访问其数据集train_loader.dataset。我们打印了数据集的总样本数,并查看了前 5 个样本。
通过这种方法,您可以直接访问并查看 train_loader 中的数据集,而不必遍历数据加载器。如果您有更多问题或需要进一步的帮助,请告诉我!
enumerate
在 PyTorch 中,DataLoader 对象通常用于加载训练和测试数据。要查看 train_loader 中的数据 x 和 y,您可以遍历 train_loader 并打印或检查数据。以下是一个示例,展示了如何查看 train_loader 中的数据:
示例代码
假设您已经有一个定义好的 train_loader,它加载了训练数据集:
import torch
from torch.utils.data import DataLoader, TensorDataset
# 生成一些示例数据
x_data = torch.randn(100, 10) # 100 个样本,每个样本有 10 个特征
y_data = torch.randn(100, 1) # 100 个样本,每个样本有 1 个标签
# 创建 TensorDataset 和 DataLoader
dataset = TensorDataset(x_data, y_data)
train_loader = DataLoader(dataset, batch_size=16, shuffle=True)
# 查看 train_loader 中的数据
for i, (x, y) in enumerate(train_loader):
print(f'Batch {i+1}')
print(f'x: {x}')
print(f'y: {y}')
print()
# 如果只想查看一个批次的数据,可以在这里 break
break
说明
- 生成数据:我们首先生成一些示例数据
x_data和y_data,每个样本有 10 个特征和 1 个标签。 - 创建数据集:我们使用
TensorDataset将x_data和y_data结合起来。 - 创建 DataLoader:我们创建一个
DataLoader对象train_loader,指定批次大小为 16,并启用数据打乱(shuffle)。 - 遍历 DataLoader:我们遍历
train_loader中的每个批次,并打印批次编号以及对应的x和y数据。
通过这种方法,您可以查看 train_loader 中的数据。如果您只想查看一个批次的数据,可以在第一个循环中加入 break。
使用 MNIST 数据集的例子
如果您使用的是像 MNIST 这样的标准数据集,代码会稍有不同:
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义数据转换
transform = transforms.Compose([transforms.ToTensor()])
# 下载并加载 MNIST 数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
# 查看 train_loader 中的数据
for i, (x, y) in enumerate(train_loader):
print(f'Batch {i+1}')
print(f'x: {x}') # x 是形状为 [batch_size, 1, 28, 28] 的图像张量
print(f'y: {y}') # y 是形状为 [batch_size] 的标签张量
print()
# 如果只想查看一个批次的数据,可以在这里 break
break
在这个例子中,x 是一个形状为 [batch_size, 1, 28, 28] 的图像张量,y 是一个形状为 [batch_size] 的标签张量。每个批次的数据会被打印出来。
通过上述方法,您可以方便地查看 train_loader 中的 x 和 y 数据。如果您有更多问题或需要进一步的帮助,请告诉我!